BD、人脸识别、KATA、Gray码--程序员杂志文摘
2013年 2月版:大数据:www.programmer.com.cn/14655/
2013年12月版:http://www.csdn.net/article/2013-11-26/2817621
(1):对2013年大数据技术的五个体会:没有连接
这个是01月的大数据预测:http://tech.it168.com/a2013/0109/1444/000001444933.shtml
预测1:企业大数据主动从Sandbox迁出,并定义一套明确的业务和技术需求
在2012年,企业在大数据上面的主动升级,超过了大多数人的预测。根据对世界上300个大企业的研究显示,数据量预计将在2013年增加约60%。13%的受访者表示他们对大数据的准备已经到位。另外有38%的公司有了实施计划。
企业正在形成专门的大数据团队,对很多人来说这在预算上已经成为一系列的项目,因为企业需要继续寻找更好的方法来管理、存储和分析他们持续增长的、必须保持在线的、可用于分析的数据据资产。我们将会看到更多明确定义的需求开始出现——无论是在业务方面还是在IT方面,如低成本的可扩展性、快速响应的查询和分析,以及充分利用现有的基于标准的工具(包括SQL和BI)的能力等。这是除了内置的安全性和数据可用性功能外,企业期待出现的功能。
预测2:公司在管理大数据时将寻求除了Hadoop以外新的技术组合
过去一年,Hadoop的势头越来越猛。Hadoop通过Web 2.0组织的推广,现在受到了银行、金融机构、电信运行商、大型零售商和其他企业的重视。然而,大数据的举措不仅集中在Hadoop平台。
业务和IT的挑战在于在不同的部门甚至于不同的公司之间组合使用各种不同的技术协调工作。企业部署私有云来管理数据财产与传统的数据库和数据仓库环境这两者的结合,以及在各种硬件上运行的Hadoop基础环境。所有企业大数据项目的一个共同的主题是渴望可以快速启动和运行而不会造成干扰到现有的IT环境。
预测3:预算限制是解决大数据挑战的最大障碍之一
大数据的支出正在上升,在未来一年,成本问题仍将是启动大数据项目时最大的一个障碍之一。根据最近的一项分析报告显示,大数据支出在2013年预计达到340亿美元。这些支出一方面是因为某些特殊行业组织由于行业的特殊性,必须保持数据在线和可用性;另一方面是由于企业想要利用来自多个源的数据的更多的信息,以进行更好的分析。这需要进行一个适当的平衡——在满足业务需求的同时,寻找最高效的技术基础设施——是一个挑战。
大数据的增长速度不会减慢。现有需求和未来需求的建设能力是至关重要的。太多太快不是要走的路,大数据并不一定意味着大笔的预算。
预测4:大数据工具必须同时满足业务和技术用户
在2013年,我们将看到大数据工具和应用程序的需求增长,它们将变得更容易使用,并且将同时满足业务和技术用户。如果你深入了解下Hadoop的基础技术能力,就会看到其在许多方面仍不成熟,需要独特的专业技能。我们已经看到了许多解决这方面的需求的新产品,包括Cloudera Impala和微软Polybase。事实上,今天已经存在的一些功能,使其更容易在正确的时间用最好的工具集访问正确的数据。
预测5:重量级厂商,如甲骨文和IBM,将会大数据市场进行收购
在过去一年,随着大数据市场的成熟,大型组织已经接受了大数据。我们预计,一些缺乏独特的技术能力或专业知识的厂商将会在2013年被收购。两个明显的重量级厂商是甲骨文和IBM——它们已经在数据管理领域构建了多样化的产品。但更应该看到,产品上市时间是企业获得更强大的立足点的关键。
(2):人脸识别这点事:Hello,人脸识别!
2013年15个最新科技RSS订阅源:
1、雷锋网:雷锋网是专注于移动互联网创新和创业的科技博客,客观敏锐地记录移动互联网的每一天。雷锋网由一群移动互联网的信徒建立,他们中有投资人,有观察者,有产品经理,有资深玩家,还有创业者。
http://www.leiphone.com/feed
2、互联网那些事:互联网那点事精心打造国内互联网产品信息门户站点。为产品策划和产品运营人士提供专业的产品资讯文档,以及产品设计、策划、运营、交互设计、用户体验、电子商务信息、互联网创业信息、移动互联网等专业信息服务。
http://feed.feedsky.com/alibuybuy
3、月光博客:月光博客,是一个专注于电脑技术、网站架设互联网、搜索引擎行业、Google Earth、Web 2.0等的原创IT科技博客。
http://feed.williamlong.info/
4、爱范儿:爱范儿是发现创新价值的科技媒体。 全景关注移动互联网,集中报道创业团队、最潮的智能手持及最酷的互联网应用,致力于“独立,前瞻,深入”的分析评论.
