Flume+Spark+Hive+Spark SQL离线分析系统
前段时间把Scala和Spark一起学习了,所以借此机会在这里做个总结,顺便和大家一起分享一下目前最火的分布式计算技术Spark!当然Spark不光是可以做离线计算,还提供了许多功能强大的组件,比如说,Spark Streaming 组件做实时计算,和Kafka等消息系统也有很好的兼容性;Spark Sql,可以让用户通过标准SQL语句操作从不同的数据源中过来的结构化数据;还提供了种类丰富的MLlib库方便用户做机器学习等等。Spark是由Scala语言编写而成的,Scala是运行在JVM上的面向函数的编程语言,它的学习过程简直反人类,可读性就我个人来看,也不是能广为让大众接受的语言,但是它功能强大,熟练后能极大提高开发速度,对于实现同样的功能,所需要写的代码量比Java少得多得多,这都得益于Scala的语言特性。本文借鉴作者之前写的另一篇关于Hadoop离线计算的文章,继续使用那篇文章中点击流分析的案例,只不过MapReduce部分改为由Spark离线计算来完成,同时,你会发现做一模一样的日志清洗任务,相比上一篇文章,代码总数少了非常非常多,这都是Scala语言的功劳。本篇文章在Flume部分的内容和之前的Hadoop离线分析文章的内容基本一致,Hive部分新加了对Hive数据仓库的简单说明,同时还补充了对HDFS的说明和配置,并且新加了大量对Spark框架的详细介绍,文章的最后一如既往地添加了Troubleshooting段落,和大家分享作者在部署时遇到的各种问题,读者们可以有选择性的阅读。
PS:本文Spark说明部分的最后一段非常重要,作者总结了Spark在集群环境下不得忽略的一些特性,所有使用Spark的用户都应该要重点理解。或者读者们可以直接阅读官方文档加深理解: http://spark.apache.org/docs/latest/programming-guide.html
Spark离线分析系统架构图
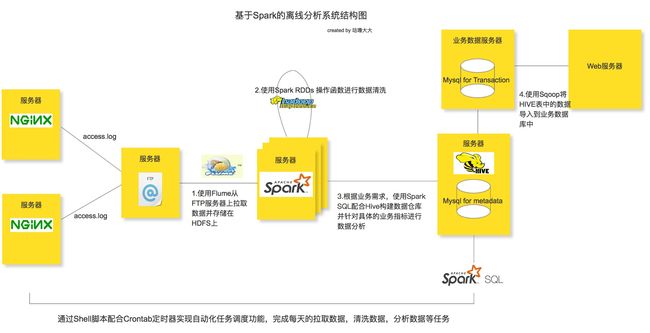
整个离线分析的总体架构就是使用Flume从FTP服务器上采集日志文件,并存储在Hadoop HDFS文件系统上,再接着用Spark的RDDs操作函数清洗日志文件,最后使用Spark SQL配合HIVE构建数据仓库做离线分析。任务的调度使用Shell脚本完成,当然大家也可以尝试一些自动化的任务调度工具,比如说AZKABAN或者OOZIE等。
分析所使用的点击流日志文件主要来自Nginx的access.log日志文件,需要注意的是在这里并不是用Flume直接去生产环境上拉取nginx的日志文件,而是多设置了一层FTP服务器来缓冲所有的日志文件,然后再用Flume监听FTP服务器上指定的目录并拉取目录里的日志文件到HDFS服务器上(具体原因下面分析)。从生产环境推送日志文件到FTP服务器的操作可以通过Shell脚本配合Crontab定时器来实现。
网站点击流数据

图片来源: http://webdataanalysis.net/data-collection-and-preprocessing/weblog-to-clickstream/#comments
一般在WEB系统中,用户对站点的页面的访问浏览,点击行为等一系列的数据都会记录在日志中,每一条日志记录就代表着上图中的一个数据点;而点击流数据关注的就是所有这些点连起来后的一个完整的网站浏览行为记录,可以认为是一个用户对网站的浏览session。比如说用户从哪一个外站进入到当前的网站,用户接下来浏览了当前网站的哪些页面,点击了哪些图片链接按钮等一系列的行为记录,这一个整体的信息就称为是该用户的点击流记录。这篇文章中设计的离线分析系统就是收集WEB系统中产生的这些数据日志,并清洗日志内容存储分布式的HDFS文件存储系统上,接着使用离线分析工具HIVE去统计所有用户的点击流信息。
本系统中我们采用Nginx的access.log来做点击流分析的日志文件。access.log日志文件的格式如下:
样例数据格式:
124.42.13.230 - - [18/Sep/2013:06:57:50 +0000] “GET /shoppingMall?ver=1.2.1 HTTP/1.1” 200 7200 “ http://www.baidu.com.cn” “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; BTRS101170; InfoPath.2; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)”
格式分析:
1. 访客ip地址:124.42.13.230
2. 访客用户信息: - -
3. 请求时间:[18/Sep/2013:06:57:50 +0000]
4. 请求方式:GET
5. 请求的url:/shoppingMall?ver=1.10.2
6. 请求所用协议:HTTP/1.1
7. 响应码:200
8. 返回的数据流量:7200
9. 访客的来源url: http://www.baidu.com.cn
10. 访客所用浏览器:Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; BTRS101170; InfoPath.2; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)
HDFS
Apache Hadoop是用来支持海量数据分布式计算的软件框架,它具备高可靠性,高稳定性,动态扩容,运用简单的计算模型(MapReduce)在集群上进行分布式计算,并支持海量数据的存储。Apache Hadoop主要包含4个重要的模块,一个是 Hadoop Common,支持其它模块运行的通用组件;Hadoop Distributed File System(HDFS), 分布式文件存储系统;Hadoop Yarn,负责计算任务的调度和集群上资源的管理;Hadoop MapReduce,基于Hadoop Yarn的分布式计算框架。在本文的案例中,我们主要用到HDFS作为点击流数据存储,分布式计算框架我们将采用Spark RDDs Operations去替代MapReduce。
要配置Hadoop集群,首先需要配置Hadoop daemons, 它是所有其它Hadoop组件运行所必须的守护进程, 它的配置文件是
etc/hadoop/hadoop-env.sh
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest
Hadoop的运行需要Java开发环境的支持,一定要显示地标明集群上所有机器的JDK安装目录,即使你自己本机的环境已经配置好了JAVA_HOME,因为Hadoop是通过SSH来启动守护进程的,即便是NameNode启动自己本机的守护进程;如果不显示配置JDK安装目录,那么Hadoop在通过SSH启动守护进程时会找不到Java环境而报错。
在本文的案例中,我们只使用Hadoop HDFS组件,所以我们只需要配置HDFS的守护进程,NameNode daemons,SecondaryNameNode daemons以及DataNode daemons,它们的配置文件主要是core-site.xml和hdfs-site.xml:
etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ymhHadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoop/tmp</value>
</property>
</configuration>
fs.defaultFS属性是指定用来做NameNode的主机URI;而hadoop.tmp.dir是配置Hadoop依赖的一些系统运行时产生的文件的目录,默认是在/tmp/${username}目录下的,但是系统一重启这个目录下的文件就会被清空,所以我们重新指定它的目录
etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/your/path</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/your/path</value>
