mondrian的个人总结
1. OLAP的作用和功能
OLAP(On-Line Analysis Processing)在线分析处理是一种共享多维信息的快速分析技术;OLAP利用多维数据库技术使用户从不同角度观察数据,它用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据复量的复杂查询的要求,并且以一种直观、易懂的形式呈现查询结果,辅助决策。
OLAP用了多维分析的技术。尽管关系型数据库所存储的所有数据都是以行和列的形式存在的,但一个多维数据库还是可以看做一个由轴(axes)和单元(cell)所组成的立方。借助这个立方,OLAP可以完成钻取、切片、切块、旋转等操作。所谓的钻取操作就是改变维的层次,变化分析的粒度。Drill-up是将低层次的数据概括到高层次的汇总数据或者说是减少维度;Drill-up则是相反,是将汇总的数据深入到细节,或说是增加新维。切片和切面操作是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。旋转操作即是变换维的方向,即在表格中重新安排维的放(例如行列互换)。
那么这个立方是以什么形式存储在关系数据库中的呢?它通常对应一个星型模型或者雪花模型。所谓的星型模型,它是由若干个事实表和若干个维表组成,事实表包括所有分析维度的外键和一个度量,维表对应于各个分析的角度,它除了主键以外还包含描述和分类信息。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。
2. Mondrian的选型依据
Mondrian是一个OLAP的服务引擎,而且是一个ROLAP引擎。它本身不管理数据的储存,这是由关系数据库来做的,它使用JDBC读取数据,因此,不管数据存储于普通关系数据库,或是数据集市、数据仓库,只要能用JDBC访问就可以。
Mondrian主要功能就是对数据量极大的数据表和相关联的多个维度表进行查询、汇总、轴变换以及上卷、下钻等操作,查询可以非常复杂,如果没有Mondrian引擎这是很难完成的。
Mondrian完成多维度的查询、汇总等相关操作是通过书写相应的MDX语句来完成的。MDX是多维数据库的查询语言,这已成为一个标准,就跟SQL是关系数据库的查询语言类似。然后,Mondrian会解析MDX语句,转化成SQL来查询关系数据库,这个查询可能是多条的。本质是mondrian就是一个解释器,将MDX语句解释为SQL语句来完成相关查询。
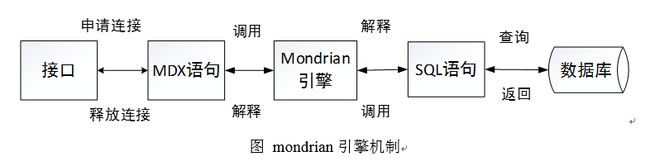
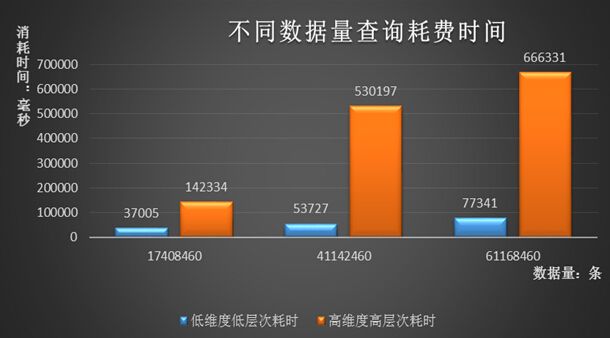
Mondrian的相关测试:
当数据量为1亿时,刷新立方所需花费的时间为33052.0毫秒。所谓的刷新是立方操作就是后台数据库中对表进行了相关增删改查操作,程序调用了刷新立方函数的过程。它会清除Mondrian缓存,重新刷新schem文件。此外,当数据量为一亿时,初次查询和刷新立方操作所产生的资源消耗数据如下:1.服务器CUP:占用比率大概150%;2.服务器端mysql 内存占用不是很大 3%;3.测试端程序(即客户端)占用内存大概61296K。其他mondrian相关的测试结果如下图所示。
3. Mondrian的整体架构
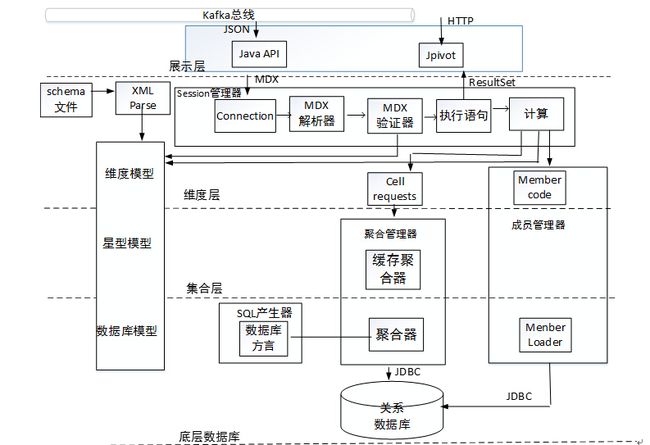
(1)表现层(thepresentation layer)
Jpivot表现层或者通过Java API进行查询结果的展示。
(2)维度层(thedimensional layer)
维度层用来解析、验证和执行MDX查询要求。一个MDX查询要通过几个阶段来完成:首先是计算坐标轴(axes),再者计算坐标轴axes中cell的值。
为了提高效率,维度层把要求查询的单元成批发送到集合层,查询转换器接受操作现有查询的请求,而不是对每个请求都建立一个MDX 声明。
(3)集合层(the starlayer)
集合层负责维护和创建集合缓存,一个集合是在内存中缓存一组单元值,这些单元值由一组维的值来确定。
维度层对这些单元发出查询请求,如果所查询的单元值不在缓存中,则集合管理器(aggregation manager)会向存储层发出查询请求。
(4)存储层(the storagelayer)
存储层是一个关系型数据库(RDBMS)。它负责创建集合的单元数据,和提供维表的成员。
Mondrian系统由四个层组成,从最终用户到数据中心,顺序为: 表现层(the presentation layer)、维度层(the dimensional layer)、集合层(the star layer)和存储层(the storage layer)。
4. 定义报文的JSON格式:
{
"consumption":"nts_sample",
"region": [
{
"province":"江苏",
"city":"南京",
"district":"玄武",
"building":"1号建筑",
"area":"1号区域"
},
{
"province":"湖南",
"city": "长沙",
"district":"雨花",
"building":"1号建筑",
"area":"1号区域"
}
],
"time": [
{
"year":"2015",
"quater":"1",
"month":"1",
"day":"2",
"hour":"0",
"minute":"0"
},
{
"year":"2015",
"quater":"2",
"month":"5",
