MongoDB集群——副本集
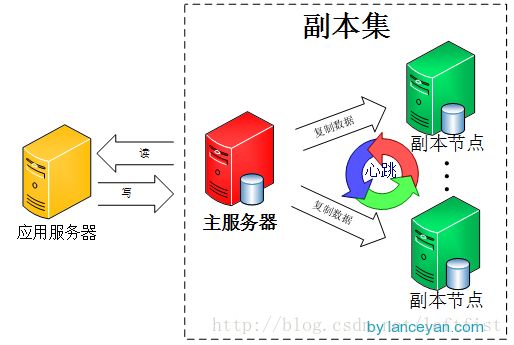
主节点负责处理客户端请求,读、写数据, 记录在其上所有操作的oplog;
从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。默认情况下,从节点不支持外部读取,但可以设置;
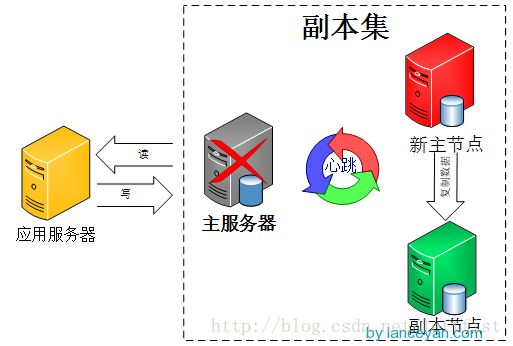
副本集的机制在于主节点出现故障的时候,余下的节点会选举出一个新的主节点,从而保证系统可以正常运行。
仲裁节点不复制数据,仅参与投票。由于它没有访问的压力,比较空闲,因此不容易出故障。由于副本集出现故障的时候,存活的节点必须大于副本集节点总数的一半,否则无法选举主节点,或者主节点会自动降级为从节点,整个副本集变为只读。因此,增加一个不容易出故障的仲裁节点,可以增加有效选票,降低整个副本集不可用的风险。仲裁节点可多于一个。
2、 搭建副本集
1) 使用同一副本集名称启动所有节点实例
示例:
mongod --port 40000 --dbpath rs0\data\ --logpath rs0\log\rs0.log --replSet myset
mongod --port 40001 --dbpath rs1\data\ --logpath rs1\log\rs1.log --replSet myset
……
2) 在任意节点进行副本集初始化
示例:
mongo jsj-1306-201:40000
>use admin
> config={_id:"myset",members:[
{_id:0,host:"jsj-1306-201:40000","priority":2},
{_id:1,host:"jsj-1306-201:40001"},
{_id:2,host:"jsj-1306-201:40002",arbiterOnly:true}
]}
>rs.initiate(config);
3) 查阅副本集
>rs.conf()
或者
>rs.status()
4) 增添节点
添加节点,需要在主节点进行
PRIMARY>>rs.add(hostname:port)
5) 删减节点
删减节点,需要在主节点进行
PRIMARY>rs.remove(hostname:port)
3、 测试副本集
1) 测试数据复制
首先在主节点插入记录
myset:PRIMARY> use test
switched to db test
myset:PRIMARY> for(var i=1;i<=1000;i++) db.table1.save({id:i,"test1":"testval1"}
);
然后连接某一从节点,读取该节点上的数据:
myset:SECONDARY> use test
switched to db test
myset:SECONDARY> db.table1.find().count()
可知数据同步成功
2) 测试故障切换
在任意一节点,观察副本集情况:
>rs.status()
然后关闭另一节点,再观察
>rs.status()
只要余下的节点超过总数的一半,那么副本集可以自动进行故障切换:
如果关闭的是主节点,那么副本集选出新的主节点;如果关闭的是从节点,那么主节点仍然保持运行。
如果余下节点小于或等于总节点数的一半,则不管关闭的是不是主节点,副本集中都不再存在主节点,原来的主节点会降级成为从节点!此时整个副本集呈现只读状态。
4、 节点数量
副本集至少需要两个节点,至多12个节点。其中一个是主节点,其余的都是从节点和仲裁节点。具备投票权的节点至多为7个。从节点越多,复制的压力就越大,备份太多反而增加了网络负载和拖慢了集群性能。
MongoDB官方推荐节点数量为奇数。主要在于副本集常常为分布式,可能位于不同的IDC。如果为偶数,可能出现每个IDC的节点数一样,从而如果网络故障,那么每个IDC里的节点都无法选出主节点,导致全部不可用的情况。比如,节点数为4,分处于2个IDC,现在IDC之间的网络出现故障,每个IDC里的节点都没有大于2,所以副本集没有主节点,变成只读。
5、 从节点的类型
Secondary:标准从节点,可复制,可投票,可被选为主节点
Secondary-Only:不能成为主节点,只能作为从节点,防止一些性能不高的节点成为主节点。设置方法是将其priority = 0