</property>
</configuration>
dfs.replication 是配置每一份在HDFS系统上的文件有几个备份;dfs.namenode.name.dir 是配置用户自定义的目录存储HDFS的业务日志和命名空间日志,也就是操作日志,集群发生故障时可以通过这份文件来恢复数据。dfs.blocksize,定义HDFS最大的文件分片是多大,默认256M,我们不需要改动;dfs.datanode.data.dir, 用来配置DataNode中的数据Blocks应该存储在哪个文件目录下。
最后把配置文件拷贝到集群的所有机子上,接下来就是启动HDFS集群,如果是第一次启动,记得一定要格式化整个HDFS文件系统
$HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>
接下来就是通过下面的命令分别启动NameNode和DataNode
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
$HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
收集用户数据
网站会通过前端JS代码或服务器端的后台代码收集用户浏览数据并存储在网站服务器中。一般运维人员会在离线分析系统和真实生产环境之间部署FTP服务器,并将生产环境上的用户数据每天定时发送到FTP服务器上,离线分析系统就会从FTP服务上采集数据而不会影响到生产环境。
采集数据的方式有多种,一种是通过自己编写shell脚本或Java编程采集数据,但是工作量大,不方便维护,另一种就是直接使用第三方框架去进行日志的采集,一般第三方框架的健壮性,容错性和易用性都做得很好也易于维护。本文采用第三方框架Flume进行日志采集,Flume是一个分布式的高效的日志采集系统,它能把分布在不同服务器上的海量日志文件数据统一收集到一个集中的存储资源中,Flume是Apache的一个顶级项目,与Hadoop也有很好的兼容性。不过需要注意的是Flume并不是一个高可用的框架,这方面的优化得用户自己去维护。
Flume的agent是运行在JVM上的,所以各个服务器上的JVM环境必不可少。每一个Flume agent部署在一台服务器上,Flume会收集web server 产生的日志数据,并封装成一个个的事件发送给Flume Agent的Source,Flume Agent Source会消费这些收集来的数据事件并放在Flume Agent Channel,Flume Agent Sink会从Channel中收集这些采集过来的数据,要么存储在本地的文件系统中要么作为一个消费资源分发给下一个装在分布式系统中其它服务器上的Flume进行处理。Flume提供了点对点的高可用的保障,某个服务器上的Flume Agent Channel中的数据只有确保传输到了另一个服务器上的Flume Agent Channel里或者正确保存到了本地的文件存储系统中,才会被移除。
本系统中每一个FTP服务器以及Hadoop的name node服务器上都要部署一个Flume Agent;FTP的Flume Agent采集Web Server的日志并汇总到name node服务器上的Flume Agent,最后由hadoop name node服务器将所有的日志数据下沉到分布式的文件存储系统HDFS上面。
需要注意的是Flume的Source在本文的系统中选择的是Spooling Directory Source,而没有选择Exec Source,因为当Flume服务down掉的时候Spooling Directory Source能记录上一次读取到的位置,而Exec Source则没有,需要用户自己去处理,当重启Flume服务器的时候如果处理不好就会有重复数据的问题。当然Spooling Directory Source也是有缺点的,会对读取过的文件重命名,所以多架一层FTP服务器也是为了避免Flume“污染”生产环境。Spooling Directory Source另外一个比较大的缺点就是无法做到灵活监听某个文件夹底下所有子文件夹里的所有文件里新追加的内容。关于这些问题的解决方案也有很多,比如选择其它的日志采集工具,像logstash等。
FTP服务器上的Flume配置文件如下:
agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = spooldir
agent.sources.origin.spoolDir = /export/data/trivial/weblogs
agent.sources.origin.channels = memorychannel
agent.sources.origin.deserializer.maxLineLength = 2048
agent.sources.origin.interceptors = i2
agent.sources.origin.interceptors.i2.type = host
agent.sources.origin.interceptors.i2.hostHeader = hostname
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 10000
agent.sinks.target.type = avro
agent.sinks.target.channel = memorychannel
agent.sinks.target.hostname = 172.16.124.130
agent.sinks.target.port = 4545
这里有几个参数需要说明,Flume Agent Source可以通过配置deserializer.maxLineLength这个属性来指定每个Event的大小,默认是每个Event是2048个byte。Flume Agent Channel的大小默认等于于本地服务器上JVM所获取到的内存的80%,用户可以通过byteCapacityBufferPercentage和byteCapacity两个参数去进行优化。
需要特别注意的是FTP上放入Flume监听的文件夹中的日志文件不能同名,不然Flume会报错并停止工作,最好的解决方案就是为每份日志文件拼上时间戳。
在Hadoop服务器上的配置文件如下:
agent.sources = origin
agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = avro
agent.sources.origin.channels = memorychannel
agent.sources.origin.bind = 0.0.0.0
agent.sources.origin.port = 4545
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 5000000
agent.channels.memorychannel.transactionCapacity = 1000000
agent.sinks.target.type = hdfs
agent.sinks.target.channel = memorychannel
agent.sinks.target.hdfs.path = /flume/events/%y-%m-%d/%H%M%S
agent.sinks.target.hdfs.filePrefix = data-%{hostname}
agent.sinks.target.hdfs.rollInterval = 60
agent.sinks.target.hdfs.rollSize = 1073741824
agent.sinks.target.hdfs.rollCount = 1000000
agent.sinks.target.hdfs.round = true
agent.sinks.target.hdfs.roundValue = 10
