Trie树(字典树)
1. Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
2. 字典树的构建
题目:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
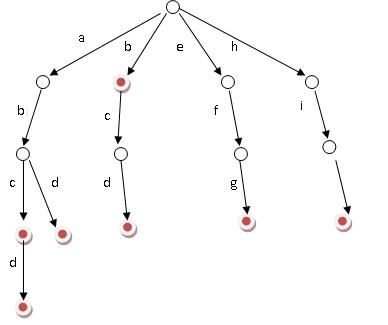
ok,如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为
红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
已知n个由小写字母构成的平均长度为10的单词,判断其中
是否存在某个串为另一个串的前缀子串。下面对比3种方法:
- 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
- 使用hash:我们用hash存下所有字符串的所有的前缀子串,建立存有子串hash的复杂度为O(n*len),而查询的复杂度为O(n)* O(1)= O(n)。
- 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度也只是O(len)。(说白了,就是Trie树的平均高度h为len,所以Trie树的查询复杂度为O(h)=O(len)。好比一棵二叉平衡树的高度为logN,则其查询,插入的平均时间复杂度亦为O(logN))。
3. 查询
Trie树是简单但实用的数据结构,通常用于实现字典查询。我们做即时响应用户输入的AJAX搜索框时,就是Trie开始。本质上,Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。下面,再举一个例子。给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
可以看出: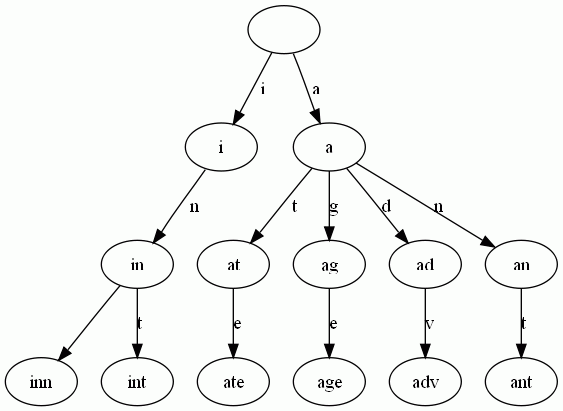
- 每条边对应一个字母。
- 每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
- 单词inn与单词int有共同的前缀“in”, 因此他们共享左边的一条分支,root->i->in。同理,ate, age, adv, 和ant共享前缀"a",所以他们共享从根节点到节点"a"的边。
搭建Trie的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。比如要插入单词add,就有下面几步:
- 考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
- 考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
- 考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
4. 应用
- 1、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
- 2、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
- 3、 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
- 4、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
5. 代码实现(Java)
package binarytree;
/**
* 字典树的Java实现。实现了插入、查询以及深度优先遍历.
* Trie tree's java implementation.(Insert,Search,DFS)
* @author jiutianhe
* @time 2012.10.16
*/
public class TrieTree {
final int MAX_SIZE=26;
public class TrieTreeNode {
int nCount;//记录该字符出现次数
char ch; //记录该字符
TrieTreeNode[] child;
public TrieTreeNode() {
nCount=1;
child=new TrieTreeNode[MAX_SIZE];
}
}
//字典树的插入和构建
public void createTrie(TrieTreeNode node,String str){
if (str==null||str.length()==0) {
return;
}
char[] letters=str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
node.child[pos] = new TrieTreeNode();
}else {
node.child[pos].nCount++;
}
node.ch=letters[i];
node = node.child[pos];
}
}
//字典树的查找
public int findCount(TrieTreeNode node,String str){
if (str==null||str.length()==0) {
return -1;
}
char[] letters=str.toCharArray();
for (int i = 0; i < letters.length; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
return 0;
}else {
node=node.child[pos];
}
}
return node.nCount;
}
}
@Test
public void trieTreeTest2(){
/**
* Problem Description
* 老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计
* 出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
*/
String[] strs={
"banana",
"band",
"bee",
"absolute",
"acm",
};
String[] prefix={
"ba",
"b",
"band",
"abc",
};
TrieTree tree = new TrieTree();
TrieTreeNode root=tree.new TrieTreeNode();
for (String s : strs) {
tree.createTrie(root, s);
}
// tree.printAllWords();
