*_train_test.prototxt,*_deploy.prototxt,*_slover.prototxt文件编写时注意事项
1、*_train_test.prototxt文件
这是训练与测试网络配置文件
(1)在数据层中 参数include{
phase:TRAIN/TEST
}
TRAIN与TEST不能有“...”否则会报错,还好提示信息里,会提示哪一行出现了问题,如下图:
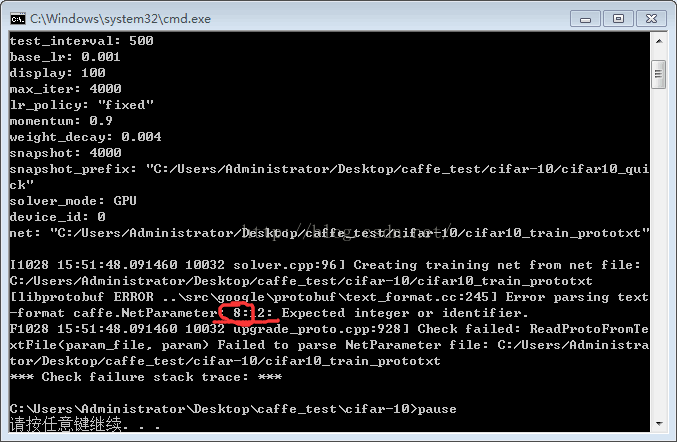
数字8就代表配置文件的第8行出现了错误
(2)卷积层和全连接层相似:卷积层(Convolution),全连接层(InnerProduct,容易翻译成内积层)相似处有两个【1】:都有两个param{lr_mult:1
decay_mult:1
}
param{lr_mult: 2
decay_mult: 0
}
【2】:convolution_param{}与inner_product_param{}里面的参数相似,甚至相同
今天有事,明天再续!
续上!
(3)平均值文件*_mean.binaryproto要放在transform_param{}里,训练与测试数据集放在data_param{}里
2.*_deploy.prototxt文件
【1】*_deploy.prototxt文件的构造和*_train_test.prototxt文件的构造稍有不同首先没有test网络中的test模块,只有训练模块
【2】数据层的写法和原来也有不同,更加简洁:
input: "data"
input_dim: 1
input_dim: 3
input_dim: 32
input_dim: 32
注意红色部分,那是数据层的名字,没有这个的话,第一卷积层无法找到数据,我一开始没有加这句就报错。下面的四个参数有点类似batch_size(1,3,32,32)里四个参数
【3】卷积层和全连接层中weight_filler{}与bias_filler{}两个参数不用再填写,应为这两个参数的值,由已经训练好的模型*.caffemodel文件提供
【4】输出层的变化(1)没有了test模块测试精度(2)输出层
*_train_test.prototxt文件:
layer{
name: "loss"
type: "SoftmaxWithLoss"#注意此处与下面的不同
bottom: "ip2"
bottom: "label"#注意标签项在下面没有了,因为下面的预测属于哪个标签,因此不能提供标签
top: "loss"
}
*_deploy.prototxt文件:
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
***注意在两个文件中输出层的类型都发生了变化一个是SoftmaxWithLoss,另一个是Softmax。另外为了方便区分训练与应用输出,训练是输出时是loss,应用时是prob。
3、*_slover.prototxt
net: "test.prototxt"
#训练网络的配置文件
test_iter: 100
#test_iter 指明在测试阶段有多上个前向过程(也就是有多少图片)被执行。
在MNIST例子里,在网络配置文件里已经设置test网络的batch size=100,这里test_iter
设置为100,那在测试阶段共有100*100=10000 图片被处理
test_interval: 500
#每500次训练迭代后,执行一次test
base_lr: 0.01
#学习率初始化为0.01
momentum:0.9
#u=0.9
weight_decay:0.0005
#
lr_policy: "inv"
gamma: 0.0001
power: 0.75
#以上三个参数都和降低学习率有关,详细的学习策略和计算公式见下面
// The learning rate decay policy. The currently implemented learning rate
// policies are as follows:
// - fixed: always return base_lr.
// - step: return base_lr * gamma ^ (floor(iter / step))
// - exp: return base_lr * gamma ^ iter
//// - inv: return base_lr * (1 + gamma * iter) ^ (- power)
// - multistep: similar to step but it allows non uniform steps defined by
// stepvalue
// - poly: the effective learning rate follows a polynomial decay, to be
// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
// - sigmoid: the effective learning rate follows a sigmod decay
// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
// where base_lr, max_iter, gamma, step, stepvalue and power are defined
// in the solver parameter protocol buffer, and iter is the current iteration.
display:100
#每100次迭代,显示结果
snapshot: 5000
#每5000次迭代,保存一次快照
snapshot_prefix: "path_prefix"
#快照保存前缀:更准确的说是快照保存路径+前缀,应为文件名后的名字是固定的
solver_mode:GPU
#选择解算器是用cpu还是gpu
批处理文件编写:
F:/caffe/caffe-windows-master/bin/caffe.exe train --solver=C:/Users/Administrator/Desktop/caffe_test/cifar-10/cifar10_slover_prototxt --gpu=all
pause
先写到这里,以后补充!