agent.sinks.target.hdfs.roundUnit = minute
agent.sinks.target.hdfs.useLocalTimeStamp = true
agent.sinks.target.hdfs.minBlockReplicas=1
agent.sinks.target.hdfs.writeFormat=Text
agent.sinks.target.hdfs.fileType=DataStream
round, roundValue,roundUnit三个参数是用来配置每10分钟在hdfs里生成一个文件夹保存从FTP服务器上拉取下来的数据。用户分别在日志文件服务器及HDFS服务器端启动如下命令,便可以一直监听是否有新日志产生,然后拉取到HDFS文件系统中:
$ nohup bin/flume-ng agent -n $your_agent_name -c conf -f conf/$your_conf_name &
Spark
Spark是最近特别火的一个分布式计算框架,最主要原因就是快!和男人不一样,在大数据领域,一个框架会不会火,快是除了可靠性之外一个最重要的话语权,几乎所有新出的分布式框架或即将推出的新版本的MapReduce都在强调一点,我很快。Spark官网上给出的数据是Spark程序和中间数据运行在内存上时计算速度是Hadoop的100倍,即使在磁盘上也是比Hadoop快10倍。
每一个Spark程序都是提供了一个Driver进程来负责运行用户提供的程序,这个Driver进程会生成一个SparkContext,负责和Cluster Manager(可以是Spark自己提供的集群管理工具,也可以是Hadoop 的资源调度工具 Yarn)沟通,Cluster负责协调和调度集群上的Worker Node资源,当Driver获取到集群上Worker Node资源后,就会向Worker Node的Executor发送计算程序(通过Jar或者python文件),接着再向Exectutor发送计算任务去执行,Executor会启动多个线程并行运行计算任务,同时还会根据需求在Worker Node上缓存计算过程中的中间数据。需要注意的虽然Worker Node上可以启动多个物理JVM来运行不同Spark程序的Executor,但是不同的Spark程序之间不能进行通讯和数据交换。另一方面,对于Cluster Manager来说,不需要知道Spark Driver的底层,只要Spark Driver和Cluster Manager能互相通信并获取计算资源就可以协同工作,所以Spark Driver能较为方便地和各种资源调度框架整合,比如Yarn,Mesos等。
图片来源: http://spark.apache.org/docs/latest/cluster-overview.html
Spark就是通过Driver来发送用户的计算程序到集群的工作节点中,然后去并行计算数据,这其中有一个很重要的Spark专有的数据模型叫做RDD(Resilient
distributed dataset), 它代表着每一个计算阶段的数据集合,这些数据集合可以继续它所在的工作节点上,或者通过“shuffle”动作在集群中重新分发后,进行下一步的并行计算,形成新的RDD数据集。这些RDD有一个最重要的特点就是可以并行计算。RDD最开始有两种方式进行创建,一种是从Driver程序中的Scala Collections创建而来(或者其它语言的Collections),将它们转化成RDD然后在工作结点中并发处理,另一种就是从外部的分布式数据文件系统中创建RDD,如HDFS,HBASE或者任何实现了Hadoop InputFormat接口的对象。
对于Driver程序中的Collections数据,可以使用parallelize()方法将数据根据集群节点数进行切片(partitions),然后发送到集群中并发处理,一般一个节点一个切片一个task进行处理,用户也可以自定义数据的切片数。而对于外部数据源的数据,Spark可以从任何基于Hadoop框架的数据源创建RDD,一般一个文件块(blocks)创建一个RDD切片,然后在集群上并行计算。
在Spark中,对于RDDs的计算操作有两种类型,一种是Transformations,另一种是Actions。Transformations相当于Hadoop的Map组件,通过对RDDs的并发计算,然后返回新的RDDs对象;而actions则相当于Hadoop的Reduce组件,通过计算(我们这里说的计算就是function)汇总之前Transformation操作产生的RDDs对象,产生最终结果,然后返回到Driver程序中。特别需要说明的是,所有的Transformations操作都是延迟计算的(lazy), 它们一开始只会记录这个Transformations是用在哪一个RDDs上,并不会开始执行计算,除非遇到了需要返回最终结果到Driver程序中的Action操作,这时候Transformations才会开始真正意义上的计算。所以用户的Spark程序最后一步都需要一个Actions类型的操作,否则这个程序并不会触发任何计算。这么做的好处在于能提高Spark的运行效率,因为通过Transformations操作创建的RDDs对象最终只会在Actions类型的方法中用到,而且只会返回包含最终结果的RDDs到Driver中,而不是大量的中间结果。有时候,有些RDDs的计算结果会多次被重复调用,这就触发多次的重复计算,用户可以使用persist()或者cache()方法将部分RDDs的计算结果缓存在整个集群的内存中,这样当其它的RDDs需要之前的RDDs的计算结果时就可以直接从集群的内存中获得,提高运行效率。
在Spark中,另外一个需要了解的概念就是“Shuffle”,当遇到类似“reduceByKey”的Actions操作时,会把集群上所有分片的RDDs都读一遍,然后在集群之间相互拷贝并全部收集起来,统一计算这所有的RDDs,获得一个整体的结果而不再是单个分片的计算结果,接着再重新分发到集群中或者发送回Driver程序。在Shuffle过程中,Spark会产生两种类型的任务,一种是Map task,用于匹配本地分片需要shuffle的数据并将这些数据写入文件中,然后Reduce task就会读取这些文件并整合所有的数据。 所以说”Shuffle”过程会消耗许多本地磁盘的I/O资源,内存资源,网络I/O,附带还会产生许多的序列化过程。通常,repartition类型的操作,比如:repartitions和coalesce,ByKey类型的操作,比如:reduceByKey,groupByKey,join类型的操作,如:cogroup和join等,都会产生Shuffle过程。
接下来,来谈一谈Spark在集群环境下的一些特性,这部分内容非常非常重要,请大家一定要重点理解。首先,读者们一定要记住,Spark是通过Driver把用户打包提交的Spark程序序列化以后,分发到集群中的工作节点上去运行,对于计算结果的汇总是返回到Driver端,也就是说通常用户都是从Driver服务器上获取到最终的计算结果!在这个大前提下我们来探讨下面几个问题:
1. 关于如何正确地将函数传入RDD operation中,有两种推荐的方式,一种就是直接传函数体,另一种是在伴生对象中创建方法,然后通过类名.方法名的方式传入;如下面的代码所示
object DateHandler {
def parseDate(s: String): String = { ... }
}
rdd.map(DateHandler.parseDate)
错误的传函数的方式如下:
Class MySpark {
def parseDate(s: String): String = { ... }
def rddOperation(rdd:RDD[String]):RDD[String] = {rdd.map(x => this.parseDate(x))}
}
…………
val myspark = new MySpark
myspark.rddOperation(sc.rdd)
这样子的传递方式会把整个mySpark对象序列化后传到集群中,会造成不必要的内存开支。