for(String pre:prefix){
int num=tree.findCount(root,pre);
System.out.println(pre+" "+num);
}
}
代码2:
package com.algorithm;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*
* <p>
* Title:
* </p>
* <p>
* Description: 单词Trie树
* </p>
*
* @createDate:2013-10-17
* @author
* @version 1.0
*/
public class WordTrie {
class TrieNode {
/**
* trie tree word count
*/
int count = 0;
/**
* trie tree prefix count
*/
int prefixCount = 0;
/**
* 指向各个子树的指针,存储26个字母[a-z]
*/
TrieNode[] next = new TrieNode[26];
/**
* 当前TrieNode状态 ,默认 0 , 1表示从根节点到当前节点的路径表示一个词,即叶子节点
*/
int nodeState = 0;
TrieNode() {
count = 0;
prefixCount = 0;
next = new TrieNode[26];
nodeState = 0;
}
}
/** trie树根 */
private TrieNode root = new TrieNode();
/** 英文字符串正则匹配 */
static String englishPattern = "^[A-Za-z]+$";
/** 中文正则匹配 */
static String chinesePattern = "[\u4e00-\u9fa5]";
static int ARRAY_LENGTH = 26;
static String zeroString = "";
/**
* 插入字串,用循环代替迭代实现
*
* @param words
*/
public void insert(String word) {
insert(this.root, word);
}
/**
* 插入字串,用循环代替迭代实现
*
* @param root
* @param words
*/
private void insert(TrieNode root, String word) {
word = word.toLowerCase();// //转化为小写
char[] chrs = word.toCharArray();
for (int i = 0, length = chrs.length; i < length; i++) {
// /用相对于a字母的值作为下标索引,也隐式地记录了该字母的值
int index = chrs[i] - 'a';
if (index >= 0 && index < ARRAY_LENGTH) {//过滤特殊字符,例如`等
if (root.next[index] != null) {
// //已经存在了,该子节点prefixCount++
root.next[index].prefixCount++;
} else {
// /如果不存在
root.next[index] = new TrieNode();
root.next[index].prefixCount++;
}
// /如果到了字串结尾,则做标记
if (i == length - 1) {
root.next[index].nodeState = 1;
root.next[index].count++;
}
// /root指向子节点,继续处理
root = root.next[index];
}
}
}
/**
*
* @Title: addWord
* @Description: add word
* @param @param word
* @return void
* @throws
*/
public void addWord(String word) {
if (word == null || "".equals(word.trim())) {
throw new IllegalArgumentException("word can not be null!");
}
// if(!word.matches(englishPattern)){
// System.out.println(word);
// throw new IllegalArgumentException("word must be english!");
// }
addWord(root, word);
}
/**
*
* @Title: addWord
* @Description:add word to node
* @param @param node
* @param @param word
* @return void
* @throws
*/
private void addWord(TrieNode node, String word) {
if (word.length() == 0) { // if all characters of the word has been
// added
node.count++;
node.nodeState = 1;
} else {
node.prefixCount++;
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
if (index >= 0 && index < ARRAY_LENGTH) {
if (node.next[index] == null) {
node.next[index] = new TrieNode();
}
// go the the next character
addWord(node.next[index], word.substring(1));
}
}
}
/**
*
* @Title: prefixSearchWord
* @Description: 前缀搜索
* @param @param word
* @param @return
* @return List<String>
* @throws
*/
public List<String> prefixSearchWord(String word) {
if (word == null || "".equals(word.trim())) {
return new ArrayList<String>();
}
if (!word.matches(englishPattern)) {