http://www.ifanr.com/feed
5、cnBeta:cnBeta.com提供最新最快的IT业界资讯,报导立场公正中立,.创造最适合目标人群阅读的新闻、评论、观点和专访。
http://www.cnbeta.com/backend.php
全文版RSS:http://pipes.yahoo.com/pipes/pipe.run?_id=5OVll5Fs3hGCc1KftJCjyQ&_render=rss
6、ITeye:ITeye资讯频道最新资讯,报道移动开发,WEB前端,企业构架,Java新闻,Ruby新闻,Python、Rails、PHP等编程开发技术资讯
http://www.iteye.com/rss/news
7、IT瘾资讯推荐:IT瘾推荐资讯,推荐关于互联网科技,手持设备,编程软件开发,信息技术,Google,Android等资讯
http://itindex.net/feed.jsp
8、36氪:关注互联网新媒体以及创业的科技博客,是中国领先的科技新媒体,报道最新的互联网科技新闻以及最有潜力的互联网创业企业。36氪的目标是,通过对互联网行业及最新创业企业的关注,为中文互联网读者提供一个最佳的了解互联网行业当下与未来的科技媒体。
http://www.36kr.com/feed/
9、Engadget 中国版:Engadget的中文站点,报道计算机硬件,数码/消费电子产品,科技新闻。
http://cn.engadget.com/rss.xml
10、PingWest:PingWest是一家提供关于硅谷与中国最前沿科技创业资讯、趋势与洞见的在线媒体,致力于成为沟通中国与美国这两个全球最大的互联网/移动市场的互联网社区。
http://feed.feedsky.com/pingwest
11、InfoQ:InfoQ是一个实践驱动的社区资讯站点,致力于促进软件开发领域知识与创新的传播。
http://www.infoq.com/cn/rss/rss.action?token=yV5lHoM3uVZTqXcuTdyeDFK4uzcE6XNQ
InfoQ全文版:http://pipes.yahoo.com/pipes/pipe.run?_id=10560380f804c7341f042a2b8a03e117&_render=rss
12、TechWeb:科技媒体,新媒体、新技术、新商业互动交流平台。
http://www.techweb.com.cn/rss/hotnews.xml
13、伯乐在线:伯乐在线-博客专注于分享职业相关的博客文章、业界资讯和职业相关的优秀工具和资源。
http://blog.jobbole.com/feed/
14、极客公园:发现产品价值,带来互联网热门趋势、热点产品的深度分析,发掘产品和趋势的价值
http://feeds.geekpark.net/
15、奇客Solidot:奇客的资讯,重要的东西
http://www.solidot.org/index.rss
(3): 通过KATA提升编程技能:http://www.csdn.net/article/2013-12-09/2817747-kata
Kata(路数练习)的思想就是通过反复练习来实践编码,在不断使用各种技能的过程中形成肌肉记忆。Kata从很多方面改善工作流程,比如编写测试、处理错误甚至编辑器的使用,更熟悉语言技巧。
有人做过一个实验,把几只猫养在暗室中,每天只有一小段时间开灯,有一个旋转装置,一组猫开灯时可以上去玩,而另一组却只通过一个洞看到完全相同的景象。实验结束时,后面一组猫都得了功能性失明。
这个结果使我大吃一惊。如果只有书本知识,那我也会是功能上的瞎子。只有大量编码才能从自发水平上真正获得知识。
第一次“路数练习”
Kata(路数练习)的思想就是通过反复练习来实践编码,在不断使用各种技能的过程中形成肌肉记忆。练过一些简单的程序之后,我想做点内容更充实的东西。于是想到了通过Kata实现“井子棋”。我的目标是在1小时内实现它。为此,我还用Screenflow来记录自己的进步。
我用自己熟悉的Ruby开发了第1版,测试框架用了不太熟悉的RSpec。
最开始我的时间大多花在测试环境的搭建上,每次走不下去就上网搜索。而到了第2版,进步就很明显了。第6遍,终于在1小时之内完成了游戏。
Kata从很多方面改善了我的工作流程,比如编写测试、处理错误甚至编辑器的使用。另外,熟能生巧,一些之前未想过的语言技巧也是在熟练中获得了。
用Kata学习新语言
如果换一门语言呢?我想试试Haskell。
第一步是读教程,我花了几天时间通读了《Learn You a Haskell》。这个时候,我应该就像那些只看不玩的猫,得跟语言交互才行。
我理解算法,也知道哪些过程要实现,于是唯一的障碍是语言。此时,Kata提供了一种可控的环境,使我能够专注;而视频记录则提供了一种方式,使我能反思遇到的问题。
测试环境搭好之后,语法成了主要问题。每次写点东西就出错,总要追到最简单的形式才正确。一个小时只完成一个构造函数。我现在坚持每次Kata一小时,不论完成与否。理论上,每次我至少可以走到跟上次一样的地方。
初学新语言时,会担心一不留神学到的知识就溜走。第2遍Kata时,我的这种感觉就没有了。到第3遍时,效率大大提升,不再犹豫、搜索,犯的错误也跟之前不同了。到第10遍时,终于又在1小时内实现“井子棋”!