因为向map中传入的“this.parseDate(x)”是一个对象实例和它里面的函数。
当在RDD operation中访问类中的变量时,也会造成传递整个对象的开销,比如:
Class MySpark {
val myVariable
def rddOperation(rdd:RDD[String]):RDD[String] = {rdd.map(x => x + myVariable)}
}
这样也相当于x => this.x + myVariable,又关联了这个对象实例,
解决方法就是把这个类的变量传入方法内部做局部变量,
就会从访问对象中的变量变为访问局部变量值
def rddOperation(rdd:RDD[String]):RDD[String] = {val _variable = this.myVariable;rdd.map(x => x + _variable)}
2.第二个特别需要注意的问题就是在RDD operations中去更改一个全局变量,
在集群环境中也是很容易出现错误的,注意下面的代码:
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
这段代码最终返回的结果还是0。这是因为这段代码连同counter是序列化后分发到集群上所有的节点机器上,不同的节点上拥有各自独立的counter,并不会是原先Driver上counter的引用,并且统计的值也不一样,最后统计结果也不会返回给Driver去重新赋值。Driver主机上的counter还是它原来的值,不会发生任何变化。如果需要在RDD operations中操作全局变量,就需要使用accumulator()方法,这是一个线程安全的方法,能在并发环境下原子性地改变全局变量的值。
3.对于集群环境下的Spark,第三个重要的是如何去合理地打印RDDs中的值。如果只是使用rdd.foreach(println( )) 或者 rdd.map(println())是行不通的,一定要记住,程序会被分送到集群的工作节点上各自运行,println方法调用的也是工作节点上的输入输出接口,而用户获取数据和计算结果都是在Driver主机上的,所以是无法看到这些打印的结果。解决方法之一就是打印前将所有数据先返回Driver,如rdd.collect().foreach(println),但是这可能会让Driver瞬间耗光内存,因为collect操作将集群上的所有数据全部一次性返回给Driver。较为合理的操作为使用take() 方法先获取部分数据,然后再打印,如:rdd.take(100).foreach(println)。
4. 另外需要补充说明的是foreach(func)这个Action操作,它的作用是对集群上每一个datasets元素执行传入的func方法,这个func方法是在各个工作节点上分别执行的。虽然foreach是action操作,但是它并不是先全部将数据返回给Driver然后再在Driver上执行func方法,它返回的给Driver的Unit,这点要特别注意。所以foreach(func)操作里传入的func函数对Driver中的全局变量的操作或者打印数据等操作对于Driver来说都是无效的,这个func函数只运行在工作节点上。
5. 最后要提的是Spark的共享变量,其中一个共享变量就是使用accumulator方法封装的变量,而另一个共享变量就是广播变量(Broadcast Variables)。在谈广播变量之前,大家需要了解一个概念叫“stage”,每次进行shuffle操作之前的所有RDDs的操作都属于同一个stage。所以每次在shuffle操作时,上一个stage计算的结果都会被Spark封装成广播变量,并通过一定的高效算法将这些计算结果在集群上的每个节点里都缓存上一份,并且是read-only的,这样当下一个stage的任务再次需要之前stage的计算结果时就不用再重新计算了。用户可以自定义广播变量,一般是在某个stage的datasets需要被后续多个stage的任务重复使用的情况下设置会比较有意义。
日志清洗
当Flume从日志服务器上获取到Nginx访问日志并拉取到HDFS系统后,我们接下来要做的就是使用Spark进行日志清洗。
首先是启动Spark集群,Spark目前主要有三种集群部署方式,一种是Spark自带Standalone模式做为cluster manager,另外两种分别是Yarn和Mesos作为cluster manager。在Yarn的部署方式下,又细分了两种提交Spark程序的模式,一种是cluster模式,Driver程序直接运行在Application Master上,并直接由Yarn管理,当程序完成初始化工作后相关的客户端进程就会退出;另一种是client模式,提交程序后,Driver一直运行在客户端进程中并和Yarn的Application Master通信获取工作节点资源。在Standalone的部署方式下,也同样是细分了cluster模式和client模式的Spark程序提交方式,cluster模式下Driver是运行在工作节点的进程中,一旦完成提交程序的任务,相关的客户端进程就会退出;而client模式中,Driver会一直运行在客户端进程中并一直向console输出运行信息。本文案例中,使用Standalone模式部署Spark集群,同时我们选择手动部署的方式来启动Spark集群:
//启动 master 节点 启动完后可以通过 localhost:8080 访问Spark自带的UI界面
./sbin/start-master.sh
//启动 Worker 节点
./sbin/start-slave.sh spark://HOST:PORT
//然后通过spark-submit script 提交Spark程序
//默认是使用client模式运行,也可以手动设置成 cluster模式
//--deploy-mode cluster
$bin/spark-submit --class com.guludada.Spark_ClickStream.VisitsInfo --master spark://ymhHadoop:7077 --executor-memory 1G --total-executor-cores 2 /export/data/spark/sparkclickstream.jar
下面是清洗日志的Spark代码,主要是过滤掉无效的访问日志信息:
package com.guludada.Spark_ClickStream
import scala.io.Source
import java.text.SimpleDateFormat;
import java.util.Locale;
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import java.util.Date;
class WebLogClean extends Serializable {
def weblogParser(logLine:String):String = {
//过滤掉信息不全或者格式不正确的日志信息
val isStandardLogInfo = logLine.split(" ").length >= 12;
if(isStandardLogInfo) {
//过滤掉多余的符号
val newLogLine:String = logLine.replace("- - ", "").replaceFirst("""\[""", "").replace(" +0000]", "");
//将日志格式替换成正常的格式
val logInfoGroup:Array[String] = newLogLine.split(" ");
val oldDateFormat = logInfoGroup(1);
//如果访问时间不存在,也是一个不正确的日志信息
if(oldDateFormat == "-") return ""
val newDateFormat = WebLogClean.sdf_standard.format(WebLogClean.sdf_origin.parse(oldDateFormat))
