近期Redis集群服务出现不稳定的情况,请求的总体RT波动性很大,出现请求失败的情况。
表现症状
- p99的请求RT耗时问题时段大幅变长
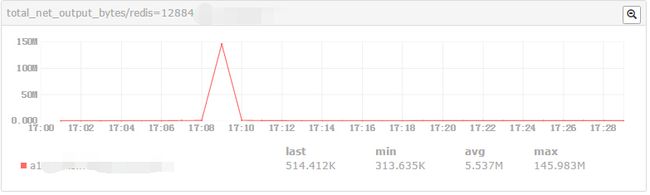
- 个别Redis实例的total_net_output_bytes飚高【100+Mbytes】
- 个别Redis实例的cmdstats_cluster命令执行的次数飙高
- 个别Redis实例CPU使用率飚高
total_net_output_bytes飚高
Cluster命令次数飙高
事故现场
首先要搞明白到底谁在发送cluster指令,tcpflow官方版本抓包数据不带时间戳,这点非常不爽,问题很难被追溯,很庆幸在github上找到一个支持时间戳的tcpflow,https://github.com/mukhin/tcpflow。
tcpflow -cp -x -i eth0 -cp dst port 12884 |grep --line-buffered -i -C2 'cluster' > tcpflow.12884.2016-10-07-11.log 2>&1
抓包数据
2016-10-08 17:08:50 010.192.192.186.64292-010.192.192.192.12884: *2
2016-10-08 17:08:50 $7
2016-10-08 17:08:50 CLUSTER
2016-10-08 17:08:50 $5
2016-10-08 17:08:50 slots
2016-10-08 17:08:50 $7
2016-10-08 17:08:50 CLUSTER
2016-10-08 17:08:50 $5
2016-10-08 17:08:50 slots
发送的来源
99 010.192.192.090
87 010.192.192.181
78 010.192.192.108
68 010.192.192.121
65 010.192.192.024
64 010.192.192.063
62 010.192.192.089
61 010.192.192.124
60 010.192.192.192
57 010.192.192.164
56 010.192.192.064
52 010.192.192.161
50 010.192.192.127
48 010.192.192.123
46 010.192.192.118
45 010.192.192.065
43 010.192.192.122
42 010.192.192.125
39 010.192.192.120
39 010.192.192.192
36 010.192.192.119
35 010.192.192.126
33 010.192.192.109
17 010.192.192.163
15 010.192.192.162
1 010.192.192.066
87 010.192.192.181
78 010.192.192.108
68 010.192.192.121
65 010.192.192.024
64 010.192.192.063
62 010.192.192.089
61 010.192.192.124
60 010.192.192.192
57 010.192.192.164
56 010.192.192.064
52 010.192.192.161
50 010.192.192.127
48 010.192.192.123
46 010.192.192.118
45 010.192.192.065
43 010.192.192.122
42 010.192.192.125
39 010.192.192.120
39 010.192.192.192
36 010.192.192.119
35 010.192.192.126
33 010.192.192.109
17 010.192.192.163
15 010.192.192.162
1 010.192.192.066
发送的频率
266 17:08:51
204 17:08:53
193 17:08:52
120 17:08:54
98 17:08:50
93 17:08:56
92 17:08:55
82 17:08:59
80 17:08:57
70 17:08:58
204 17:08:53
193 17:08:52
120 17:08:54
98 17:08:50
93 17:08:56
92 17:08:55
82 17:08:59
80 17:08:57
70 17:08:58
根据ip很容易判断出这些命令是Jedis客户端发送,1秒执行了266次,行成了cluster slots风暴,由于频繁执行cluster slots,而且输出的内容体积很大,这就可以解释Redis实例输出内容变多的原因。
分析jedis客户端
目前使用的是jedis比较老的一个版本2.7.0,jedis运行过程中当出现网络波动会导致请求随机节点,然后随机节点会返回Moved指令,这时会导致大量客户端更新slot【JedisClusterConnectionHandler.renewSlotCache()】的请求,由于选择Redis Server时没有做Shuffled会导致所有的cluster slots请求发给同一个Redis Server,Cluster slots会让这个Redis会出现严重的热点问题,进而影响到集群的吞吐以及稳定。
private T runWithRetries(String key, int redirections, boolean tryRandomNode, boolean asking) {
if (redirections <= 0) {
throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?");
}
Jedis connection = null;
try {
if (asking) {
// TODO: Pipeline asking with the original command to make it
// faster....
connection = askConnection.get();
connection.asking();
// if asking success, reset asking flag
asking = false;
} else {
if (tryRandomNode) {
connection = connectionHandler.getConnection();
} else {
connection = connectionHandler.getConnectionFromSlot(JedisClusterCRC16.getSlot(key));
}
}
return execute(connection);
} catch (JedisConnectionException jce) {
if (tryRandomNode) {
// maybe all connection is down
throw jce;
}
releaseConnection(connection, true);
connection = null;
// retry with random connection
return runWithRetries(key, redirections - 1, true, asking);
} catch (JedisRedirectionException jre) {
if (jre instanceof JedisAskDataException) {
asking = true;
askConnection.set(this.connectionHandler.getConnectionFromNode(jre.getTargetNode()));
} else if (jre instanceof JedisMovedDataException) {
// it rebuilds cluster's slot cache
// recommended by Redis cluster specification
this.connectionHandler.renewSlotCache();
} else {
throw new JedisClusterException(jre);
}
releaseConnection(connection, false);
connection = null;
return runWithRetries(key, redirections - 1, false, asking);
} finally {
releaseConnection(connection, false);
}
}
public void renewSlotCache() { for (JedisPool jp : cache.getNodes().values()) { Jedis jedis = null; try { jedis = jp.getResource(); cache.discoverClusterSlots(jedis); break; } finally { if (jedis != null) { jedis.close(); } } } }
处理方案
Jedis 2.8.0版本renewSlotCache时增加了Shuffled,使得cluster slots请求尽可能打散至更多Redis Server上。
https://github.com/xetorthio/jedis/pull/1090