return new ArrayList<String>();
}
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
if (root.next != null && root.next[index] != null) {
return depthSearch(root.next[index], new ArrayList<String>(),
word.substring(1), "" + c, word);
} else {
return new ArrayList<String>();
}
}
/**
*
* @Title: searchWord
* @Description: 搜索单词,以a-z为根,分别向下递归搜索
* @param @param word
* @param @return
* @return List<String>
* @throws
*/
public List<String> searchWord(String word) {
if (word == null || "".equals(word.trim())) {
return new ArrayList<String>();
}
if (!word.matches(englishPattern)) {
return new ArrayList<String>();
}
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
List<String> list = new ArrayList<String>();
if (root.next == null) {
return list;
}
for (int i = 0; i < ARRAY_LENGTH; i++) {
int j = 'a' + i;
char temp = (char) j;
if (root.next[i] != null) {
if (index == i) {
fullSearch(root.next[i], list, word.substring(1),
"" + temp, word);
} else {
fullSearch(root.next[i], list, word, "" + temp, word);
}
}
}
return list;
}
/**
*
* @Title: fullSearch
* @Description: 匹配到对应的字母,则以该字母为字根,继续匹配完所有的单词。
* @param @param node
* @param @param list 保存搜索到的字符串
* @param @param word 搜索的单词.匹配到第一个则减去一个第一个,连续匹配,直到word为空串.若没有连续匹配,则恢复到原串。
* @param @param matchedWord 匹配到的单词
* @param @return
* @return List<String>
* @throws
*/
private List<String> fullSearch(TrieNode node, List<String> list,
String word, String matchedWord, String inputWord) {
if (node.nodeState == 1 && word.length() == 0) {
list.add(matchedWord);
}
if (word.length() != 0) {
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
for (int i = 0; i < ARRAY_LENGTH; i++) {
if (node.next[i] != null) {
int j = 'a' + i;
char temp = (char) j;
if (index == i) {
// 连续匹配
fullSearch(node.next[i], list, word.substring(1),
matchedWord + temp, inputWord);
} else {
// 未连续匹配,则重新匹配
fullSearch(node.next[i], list, inputWord, matchedWord
+ temp, inputWord);
}
}
}
} else {
if (node.prefixCount > 0) {
for (int i = 0; i < ARRAY_LENGTH; i++) {
if (node.next[i] != null) {
int j = 'a' + i;
char temp = (char) j;
fullSearch(node.next[i], list, zeroString, matchedWord
+ temp, inputWord);
}
}
}
}
return list;
}
/**
*
* @Title: depthSearch
* @Description: 深度遍历子树
* @param @param node
* @param @param list 保存搜索到的字符串
* @param @param word 搜索的单词.匹配到第一个则减去一个第一个,连续匹配,直到word为空串.若没有连续匹配,则恢复到原串。
* @param @param matchedWord 匹配到的单词
* @param @return
* @return List<String>
* @throws
*/
private List<String> depthSearch(TrieNode node, List<String> list,
String word, String matchedWord, String inputWord) {
if (node.nodeState == 1 && word.length() == 0) {
list.add(matchedWord);
}
if (word.length() != 0) {
char c = word.charAt(0);
c = Character.toLowerCase(c);
int index = c - 'a';
// 继续完全匹配,直到word为空串,否则未找到
if (node.next[index] != null) {
depthSearch(node.next[index], list, word.substring(1),
matchedWord + c, inputWord);
}
} else {
if (node.prefixCount > 0) {// 若匹配单词结束,但是trie中的单词并没有完全找到,需继续找到trie中的单词结束.