return newLogLine.replace(oldDateFormat, newDateFormat)
} else {
return ""
}
}
}
object WebLogClean {
val sdf_origin = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);
val sdf_standard = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
val sdf_hdfsfolder = new SimpleDateFormat("yy-MM-dd");
def main(args: Array[String]) {
val curDate = new Date();
val weblogclean = new WebLogClean
val logFile = "hdfs://ymhHadoop:9000/flume/events/"+WebLogClean.sdf_hdfsfolder.format(curDate)+"/*" // Should be some file on your system
val conf = new SparkConf().setAppName("WebLogCleaner").setMaster("local")
val sc = new SparkContext(conf)
val logFileSource = sc.textFile(logFile,1).cache()
val logLinesMapRDD = logFileSource.map(x => weblogclean.weblogParser(x)).filter(line => line != "");
logLinesMapRDD.saveAsTextFile("hdfs://ymhHadoop:9000/spark_clickstream/cleaned_log/"+WebLogClean.sdf_hdfsfolder.format(curDate))
}
}
经过清洗后的日志格式如下:
接着为每一条访问记录拼上sessionID
package com.guludada.Spark_ClickStream
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import java.text.SimpleDateFormat
import java.util.UUID;
import java.util.Date;
class WebLogSession {
}
object WebLogSession {
val sdf_standard = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
val sdf_hdfsfolder = new SimpleDateFormat("yy-MM-dd");
//自定义的将日志信息按日志创建的时间升序排序
def dateComparator(elementA:String ,elementB:String):Boolean = {
WebLogSession.sdf_standard.parse(elementA.split(" ")(1)).getTime < WebLogSession.sdf_standard.parse(elementB.split(" ")(1)).getTime
}
import scala.collection.mutable.ListBuffer
def distinctLogInfoBySession(logInfoGroup:List[String]):List[String] = {
val logInfoBySession:ListBuffer[String] = new ListBuffer[String]
var lastRequestTime:Long = 0;
var lastSessionID:String = "";
for(logInfo <- logInfoGroup) {
//某IP的用户第一次访问网站的记录做为该用户的第一个session日志
if(lastRequestTime == 0) {
lastSessionID = UUID.randomUUID().toString();
//将该次访问日志记录拼上sessionID并放进按session分类的日志信息数组中
logInfoBySession += lastSessionID + " " +logInfo
//记录该次访问日志的时间,并用户和下一条访问记录比较,看时间间隔是否超过30分钟,是的话就代表新Session开始
lastRequestTime = sdf_standard.parse(logInfo.split(" ")(1)).getTime
} else {
//当前日志记录和上一次的访问时间相比超过30分钟,所以认为是一个新的Session,重新生成sessionID
if(sdf_standard.parse(logInfo.split(" ")(1)).getTime - lastRequestTime >= 30 * 60 * 1000) {
//和上一条访问记录相比,时间间隔超过了30分钟,所以当做一次新的session,并重新生成sessionID
lastSessionID = UUID.randomUUID().toString();
logInfoBySession += lastSessionID + " " +logInfo
//记录该次访问日志的时间,做为一个新session开始的时间,并继续和下一条访问记录比较,看时间间隔是否又超过30分钟
lastRequestTime = sdf_standard.parse(logInfo.split(" ")(1)).getTime
} else { //当前日志记录和上一次的访问时间相比没有超过30分钟,所以认为是同一个Session,继续沿用之前的sessionID
logInfoBySession += lastSessionID + " " +logInfo
}
}
}
return logInfoBySession.toList
}
def main(args: Array[String]) {
val curDate = new Date();
val logFile = "hdfs://ymhHadoop:9000/spark_clickstream/cleaned_log/"+WebLogSession.sdf_hdfsfolder.format(curDate) // Should be some file on your system
val conf = new SparkConf().setAppName("WebLogSession").setMaster("local")
val sc = new SparkContext(conf)
val logFileSource = sc.textFile(logFile, 1).cache()
//将log信息变为(IP,log信息)的tuple格式,也就是按IP地址将log分组
val logLinesKVMapRDD = logFileSource.map(line => (line.split(" ")(0),line)).groupByKey();
//对每个(IP[String],log信息[Iterator<String>])中的日志按时间的升序排序
//(其实这一步没有必要,本来Nginx的日志信息就是按访问先后顺序记录的,这一步只是为了演示如何在Scala语境下进行自定义排序)
//排完序后(IP[String],log信息[Iterator<String>])的格式变为log信息[Iterator<String>]
val sortedLogRDD = logLinesKVMapRDD.map(_._2.toList.sortWith((A,B) => WebLogSession.dateComparator(A,B)))