作者Chong Kim,本文作者是一位热爱编程、数学和棋类游戏的软件工匠。拥有15个GitHub软件仓库,主要基于Ruby、Clojure和JavaScript。
(4):Gray码及其应用:http://www.csdn.net/article/2013-12-18/2817634-Gray VS 汉明距离!
控制台上有四个开关和一个按钮,每个开关都可以扳到ON和OFF中的一个,只有当四个开关的ON/OFF状态处于某个唯一的正确组合时,按动按钮之后才能打开密室的大门。为了以最快的速度逃脱密室,你打算怎么办?
一个游戏引发的思考
几年前,我玩过一个第三人称冒险游戏,游戏的名字已经不记得了,唯一印象深刻的就是上面这个场景。为了避免自己忘记哪些组合已经试过,我们只需要按照某种规律逐一尝试所有的组合就行了。比方说,用数字0来表示OFF状态,用数字1来表示ON状态,然后按照二进制数的规律依次尝试2⁴=16种不同的组合:0000, 0001, 0010, 0011, 0100, …, 1110, 1111。其中,从0000到0001需要扳动一次开关,从0001到0010需要扳动两次开关……最恐怖的是,从0111到1000需要扳动全部四个开关。在最坏情况下,最后试到的那个组合才是正确的组合,那么整个过程下来,我们一共要扳动26次开关!更要命的是,在游戏中,扳动一次开关非常费劲,你需要持续按住某个按键很长时间才行。
于是,一个有意思的问题出现了:换一种尝试的顺序,能让我们少扳动几次开关吗?最少需要扳动几次开关呢?
容易看出,由于我们一共要试16种不同的组合,因此整个过程至少要扳动15次开关。会不会扳动15次开关就足够了呢?这意味着,每两个相邻的组合之间都只相差一个开关的位置。如此理想的解是否真的存在,这我不太清楚;但我当时立即想到,如果要试遍三个开关的所有2³=8种组合,只扳动7次开关确实是可以办到的。这相当于沿着立方体的棱既无重复又无遗漏地经过每一个顶点。其中一种方案如图1所示,它所对应的试验顺序如下。
000 → 001 → 011 → 010 → 110 → 111 → 101 → 100
图1 把8个三位01串看作立方体的8个顶点,两个01串之间有一条棱当且仅当它们只相差一位
当时我的想法很简单:既然知道怎样快速遍历三个开关的所有组合,那就干脆让第一个开关保持OFF状态,把所有形如0???的组合都先试一遍吧:
0000 → 0001 → 0011 → 0010 → 0110 → 0111 → 0101 → 0100
接下来呢?我的想法是,把第一位扳成1,然后像刚才那样再遍历一次后三位的组合吧。把0100变成1000需要扳动2次开关,再把后三位的组合全试一遍又需要7次开关,最后一共扳动了16次开关,嗯,已经很不错了。但是,刚扳完第一个开关,把0100变成了1100后,本想继续把后三位还原成000的,却突然一下意识到:1100本来就是一个新的组合呀。干脆先把这个组合试了再说。
0100 → 1100
紧接着,就像有人用一根大棒把我敲醒了一样,我猛然意识到:然后就从1100出发,逆着刚才的顺序遍历后三位的所有组合,最后回到1000不就行了吗?