"day":"2",
"hour":"0",
"minute":"0"
}
],
"category": [
{
"categorytype": "动力"
},
{
"categorytype": "照明"
}
],
"org": [
{
"group":"天溯",
"company":"研发中心",
"branch":"系统软件部",
"department":"企业组"
},
{
"group":"天溯",
"company":"研发中心",
"branch":"产品部",
"department": "UCD"
}
]
}
其中consumption表示能源的消耗值,value对应于事实表中的度量字段的取值;region对应于地区维度,它是一个一维数组,查询的地区可以是零到多个,地区下面存在省、市、地区、楼宇、区域这5个层次(level);time对应于时间维度,查询的时间可以是零到多个,也是一个一维数组,时间下面存在年、季度、月、日、时、分等层次;因为class是java的关键字,所以用category来表示设备的一维数组,查询的设备可以是零到多个,它下面存在设备类型这一层次;org表示单位的一维数组,查询的单位可以是零到多个,org下面存在组织、公司、部门、职位这几个层次。
5. 具体调用的方法
首先是解析报文的函数,此处采用了java的开源框架fastjson,fastjson是效率最高的json解析器和生成器,通过它可以方便的完成json与java对象之间的相互转换。
/**
* 解析报文函数
*
* @paramString jsonStr
* 接受的报文格式
* @returnEway
* 对数据仓库封装的一层数据结构
*/
publicstatic Eway parseJson(StringjsonStr) {
//反序列化操作
Ewayeway = JSON.parseObject(jsonStr, Eway.class);
//将接受的报文值存入封装好的数据结构之中
eway.setComsumption(eway.getComsumption());
eway.setRegion(eway.getRegion());
eway.setTime(eway.getTime());
return eway;
}
QueryExcute函数是对MDX查询语句的简单封装,用户无需关心细节的MDX语句,只需传入待查询的参数,后台程序以拼接字符串的形式,完成相关MDX语句的生成。
/**
* 多维数据库的查询函数
* @param measures
* 度量
* @param axis0
* 维度1
* @param axis1
* 维度2
* @return
* MDX执行语句
*/
public static StringQueryExcute(String measures, String axis0, String axis1) {
String Query ="select {[Measures].[" + measures + "]} ONCOLUMNS,{[region.default].[" + axis0 + "]} ON ROWS from [ntsdw] where[time.default].[" + axis1 + "]";
return Query;
}
PrintResult函数是完成的MDX查询,并打印输出结果集。它与JDBC类似。首先是通过Mondrian.OLAP包下的Connection对象获取连接,连接必须指明引擎的名称,连接数据库的名称及用户名和密码,对应的逻辑模型;然后调用connection的parseQuery方法来解析查询语句;最后将查询的结果保存到一个result对象之中,以流的形式在控制台打印输出。
/**
* 打印输出 多维数据库查询结果的函数
* 1.获取连接;
* 2.执行查询语句;
* 3.将查询的结果保存到result之中;
* 4.打印输出。
*/
@SuppressWarnings("deprecation")
public static voidPrintResult(){
Connection connection =DriverManager.getConnection("Provider=mondrian;Jdbc=jdbc:mysql://192.168.20.230/nts_eway_ee?user=root&password=iamnts;Catalog=E:/ntsdw.xml;",null);
String jsonStr ="{\"comsumption\":\"nts_sample\",\"region\":[{\"province\": \"江苏\"}],\"time\":[{\"year\": \"2015\"}]}";
Ewayeway=parseJson(jsonStr);
Stringmeasures=eway.getComsumption();
Stringaxis0=eway.getRegion().get(0).getProvince();
Stringaxis1=eway.getTime().get(0).getYear();
Query query =connection.parseQuery(QueryExcute(measures,axis0,axis1));
Result result =connection.execute(query);
PrintWriter pw = newPrintWriter(System.out);
result.print(pw);
pw.flush();
}