//将每一个IP的日志信息按30分钟的session分类并拼上session信息
val logInfoBySessionRDD = sortedLogRDD.map(WebLogSession.distinctLogInfoBySession(_))
//将List中的日志信息拆分成单条日志信息输出
val logInfoWithSessionRDD = logInfoBySessionRDD.flatMap(line => line).saveAsTextFile("hdfs://ymhHadoop:9000/spark_clickstream/session_log/"+WebLogSession.sdf_hdfsfolder.format(curDate))
}
}
拼接上sessionID的日志如下所示:

最后一步就是根据SessionID来整理用户的浏览信息,代码如下:
package com.guludada.Spark_ClickStream
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import java.text.SimpleDateFormat
import java.util.Date;
class VisitsInfo {
}
object VisitsInfo {
val sdf_standard = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
val sdf_hdfsfolder = new SimpleDateFormat("yy-MM-dd");
//自定义的将日志信息按日志创建的时间升序排序
def dateComparator(elementA:String ,elementB:String):Boolean = {
WebLogSession.sdf_standard.parse(elementA.split(" ")(2)).getTime < WebLogSession.sdf_standard.parse(elementB.split(" ")(2)).getTime
}
import scala.collection.mutable.ListBuffer
def getVisitsInfo(logInfoGroup:List[String]):String = {
//获取用户在该次session里所访问的页面总数
//先用map函数将某次session里的所有访问记录变成(url,logInfo)元组的形式,然后再用groupBy函数按url分组,最后统计共有几个组
val visitPageNum = logInfoGroup.map(log => (log.split(" ")(4),log)).groupBy(x => x._1).count(p => true)
//获取该次session的ID
val sessionID = logInfoGroup(0).split(" ")(0)
//获取该次session的开始时间
val startTime = logInfoGroup(0).split(" ")(2)
//获取该次session的结束时间
val endTime = logInfoGroup(logInfoGroup.length-1).split(" ")(2)
//获取该次session第一次访问的url
val entryPage = logInfoGroup(0).split(" ")(4)
//获取该次session最后一次访问的url
val leavePage = logInfoGroup(logInfoGroup.length-1).split(" ")(4)
//获取该次session的用户IP
val IP = logInfoGroup(0).split(" ")(1)
//获取该次session的用户从哪个网站过来
val referal = logInfoGroup(0).split(" ")(8)
return sessionID + " " + startTime + " " + endTime + " " + entryPage + " " + leavePage + " " + visitPageNum + " " + IP + " " + referal;
}
def main(args: Array[String]) {
val curDate = new Date();
val logFile = "hdfs://ymhHadoop:9000/spark_clickstream/session_log/"+WebLogSession.sdf_hdfsfolder.format(curDate) // Should be some file on your system
val conf = new SparkConf().setAppName("VisitsInfo").setMaster("local")
val sc = new SparkContext(conf)
val logFileSource = sc.textFile(logFile,1).cache()
//将log信息变为(session,log信息)的tuple格式,也就是按session将log分组
val logLinesKVMapRDD = logFileSource.map(line => (line.split(" ")(0),line)).groupByKey();
//对每个(session[String],log信息[Iterator<String>])中的日志按时间的升序排序
//排完序后(session[String],log信息[Iterator<String>])的格式变为log信息[Iterator<String>]
val sortedLogRDD = logLinesKVMapRDD.map(_._2.toList.sortWith((A,B) => VisitsInfo.dateComparator(A,B)))
//统计每一个单独的Session的相关信息
sortedLogRDD.map(VisitsInfo.getVisitsInfo(_)).saveAsTextFile("hdfs://ymhHadoop:9000/spark_clickstream/visits_log/"+WebLogSession.sdf_hdfsfolder.format(curDate))
}
}
最后整理出来的日志信息的格式和示例图:
SessionID 访问时间 离开时间 第一次访问页面 最后一次访问的页面 访问的页面总数 IP Referal
Session1 2016-05-30 15:17:00 2016-05-30 15:19:00 /blog/me /blog/others 5 192.168.12.130 www.baidu.com
Session2 2016-05-30 14:17:00 2016-05-30 15:19:38 /home /profile 10 192.168.12.140 www.178.com
Session3 2016-05-30 12:17:00 2016-05-30 15:40:00 /products /detail 6 192.168.12.150 www.78dm.com

Hive
Hive是一个数据仓库,让用户可以使用SQL语言操作分布式存储系统中的数据。在客户端,用户可以使用如何关系型数据库一样的建表SQL语句来创建数据仓库的数据表,并将HDFS中的数据导入到数据表中,接着就可以使用Hive SQL语句非常方便地对HDFS中的数据做一些增删改查的操作;在底层,当用户输入Hive Sql语句后,Hive会将SQL语句发送到它的Driver进程中的语义分析器进行分析,然后根据Hive SQL的语义转化为对应的Hadoop MapReduce程序来对HDFS中数据来进行操作;同时,Hive还将表的表名,列名,分区,属性,以及表中的数据的路径等元数据信息都存储在外部的数据库中,如:Mysql或者自带的Derby数据库等。
Hive中主要由以下几种数据模型组成:
