项目开发中遇到的一些有用类或方法的总结
本篇博客将一直更新!
总结1:将一个字符串数组存放到一个list集合当中。
运行结果:
4
Hadoop总结2:判断数据的类型并进行类型的转换。
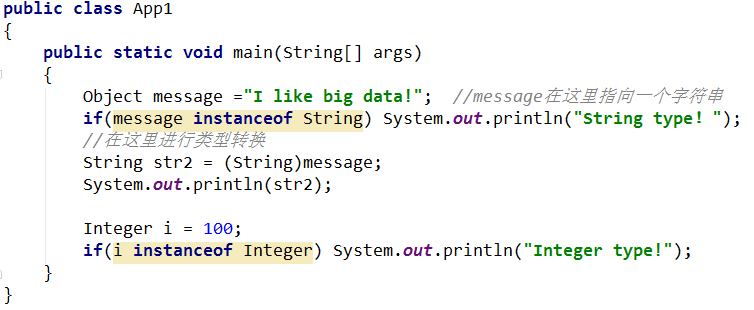
运行结果:
String type!
I like big data!
Integer type!总结3:字符串对应分词器的使用。

运行结果:
Spark
Hbase
Hive
Hadoop
589
Scala总结4:单词计数或者多数投票常用的Javabean->wordcount.

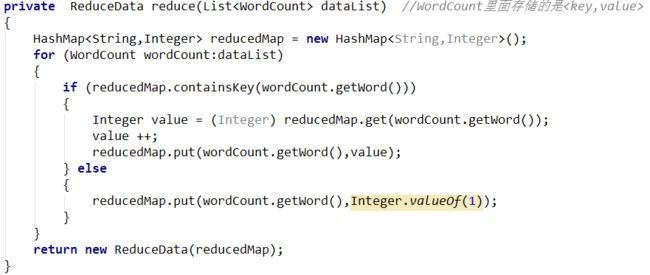
总结5:单词计数或者多数投票常用的Javabean->reduce.
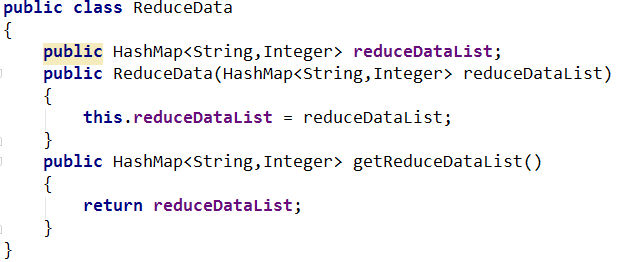
总结6:单词计数或者多数投票常用的Javabean->ReduceData
总结7:单词计数或者多数投票常用的Javabean->统计

总结8:Scala中的toList方法与flatMap方法进行结合:将字符串集合转化成字符集合

运行结果:
List(List(0, 0, 0, 0, 0, 1), List(0, 0, 0, 0, 1, 0), List(0, 0, 0, 0, 1, 1))
List(0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1)总结10:Intellent IDE当中常用的快捷键

总结11:List中常用的3个分区操作
总结12:集合中资源的初始化工作:List伴生对象中的make方法
总结13:scala中的foreach除了输出还可以干别是事情的例子
总结14:通过Hadoop的Api–FileSystem阅读HDFS中文件的内容
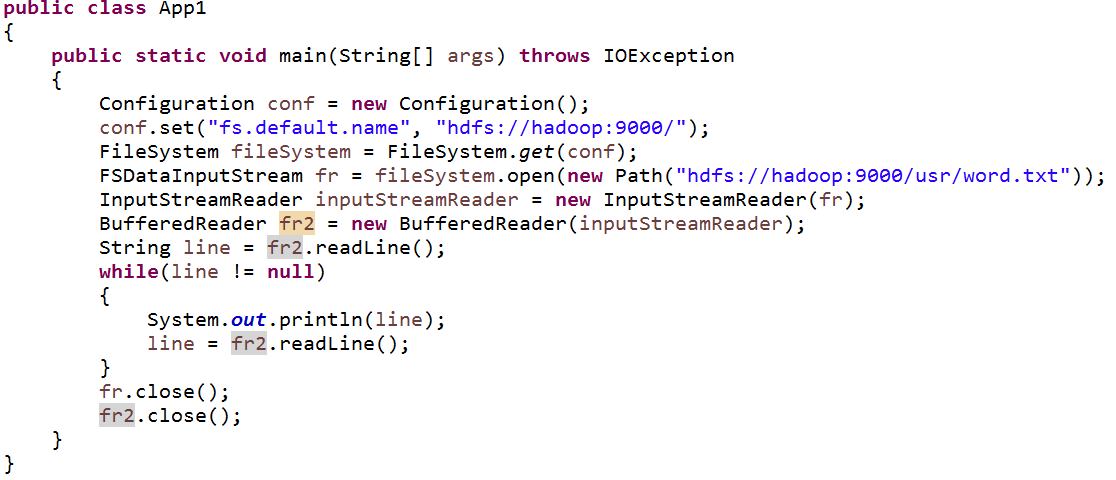
运行结果:
hadoop and spark
java and scala总结15:Hbase中key的值实际上是{行健、列族、列名、时间戳}的集合,而不仅仅指的是rowkey
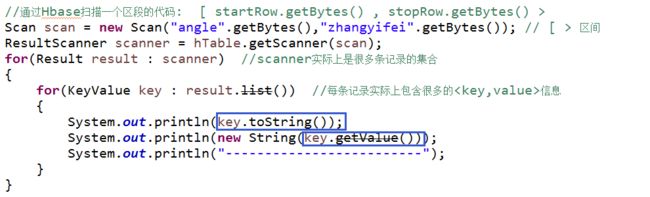
总结16:通过Java api扫描Hbase中某一个区域的数据(我联想到了Hash算法中近邻的桶!)