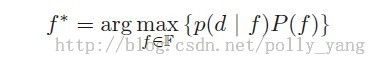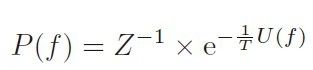之前自己做实验也用过MRF(Markov Random Filed,马尔科夫随机场),基本原理理解,但是很多细节的地方都不求甚解。恰好趁学习PGM的时间,整理一下在机器视觉与图像分析领域的MRF的相关知识。
打字不易,转载请注明。http://blog.csdn.net/polly_yang/article/details/9716591
在机器视觉领域,一个图像分析问题通常被定义为建模问题,图像分析的过程就是从计算的观点来求解模型的过程。一个模型除了可以表达成图形的形式外,通常使用一个目标函数来表示,因此建模的过程就是定义目标函数的过程,模型求解的过程也就是利用各种优化工具或者知识来解目标函数的过程。之所以需要使用各种优化工具,是因为在处理过程中存在着各种各样的不确定性,使用优化工具可以比较客观真实的模拟模型解。
首先,我们需要理解一个术语Contextual constraints,这个词的中文翻译为上下文约束。最早在图像分析和模式识别领域使用图像的contextual information信息,可以追溯到1962年(Chow, C. K. (1962). ``A recognition method using neighbor dependence", "IRE Transactions on Electronic Computer'', 11:683--690.)。在这篇文章中,Chow将字符识别问题看做一个统计决策问题,并使用了图像中相邻像素间的依赖关系,这个假设打破了之前对于统计独立的假设。
在解释视觉信息时,Contextual constraints是必须的。我们可以从图像中像素的空间和视觉上下文(比如车在路上跑,飞机停在飞机场中)来理解场景;也可以利用low-level来制作feature描述物体,再利用feature的上下文语义识别物体;高层特征可以通过对底层特征的抽象得到;底层特征可以通过图像中像素间最基本的位置关系得到。在这所有的抽象过程中,Contextual constraints都必不可少。
那么,为什么MRF适用于图像分析呢?首先给个假大空的说法:MRF理论提供了一个方便且具有一致性的建模方法。不管是有上下文依赖关系的实体(如图像像素),还是具有内在联系的features,MRF通通都能搞定。接下来,就来啃啃为什么MRF在机器视觉和图像理解领域具有那么多的应用,发了那么多paper吧。
一 图像分析中的labeling问题
labeling问题是机器视觉和图像分析领域的基本问题了。图像分割,目标识别等问题都可以看做是labeling的问题的延伸。简单的讲,图像的labeling就是将一组标签(labels)赋给图像中的每个像素。
1.1 The Labeling Problem
令L代表所有的标签集合(label set),S代表需要被赋予标签的元素的集合,比如S代表一张图像。当我们需要进行边缘检测时,问题就转化成了从L={edge, nonedge}中选择一个标签赋予S中的任一元素s,此时S代表图像,s代表图像中中某个像素。如此这般,我们能够得到由S中所有像素s的标签构成的集合f={f1,,,, fn},n与S的像素数一致。f的取值生成过程,可以看做是一个函数在离散定义域S上的求值过程: f : S --->L,也就是说,f是一个从S到L的映射(Mapping)。作为随机场的术语,labeling也被叫做“configuration”,这个实在不知道怎么翻译。在计算机视觉领域,configuration或者labeling问题都可以和图像,边缘图像,图像特征,物体特征或者是物体的姿态转移矩阵相对应。
上面的标签问题隐含了一个假设:对于S中任一元素s,它的label只能在L中取值。如果有S中有n个像素,L中有M种取值,那么f一共有多少种取值呢?M^n种。那么如果对于像素s,每一次label时,L集合都不一样呢?我们用Li表示第i次label过程时的label set,那么有F=L1 x L2 x ...x LM。注意这个表达式!