1. Databases,相当于命名空间的作用,用来避免同名的表,视图,列名的冲突,就相当于管理同一类别的一组表的库。具体的表现为HDFS中/user/hive/warehouse/中的一个目录。
2. Tables,是具有同一模式的数据的抽象,简单点来说就是传统关系型数据库中的表。具体的表现形式为Databases下的子目录,里面存储着表中的数据块文件,而这些文件是从经过MapReduce清洗后的贴源数据文件块拷贝过来的,也就是使用Hive SQL 中的Load语句,Load语句就是将原先HDFS系统中的某个路径里的数据拷贝到/user/hive/warehouse/路径里的过程,然后通过Mysql中存储的元数据信息将这些数据和Hive的表映射起来。
3. Partitions,创建表时,用户可以指定以某个Key值来为表中的数据分片。从Tables的层面来讲,Partition就是表中新加的一个虚拟字段,用来为数据分类,在HDFS文件系统中的体现就是这个表的数据分片都按Key来划分并进入到不同的目录中,但是Hive不会保证属于某个Key的内容就一定会进入到某个分片中,因为Hive无法感知,所以需要用户在插入数据时自己要将数据根据key值划分到所对应的数据分片中,这样在以后才能提高查询效率。
4. Buckets(Clusters),是指每一个分片上的数据根据表中某个列的hash值组织在一起,也就是进入到同一个桶中,这样能提升数据查询的效率。分桶最大的意义在于增加join的效率。比如 select user.id, user.name,admin.tele from user join admin on user.id=admin.id, 已经根据id将数据分进不同的桶里,两个数据表join的时候,只要把hash结果相同的桶直接相连就行,提高join的效率。一般两张表的分桶数量要一致,才能达到join的最高效率,如果是倍数关系,也会提高join的效率但没有一致数量的分桶效率高,如果不是倍数关系分桶又不一致,那么效率和没分桶没什么区别。
Spark SQL
在作者之前的Hadoop文章里,使用MapReduce清洗完日志文件后,在Hive的客户端中使用Hive SQL去构建对应的数据仓库并对数据进行分析。和之前不同的是,在本篇文章中, 作者使用的是Spark SQL去对Hive数据仓库进行操作。因为文章篇幅有限,下面只对Spark SQL进行一个简单的介绍,更多具体的内容读者们可以去阅读官方文档。
Spark SQL是Spark项目中专门用来处理结构化数据的一个模块,用户可以通过SQL,DataFrames API,DataSets API和Spark SQL进行交互。Spark SQL可以通过标准的SQL语句对各种数据源中的数据进行操作,如Json,Parquet等,也可以通过Hive SQL操作Hive中的数据;DataFrames是一组以列名组织的数据结构,相当于关系型数据库中的表,DataFrames可以从结构化的数据文件中创建而来,如Json,Parquet等,也可以从Hive中的表,外部数据库,RDDs等创建出来;Datasets是Spark1.6后新加入的API,类似于RDDs,可以使用Transformations和Actions API 操作数据,同时提供了很多运行上的优化,并且用Encoder来替代Java Serialization接口进行序列化相关的操作。
DataFrames可以通过RDDs转化而来,其中一种转化方式就是通过case class来定义DataFrames中的列结构,也可以说是表结构,然后将RDDs中的数据转化为case class对象,接着通过反射机制获取到case class对表结构的定义并转化成DataFrames对象。转化成DF对象后,用户可以方便地使用DataFrames提供的“domain-specific”操作语言来操作里面的数据,亦或是将DataFrames对象注册成其对应的表,然后通过标准SQL语句来操作里面的数据。总之,Spark SQL提供了多样化的数据结构和操作方法让我们能以SQL语句方便地对数据进行操作,减少运维和开发成本,十分方便和强大!
而在本案例里,我们将使用星型模型来构建数据仓库的ODS(OperationalData Store)层。
Visits数据分析
页面具体访问记录Visits的事实表和维度表结构
接下来启动spark shell,然后使用Spark SQL去操作Hive数据仓库
$bin/spark-shell --jars lib/mysql-connector-java-5.0.5.jar
在spark shell顺序执行如下命令操作Hive数据仓库,在此过程中,大家会发现执行速度比在Hive客户端中快很多,原因就在于使用Spark SQL去操作Hive,其底层使用的是Spark RDDs去操作HDFS中的数据,而不再是原来的Hadoop MapReduce。
//创建HiveContext对象,并且该对象继承了SqlContext
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
//在数据仓库中创建Visits信息的贴源数据表:
sqlContext.sql("create table visitsinfo_spark(session string,startdate string,enddate string,entrypage string,leavepage string,viewpagenum string,ip string,referal string) partitioned by(inputDate string) clustered by(session) sorted by(startdate) into 4 buckets row format delimited fields terminated by ' '")
//将HDFS中的数据导入到HIVE的Visits信息贴源数据表中
sqlContext.sql("load data inpath '/spark_clickstream/visits_log/16-07-18' overwrite into table visitsinfo_spark partition(inputDate='2016-07-27')")

// 根据具体的业务分析逻辑创建ODS层的Visits事实表,并从visitsinfo_spark的贴源表中导入数据
sqlContext.sql("create table ods_visits_spark(session string,entrytime string,leavetime string,entrypage string,leavepage string,viewpagenum string,ip string,referal string) partitioned by(inputDate string) clustered by(session) sorted by(entrytime) into 4 buckets row format delimited fields terminated by ' '")
sqlContext.sql("insert into table ods_visits_spark partition(inputDate='2016-07-27') select vi.session,vi.startdate,vi.enddate,vi.entrypage,vi.leavepage,vi.viewpagenum,vi.ip,vi.referal from visitsinfo_spark as vi where vi.inputDate='2016-07-27'")
//创建Visits事实表的时间维度表并从当天的事实表里导入数据
sqlContext.sql("create table ods_dim_visits_time_spark(time string,year string,month string,day string,hour string,minutes string,seconds string) partitioned by(inputDate String) clustered by(year,month,day) sorted by(time) into 4 buckets row format delimited fields terminated by ' '")