// node.prefixCount>0表示trie中的单词还未结束
for (int i = 0; i < ARRAY_LENGTH; i++) {
if (node.next[i] != null) {
int j = 'a' + i;
char temp = (char) j;
depthSearch(node.next[i], list, zeroString, matchedWord
+ temp, inputWord);
}
}
}
}
return list;
}
/**
* 遍历Trie树,查找所有的words以及出现次数
*
* @return HashMap<String, Integer> map
*/
public Map<String, Integer> getAllWords() {
return preTraversal(this.root, "");
}
/**
* 前序遍历。。。
*
* @param root
* 子树根节点
* @param prefixs
* 查询到该节点前所遍历过的前缀
* @return
*/
private Map<String, Integer> preTraversal(TrieNode root, String prefixs) {
Map<String, Integer> map = new HashMap<String, Integer>();
if (root != null) {
if (root.nodeState == 1) {
// //当前即为一个单词
map.put(prefixs, root.count);
}
for (int i = 0, length = root.next.length; i < length; i++) {
if (root.next[i] != null) {
char ch = (char) (i + 'a');
// //递归调用前序遍历
String tempStr = prefixs + ch;
map.putAll(preTraversal(root.next[i], tempStr));
}
}
}
return map;
}
/**
* 判断某字串是否在字典树中
*
* @param word
* @return true if exists ,otherwise false
*/
public boolean isExist(String word) {
return search(this.root, word);
}
/**
* 查询某字串是否在字典树中
*
* @param word
* @return true if exists ,otherwise false
*/
private boolean search(TrieNode root, String word) {
char[] chs = word.toLowerCase().toCharArray();
for (int i = 0, length = chs.length; i < length; i++) {
int index = chs[i] - 'a';
if (root.next[index] == null) {
// /如果不存在,则查找失败
return false;
}
root = root.next[index];
}
return true;
}
}
测试和计算词频中最大n个
package com.algorithm;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.PriorityQueue;
public class WordTrieMain {
public static void main(String[] args){
wordMaxNFrequency(10);
}
public static void test1(){
WordTrie trie=new WordTrie();
trie.addWord("ibiyzbi");
System.out.println("----------------------------------------");
List<String> words=trie.searchWord("bi");
for(String s: words){
System.out.println(s);
}
}
public static void test(){
WordTrie trie=new WordTrie();
trie.addWord("abi");
trie.addWord("ai");
trie.addWord("aqi");
trie.addWord("biiiyou");
trie.addWord("dqdi");
trie.addWord("ji");
trie.addWord("li");
trie.addWord("li");
trie.addWord("li");
trie.addWord("lipi");
trie.addWord("qi");
trie.addWord("qibi");
trie.addWord("i");
trie.addWord("ibiyzbi");
List<String> list=trie.prefixSearchWord("li");
for(String s: list){
System.out.println(s);
}
System.out.println("----------------------------------------");
System.out.println(trie.getAllWords());
System.out.println("----------------------------------------");
List<String> li=trie.searchWord("i");
for(String s: li){
System.out.println(s);
}
System.out.println("----------------------------------------");
List<String> words=trie.searchWord("bi");
for(String s: words){
System.out.println(s);
}
System.out.println("----------------------------------------");
List<String> lst=trie.searchWord("q");
for(String s: lst){
System.out.println(s);
}
}
/**
* @Title: wordMaxNFrequency
* @Description: 计算文章词频中最大的前N个
* @param 设定文件
* @return void 返回类型
* @throws
*/
public static void wordMaxNFrequency(int n){
// InputStream is = new WordTrieMain().getClass().getClassLoader().getResourceAsStream("words.txt");
BufferedReader br = null;
try {
File file= new File("src/com/algorithm/words.txt");
//读取语料库words.txt
br = new BufferedReader(new InputStreamReader(new FileInputStream(file.getAbsolutePath()),"GBK"));
String word="";
WordTrie trie=new WordTrie();
while ((word = br.readLine()) != null) {
trie.insert(word);;
}
Map<String,Integer> map = trie.getAllWords();
System.out.println(map.get("the"));
PriorityQueue<Map.Entry<String, Integer>> pq=new PriorityQueue<Map.Entry<String, Integer>>(10,new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
int i =0;
for(Entry<String,Integer> entry : map.entrySet()){