1100 → 1101 → 1111 → 1110 → 1010 → 1011 → 1001 → 1000
这样,我们就实现了扳动15次开关既无重复又无遗漏地遍历四个开关的所有16种组合,每扳动一次开关得到的正好都是一种新的组合!
利用类似的方式,我们可以继续扩展,把32个五位01串也排成一列,使得每个01串到下个01串都只需要变动一位。当然,刚才那8个三位01串的排列顺序,本身也可以看作是由更基本的情况扩展而来的。事实上,我们可以像表1那样,从一位01串这种最最基本的情况出发,不断通过“镜像”和“添首位”的方法,最终得到把2ⁿ个n位01串排成一列的方案,使得相邻两个01串总是只差一位。
表1 生成镜像二进制编码的方法
我们姑且给它起个名字,叫做“镜像二进制编码”吧。
PCM信号转换器的故事
人们刚开始实现数字通信的时候,曾经为如何把模拟信号转化为数字信号而伤透脑筋。1937年,英国科学家Alec Reeves发明了一种将模拟信号进行数字化的方法,即我们现在所说的脉冲编码调制(pulse-code modulation,缩写成PCM或许大家会更熟悉一些)。假设我们有一段声音,它的波形图如图2所示。那么,我们就间隔相等地在时间轴上取一些点,看看此时波形图的高度在什么位置,并用二进制数来表示。如果使用五位二进制数的话,那么每个采样结果都有32种不同的取值,可以与十进制中的0到31相对应。对于普通的人声来说,为了充分刻画出波的形状,理论上每秒至少需要采样8000次才行;采样频率越高,还原真实声音的效果也就越好。
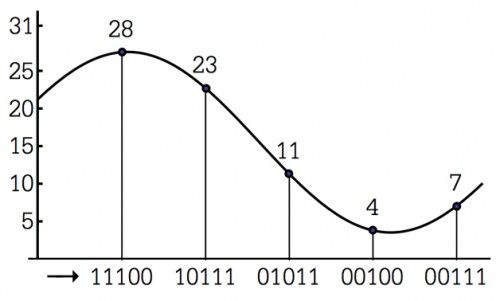
图2 脉冲编码调制示意图
这种编码方式确实不错,关键是,如何设计一种信号转换器,让它能自动地按照这种方式把模拟信号转换成数字信号?总不能雇几个员工去人肉完成每秒上千次的采样和转换吧。
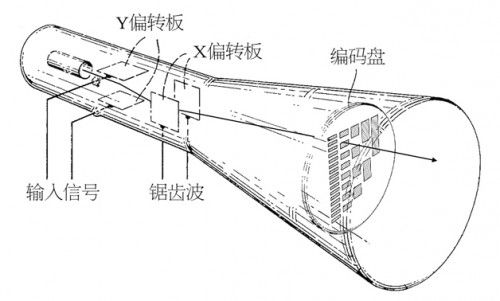
图3 用阴极射线管制作一个信号转换器
人们巧妙地用阴极射线管和X、Y两组偏转板解决了这个问题。如图3所示,电子枪射出的电子束首先从两块Y偏转板之间穿过,并且受到Y偏转板所产生的电场的影响而上下偏转,其偏转幅度由输入电信号决定;偏转后的电子束继续从两块X偏转板之间穿过,并受其产生的电场影响而左右偏转。X偏转板上的电位差由某个锯齿波发生器决定,其效果就是让电子束不断地从左至右扫描。在电子束到达电子收集屏之前,还必须经过一个上面有穿孔的“编码盘”。如果我们想要把每一个采样值都转化成五位01串的话,那么编码盘上的孔应该如图4所示。把所有的东西结合起来,电子束便能根据输入信号在不同的高度处从左往右扫描,每扫描一次都会产生一个五位01串,其中1意味着电子束穿过了编码盘上的孔,0意味着电子束被编码盘挡住了。如果电子束在r₁所示的高度处扫描一次,得到的五位01串就是01101,或者说十进制的13。
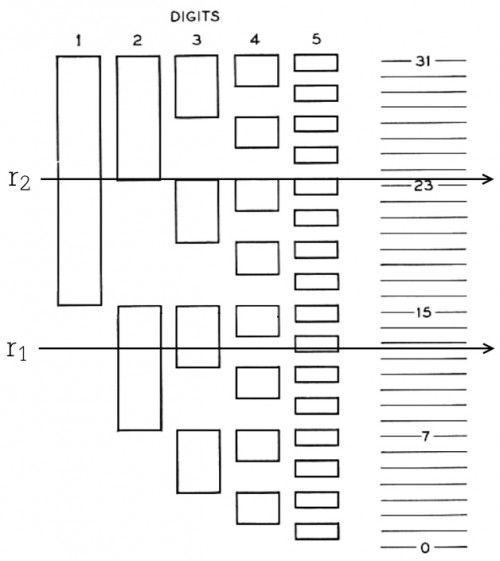