Hidden:这类节点是不能够被客户端制定IP引用,也不能被设置为主节点,但是可以投票,一般用于备份数据。
Delayed:可以指定一个时间延迟从primary节点同步数据。主要用于备份数据,如果实时同步,误删除数据马上同步到从节点,恢复又恢复不了。
示例:
cfg= {
"_id" : <num>,
"host" : <hostname:port>,
"priority" : 0,
"slaveDelay" : <seconds>,
"hidden" : true
}
rs.initiate(cfg);
Non-Voting:没有选举权的secondary节点,纯粹的备份数据节点。设置方法是将其votes = 0。之所以设置这种节点,是照顾副本集最多12个节点,但有投票权的节点最多7个节点的要求。
示例:
PRIMARY>cfg = rs.conf()
PRIMARY>cfg.members[3].votes = 0
PRIMARY>cfg.members[4].votes = 0
PRIMARY>cfg.members[5].votes = 0
PRIMARY>rs.reconfig(cfg)
6、 读写分离
从节点默认情况下不能读取,但可以设置此选项:
SECONDARY> db.getMongo().setSlaveOk();
这样,读取部分可以使用这些开启了读取选项的从节点,从而减轻主节点的负荷。
至于写入,永远只有主节点才可以进行。
7、 最终一致性
数据的写入在主节点进行,将操作记录进日志oplog,从节点定期轮询主节点,获取oplog,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致,因此有一定时间的滞后是必然的,MongoDB追求的是最终一致性。
既然“滞后”不可避免,需要做的就是尽可能减小这种滞后,主要涉及到以下几点:
网络延迟:这是所有分布式系统都存在的问题。我们能做的就是尽可能减小副本集节点之间的网络延迟。
磁盘吞吐量:secondary节点上数据刷入磁盘的速度比primary节点上慢的话会导致secondary节点很难跟上primary节点的节奏。
并发:并发大的情况下,primary节点上的一些耗时操作会阻塞secondary节点的复制操作,导致复制操作跟不上主节点的写入负荷。解决方法是通过设置操作的write concern(参看这里:http://docs.mongodb.org/manual/core/write-concern/#replica-set-write-concern)默认的副本集中写入操作只关心primary节点,但是可以指定写入操作同时传播到其他secondary节点,代价就是严重影响集群的并发性。
注意:而且这里还存在一个问题如果,如果写入操作关心的某个节点宕机了,那么操作将会一直被阻塞直到节点恢复。
适当的write concern:我们为了提高集群写操作的吞吐量经常会将writer concern设置为unacknowledged write concern,这导致primary节点的写操作很快而secondary节点复制操作跟不上。解决方法和第三点是类似的就是在性能和一致性之间做权衡。
8、 副本集不可用的应对之道
当节点发生故障,或者因为网络原因失联,造成余下的节点小于等于副本集总节点数的一半,那么整个副本集中都不再存在主节点,原来的主节点会降级成为从节点!此时整个副本集呈现只读状态,也即不再可用。
当出现这种瘫痪情况,目前我还没找到将某个从节点切换为主节点的方法,也许本来就不存在这种方法。因为这和MongoDB的Primary选举策略有关:如果情况不是Secondary宕机,而是网络断开,那么可能出现位于不同IDC的节点各自选取自己为Primary。这样在网络恢复后就需要处理复杂的一致性问题。而且断开的时间越长,时间越复杂。所以MongoDB选择的策略是如果集群中存活节点数量不够,则不选取Primary。
所以
1) 一方面要极力避免出现这种存活节点不够半数的情况,在规划副本集的时候就注意:
设置仲裁节点。
节点总数为奇数,且主节点所在的IDC,拥有超过半数的节点数量
2) 注意对节点的备份,必要时可以对节点进行恢复
也可以按照相同配置建立一个全新的从节点,恢复副本集后,系统会自动同步数据。但猜测数据量比较大的情况下,耗时会比较长,所以平时对从节点进行备份,还是有必要。