if(i<n){
pq.offer(entry);
}else{
Entry<String,Integer> entryTemp = (Entry<String, Integer>) pq.peek();
if(entryTemp.getValue().compareTo(entry.getValue())<0){
pq.poll();
pq.offer(entry);
}
}
i++;
}
System.out.println(pq.toString());
}catch (FileNotFoundException e) {
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}
finally{
try{
br.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
}
Trie树占用内存较大,例如:处理最大长度为20、全部为小写字母的一组字符串,则可能需要 2620 个节点来保存数据。而这样的树实际上稀疏的十分厉害,可以采用左儿子右兄弟的方式来改善,也可以采用需要多少子节点则添加多少子节点来解决(不要类似网上的示例,每个节点初始化时就申请一个长度为26的数组)。
Wiki上提到了采用三数组Trie(Tripple-Array Trie)和二数组Trie(Double-Array Trie)来解决该问题,此外还有压缩等方式来缓解该问题。
package com.recommend.base.algorithm;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Map;
import java.util.TreeMap;
import org.apache.commons.lang3.StringUtils;
public class Trie {
private TrieNode root; //根节点
public Trie() {
this.root = new TrieNode();
}
private class TrieNode { //节点类
private int num; //通过的字符串数(包含在此结束的字符串)
private int count; //刚好在这里结束的单词数
private Map<Character,TrieNode> son; //记录子节点
TrieNode() {
num = 1;
count = 0;
son = new TreeMap<>(); //TreeMap用于排序
}
}
public void add(String word) { //在字典树中插入一个字符串
if(StringUtils.isBlank(word)) {
return;
}
TrieNode node = root;
char[] letters = word.toCharArray();
for(char c : letters) {
if(node.son.containsKey(c)) {
node.son.get(c).num++;
} else {
node.son.put(c, new TrieNode());
}
node = node.son.get(c);
}
node.count++;
}
public int countWord(String word) { //计算字符串出现的次数
return count(word, false);
}
public int countPrefix(String prefix) { //计算前缀出现的次数
return count(prefix, true);
}
public boolean contain(String word) { //是否含有字符串
return count(word, false) > 0;
}
public int count(String word, boolean isPrefix) { //计算字符串/前缀出现的次数
if(StringUtils.isBlank(word))
return 0;
TrieNode node = root;
char[] letters = word.toCharArray();
for(char c : letters) {
if(node.son.containsKey(c))
node = node.son.get(c);
else
return 0;
}
return isPrefix? node.num: node.count;
}
public Map<String, Integer> getSortedWordsAndCounts() { //获取排序号的字符串和其出现次数
Map<String, Integer> map = new TreeMap<>();
getSortedWordsAndCounts(root, map, StringUtils.EMPTY);
return map;
}
private void getSortedWordsAndCounts(TrieNode node, Map<String, Integer> map, String pre) {
for(Map.Entry<Character,TrieNode> e: node.son.entrySet()) {
String prefix = pre + e.getKey();
if(e.getValue().count > 0) {
map.put(prefix, e.getValue().count);
}
getSortedWordsAndCounts(e.getValue(), map, prefix);
}
}
public Collection<String> getSortedWords() { //获取排好序的字符串
Collection<String> list = new ArrayList<>();
getSortedWords(root, list, StringUtils.EMPTY);
return list;
}
private void getSortedWords(TrieNode node, Collection<String> list, String pre) {
for(Map.Entry<Character,TrieNode> e: node.son.entrySet()) {
String prefix = pre + e.getKey();
if(e.getValue().count > 0) {
list.add(prefix);
}
getSortedWords(e.getValue(), list, prefix);
}
}
public String getMaxCommonPrefix() { //获取最大公共前缀
TrieNode node = root;
String maxPrefix = StringUtils.EMPTY;
while(node.son.size() == 1 && node.count == 0) {
for(Map.Entry<Character,TrieNode> e: node.son.entrySet()) {
node = e.getValue();
maxPrefix += e.getKey();
}
}
return maxPrefix;
}
public static void main(String[] args) { //测试
Trie trie = new Trie();
// trie.add("he");
trie.add("hf");
trie.add("hfz");
trie.add("hfz");
trie.add("hfz");
trie.add("hfzy");
// trie.add("hg");
// trie.add("eh");
// trie.add("eh");
// trie.add("ek");
System.out.println(trie.countWord("hfz"));
System.out.println(trie.countPrefix("hfz"));
System.out.println(trie.contain("eh"));
System.out.println(trie.getSortedWords());
System.out.println(trie.getSortedWordsAndCounts());
System.out.println(trie.getMaxCommonPrefix());
}
}
复制去Google翻译
翻译结果