这种信号转换器的原理的确巧妙,但理论与实际之间还是有一定距离的。在实际应用时,我们会遇到一个有些意想不到的问题。让我们假设,某个采样值正好是23.5,于是电子束会在图4的r₂高度处从左往右扫描一次。注意,这条扫描线经过了四个孔的边界,于是完全有可能出现这样的误差:电子束穿过了第二位对应的孔,同时也穿过了第三位、第四位和第五位所对应的孔。于是,这个值最后就被编码为了11111。或者,电子束完全错过了后面四个位置上的孔,于是这个值就被编码为了10000。在最坏情况下,我们甚至会把15.5编码为11111或者00000,这是不能容忍的错误。怎么办呢?
1947年,贝尔实验室的Frank Gray提交了一项专利,漂亮地解决了这个问题。Frank Gray的方法非常简单:把传统二进制编码改为镜像二进制编码!新的编码盘如图5所示。我们用五位镜像二进制编码中的第一项,即00000,来表示最小的高度值,或者说十进制的0;用镜像二进制编码中的下一项,即00001,来表示次小的高度值,或者说十进制的1;类似地,用00011表示2,用00010表示3,用00110表示4,以此类推,一直到用10000表示31。这样,任意两个相邻高度所对应的数字编码都只有一位的差异,换句话说恰好从它们中间穿过去的扫描线只会遇到一处边界。如果扫描线的高度恰好是15.5,则转换后的结果要么就是01000(它代表15),要么就是11000(它代表16),刚才的误差问题就解决了。
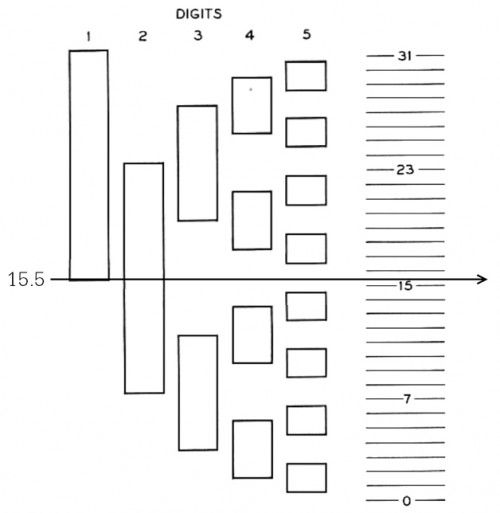
Frank Gray在专利文件中说,这种新的编码方式还没有一个名字,并且首次提出了“镜像二进制编码”(reflected binary code)这个名字。后来,人们逐渐开始用“Gray码”来指代这种编码方式,“Gray码”这个名字也就慢慢固定了下来。
Gray码的其他应用
在工业上,Gray码还有很多应用。假如有一个温度(或水位、气压、比分等)检测系统,当它探测到数值从7变到8时,系统便会把0111改成1000。万一在改动的过程当中正好出现了读取操作,此时读到的数据就是错误的。采用Gray码的话,数值的加1和减1操作将会成为真正的原子操作,这个问题也就能避免了。
有趣的是,n位Gray码的第一个01串和最后一个01串之间也只差一位。因此,如果把n位Gray码看作是循环的,任意两个相邻的01串仍然满足要求。有些方向传感器会使用Gray码来表示方向,便是用到了Gray码的这个性质。例如,不妨用000, 001, 011, 010, 110, 111, 101, 100依次表示八个方向,那么不管是从哪个方向转到哪个相邻的方向,所对应的01串都只变了一位,这样也就不会产生错误的“中间数值”了。
作者顾森,网名Matrix67,数学爱好者。2005年开办数学博客www.matrix67.com,至今已积累上千篇文章,有上万人订阅。新书《思考的乐趣》已在图灵公司出版。