推荐系统(Recommender System)的技术基础
推荐系统是通过分析用户属性、访问日志、反馈信息等对用户可能感兴趣的项进行预测。推荐系统在web2.0时代将有非常广泛的应用。
推荐系统应用了多个领域的方法和技术,如人机对话(Human Computer Interaction)、信息检索(Information Retrieval)等。不过说到底,这些都是以数据挖掘(Data Mining)为基础的。
数据挖掘的过程由下图中所示的三个步骤组成:
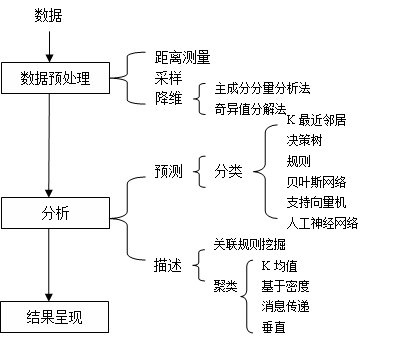
1.数据预处理(preprocessing)
数据挖掘的对象是数据,在对数据进行分析之前,要对数据进行清洗,转换、转载(ETL)使其完整、一致,在推荐系统中,数据的预处理主要包括距离计算,采样和降维。
(1)距离计算(Distance Measures)
推荐目前主要采用两种方法:基于内容的推荐和协同推荐。协同推荐的原理是寻找用户的邻居,为其推荐邻居感兴趣的东西。发现邻居的方法就是通过计算用户间的相似度对用户进行分类,相似度的基础就是距离计算。
常见的两个对象间距离的计算有如下几种方法:
1)欧几里得距离
定义如下:

其中,n为对象的属性的个数,xk、yk为第k个属性,x、y为对象。
2)闵可夫斯基距离是欧几里得距离的推广
定义如下:
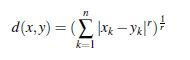
其中,r是距离的度,有时被称为Lr范数。另外,我们可以发现,当r=1时,它表示为曼哈顿距离,r=2时,表示为欧几里得距离,当r→∞时,表示为supremum距离,它对应于计算两个对象间任意维度的最大区别。
3)马氏距离
![]()
其中,σ是x、y的协方差矩阵。
此外,还有一种常见的计算对象间相似度的方法。将项看成n维的文档矩阵,通过计算两个对象间的cos值来表示相似度。公式如下:

其中•表示向量的点乘,||x||表示x的范数。
当对象的属性为二元变量时,即只有0,1两种状态。此时,就需要特定的方法来计算相似度。例如用M00、M01、M10、M11来表示具有两个二元变量的对象的四种状态,如果二元属性是对称的,也就是说两个状态具有相同的价值和相同的价值,那么对象间的相似度计算公式为:
简单匹配系数=(number of matched/number of attributes)=(M00+M11)/(M01+M01+M10+M11)
如果二元属性不是对称的,则计算公式为:
Jaccard系数=M11/(M01+M10+M11)
(2)采样(Sampling)
数据挖掘过程中,不可能对所有的数据进行处理,往往是选择一个子集作为数据源,从所有数据中选择数据子集的过程就是采样。选择出的子集还分为训练集(training dataset)和测试集( testing dataset),训练集主要用来学习算法,测试集用来测试算法质量。
采样要求选择出的数据具有代表性,目前主要采样以下两种方法:
1)随机取样 即等概率的从数据整体中抽取数据。
2)分层取样 基于数据的特征将数据分成几部分,在每一部分再进行随机取样。
在采样过程中,一种是不重复采样,另一种是重复采样。最常用的一种方法是80/20原则的不重复随机采样。80/20是指从采样结果中取80%作为训练集,另外20%作为测试集,这种方法在超过2/3情况下是适合的。
另外,为了防止采样结果不具有代表性,一般会重复取样,对数据经过多次测试来保证准确性。
(3)降维(Dimensionality Reduction)
采样得到的数据可能会有冗余、维难等问题,为了解决这些问题,就需要对数据进行降维。常用的降维方法有以下两种:
1)主成分分量分析法(Principal Compenent Analysis,PCA)
2)奇异值分解法(Singular Value Decomposit,SVD)
(未完,待续)