// 将“访问时间”和“离开时间”两列的值合并后再放入时间维度表中,减少数据的冗余
sqlContext.sql("insert overwrite table ods_dim_visits_time_spark partition(inputDate='2016-07-27') select distinct ov.timeparam, substring(ov.timeparam,0,4),substring(ov.timeparam,6,2),substring(ov.timeparam,9,2),substring(ov.timeparam,12,2),substring(ov.timeparam,15,2),substring(ov.timeparam,18,2) from (select ov1.entrytime as timeparam from ods_visits_spark as ov1 union select ov2.leavetime as timeparam from ods_visits_spark as ov2) as ov")
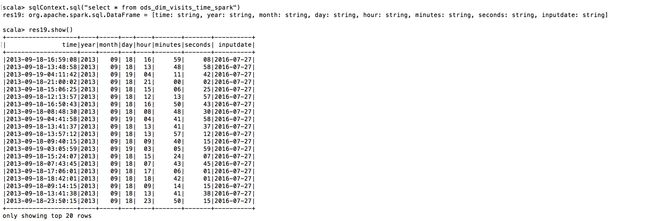
//创建visits事实表的URL维度表并从当天的事实表里导入数据
sqlContext.sql("create table ods_dim_visits_url_spark(pageurl string,host string,path string,query string) partitioned by(inputDate string) clustered by(pageurl) sorted by(pageurl) into 4 buckets row format delimited fields terminated by ' '")
//将每个session的进入页面和离开页面的URL合并后存入到URL维度表中
sqlContext.sql("insert into table ods_dim_visits_url_spark partition(inputDate='2016-07-27') select distinct ov.pageurl,b.host,b.path,b.query from (select ov1.entrypage as pageurl from ods_visits_spark as ov1 union select ov2.leavepage as pageurl from ods_visits_spark as ov2 ) as ov lateral view parse_url_tuple(concat('https://localhost',ov.pageurl),'HOST','PATH','QUERY') b as host,path,query")
//将每个session从哪个外站进入当前网站的信息存入到URL维度表中
sqlContext.sql("insert into table ods_dim_visits_url_spark partition(inputDate='2016-07-27') select distinct ov.referal,b.host,b.path,b.query from ods_visits_spark as ov lateral view parse_url_tuple(substr(ov.referal,2,length(ov.referal)-2),'HOST','PATH','QUERY') b as host,path,query")

//查询访问网站页面最多的前20个session的信息
sqlContext.sql("select * from ods_visits_spark as ov sort by viewpagenum desc").show()

Troubleshooting
使用Flume拉取文件到HDFS中会遇到将文件分散成多个1KB-5KB的小文件的问题
需要注意的是如果遇到Flume会将拉取过来的文件分成很多份1KB-5KB的小文件存储到HDFS上,那么很可能是HDFS Sink的配置不正确,导致系统使用了默认配置。spooldir类型的source是将指定目录中的文件的每一行封装成一个event放入到channel中,默认每一行最大读取1024个字符。在HDFS Sink端主要是通过rollInterval(默认30秒), rollSize(默认1KB), rollCount(默认10个event)3个属性来决定写进HDFS的分片文件的大小。rollInterval表示经过多少秒后就将当前.tmp文件(写入的是从channel中过来的events)下沉到HDFS文件系统中,rollSize表示一旦.tmp文件达到一定的size后,就下沉到HDFS文件系统中,rollCount表示.tmp文件一旦写入了指定数量的events就下沉到HDFS文件系统中。
使用Flume拉取到HDFS中的文件格式错乱
这是因为HDFS Sink的配置中,hdfs.writeFormat属性默认为“Writable”会将原先的文件的内容序列化成HDFS的格式,应该手动设置成hdfs.writeFormat=“text”; 并且hdfs.fileType默认是“SequenceFile”类型的,是将所有event拼成一行,应该该手动设置成hdfs.fileType=“DataStream”,这样就可以是一行一个event,与原文件格式保持一致
启动Spark任务的时候会报任务无法序列化的错误

而这个错误的主要原因是Driver向worker通过RPC通信发送的任务无法序列化,很有可能就是用户在使用transformations或actions方法的时候,向这个方法中传入的函数里包含不可序列化的对象,如上面的程序中 logFileSource.map(x => weblogclean.weblogParser(x)) 向map中传入的函数包含不可序列化的对象weblogclean,所以要将该对象的相关类变为可序列化的类,通过extends Serializable的方法解决
在分布式环境下如何设置每个用户的SessionID
可以使用UUID,UUID是分布式环境下唯一的元素识别码,它由日期和时间,时钟序列,机器识别码(一般为网卡MAC地址)三部分组成。这样就保证了每个用户的SessionID的唯一性。
使用maven编译Spark程序时报错
在使用maven编译Spark程序时会报错,[ERROR] error: error while loading CharSequence, class file ‘/Library/Java/JavaVirtualMachines/jdk1.8.0_77.jdk/Contents/Home/jre/lib/rt.jar(java/lang/CharSequence.class)’ is broken
如图:
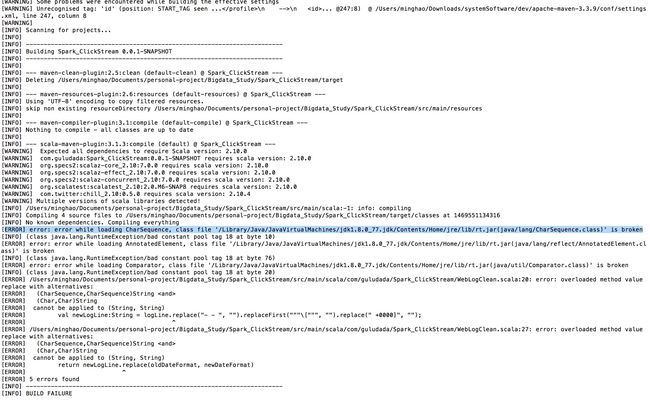
主要原因是Scala 2.10 和 JDK1.8的版本冲突问题,解决方案只能是将JDK降到1.7去编译
要在Spark中使用HiveContext,配置完后启动spark-shell报错
要在Spark中使用HiveContext,将所需的Hive配置文件拷贝到Spark项目的conf目录下,并且把连接数据库的Driver包也放到了Spark项目中的lib目录下,然后启动spark-shell报错,主要还是找不到CLASSPATH中的数据库连接驱动包,如下图:

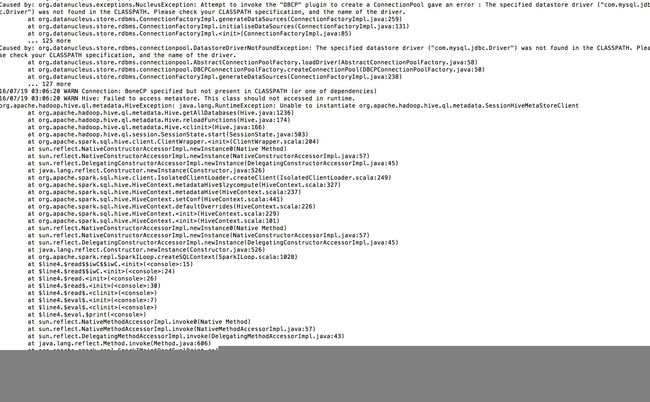
目前作者想到的解决方案比较笨拙:就是启动spark-shell的时候显示地告诉驱动jar包的位置
$bin/spark-shell --jars lib/mysql-connector-java-5.0.5.jar