根据变量的规律性和连续性,我们可以将视觉label问题分为以下四类:
LP1:Regular s,continuour labels;
LP2:Regular s,discrete labels;
LP3:Irregular s,discrete labels;
LP4:Irregular s,continuous labels。
前两种可以看做是图像分析里的底层处理(low-level processing)-像素级和像素级特征;后两种可以看做是针对提取特征的高层处理(high-level processing)。图像复原或者图像平滑可以看做是LP1型问题。S是图像的像素,L是一个实整形变量。二值图像或者多通道图像的复原可以看做是LP2型问题。与连续复原类似,目标是估计从输入图像估计真实图像信号。不同之处在于结果图像的每个像素的像素值是离散值并且L也是离散值的集合。Region segmentation(图像的分割问题)也可以看做是LP2型问题。分割就是将输入图像分成几个不同的区域,每个区域内的像素具有统一或者相似的特性,例如亮度(gray)相近,颜色(color)相近,纹理(texture)相似。每个区域的像素可以看做是具有相同label。图像的边缘检测可以看做是LP2型问题。每一条边上的像素周围都有若干个非边缘的像素,根据梯度或者其他度量,可以判断一个像素是不是属于一条边缘{edge, nonedge}。基于特征的物体匹配或识别可以看做LP3型问题。每一个s可以看做是图像特征的索引,图像的特征可以是点,线段或者区域。问题转化为从图像特征到物体模型的映射。姿态估计(Pose estimation)可以看做是LP4问题,这个不怎么了解,暂时先不介绍。
1.2 使用Contextual constraints进行labeling
Contextual constraints常被用来建模成条件概率,比如P(fi|fi'),这里fi'可以代表i'位置的label。因为局部的信息更容易被直接观察到,因此很自然使用局部属性(local properties)来做全局推理。
当所有label都相互独立时,全局labels的联合概率可以写成:
P(f)= P(f1)*P(f2)*...P(fi)...P(fn)
刚才提到的条件概率也可以简化为: P(fi|{fi'})=P(fi) i'不等于i。
因此,一个全局的labeling问题f,可以通过局部labeling fi来计算得到。这是Contextual constraints的优势。
1.3 基于优化的方法
优化(Optimization)在图像分析领域一直扮演着关键的角色。一个问题可以表述成为优化一些指标的过程。优化问题之所以能有如此广泛的应用,一方面是因为它能处理成像和视觉领域的众多不确定性,例如大气湍流对遥感成像的影响,人工解译遥感图像时受人眼限制造成的含糊不清的情况。很多现实问题都不存在有精确且完美的解决方案,优化给我们提供了某种意义上的解决方案的替代品。
在众多利用优化来解决机器视觉和图像问题分析的paper中,问题的解决方案都被显示定义为一个目标函数的优化过程。此外,优化可以能会隐式执行,例如Hough Transform(Hough 1962; Duda and Hart 1972; Ballard 1981; Illingworth and Kittler 1988)。Hough Transform常用来检测直线和曲线。开始时,Hough Transform是通过检测累积函数的峰值。后来(Stockman and Agrawala 1977)发现这个方法 等同于模板匹配(template matching);(Haralick and Shapiro 1992)将问题转化为最大化似然概率。之后,边缘检测还被定义为使用某些简单的运算子,例如Gaussian 算子,Sobel算子等。
传感器成像和传输信号时,由于物理原因会导致图像中包含不确定的噪声和干扰;利用优化模型可以很好的解释这个问题。图像中,同一物体通常呈现不同的形状,例如,握着拳头的手和五指伸开的手;图像或遥感图像中,由于其他物体遮挡造成的物体轮廓的不完整性。在这些情况下,精确而完善的解决方案仅仅是空中楼阁,远不如寻找不精确但目前最佳的解决方案,这就是优化的魅力所在。
1.3.1 优化的背景知识
优化通常包含三件事:问题表述,目标函数和优化算法。
问题表述包含两个层次:描述和形式化计算。前者重点在于如何表述(represent)图像特征和物体形状。后者关注如何表述解决方案,这跟S和L的选择有关。例如在图像分割问题里,我们可以选择使用链式边界的位置表述解决方案;也可以使用区域的掩码(region map)来做同样的工作。特别的,使用区域的掩码更适宜使用MRF模型。
第二件事是如何形式化表示优化的目标函数。目标函数将解决方案映射到实际计算空间,并且可以衡量解决方案的质量,或者损益。这个形式化表述决定了变量如何相互约束,例如像素的亮度属性如何跟相邻像素有关等等。
第三件事是如何优化目标,例如如何在问题空间寻找优化的解决方案。这里需要注意两点:(1)局部极小值存在于非凸函数的问题;(2)算法的空间复杂度和时间复杂度。这两者在某种程度上来讲相互矛盾,目前还有没算法能够高效获得全局解。
上述三件事相互联系。首先,表述的形式影响目标函数的形式并且影响搜索算法的设计。同时,目标函数的形式也影响搜索算法。例如,假设两个目标函数具有相同点作为唯一全局最优解,但是其中一个是凸的,但是另一个不是。那么凸的这个解更可能是我们希望的那个,因为它的求解搜索起来更方便。
1.3.2 老大难-能量函数的角色(Energy Functions)
之所以说这是老大难,因为研一时看了俩月的MRF,始终不能白为什么就非得有这么个玩意儿,到现在也理解得半生不熟的。能量函数的角色可以从两个假大空的方面来理解:(1)作为解决方案的全局质量评价的衡量标准;(2)作为一个最小化的解决方案的搜索过程的guide。作为代价(cost)的定量描述,能量函数通常期望是一个最小又最全局的解决方案。基于这种期望,我们在设计能量函数时应当朝着让能量函数简单小巧可爱的方向来表述。这个原则的专属术语叫“correctness of the formulation”,这个真心不知道是啥。
鉴别两种不同类的问题,可以尝试调试模型。例如,如果一个优化程序的输出不是期望的,那么可能有两个原因:(1)目标函数不正确;(2)局部最小化时有错。哪一个是真正的原因您就试去吧。
在实空间最小化的时候,例如,能量函数是平滑的凸函数时,全局最小化就可以等价为局部极小能量函数的梯度。但是,当问题非凸时,通常没有通用的方法来有效获得解。在假设验证的方法中,一系列高贵冷艳的有效算法都可以用爱生成假设解,例如Hough Transform,Interpretation tree search和几何散列等。在这些策略中,能量函数仅用作评估度量,而不是作为搜素guide。需要注意启发式搜索在优化问题中的作用。
1.3.3 目标函数的形式化表述
在模式识别领域,能量函数大致有两种形式:参数和非参数。在参数形式中,基础分部的类型是已知的,并且分布的参数有限固定。因此当参数设定时,能量函数的形式可以使用公式表述。非参数的方法也可以叫做分布树(distribution tree)方法,分布未知。因此,分布要么根据数据估计要么根据预先设定的具有若干未知参数的基函数估计得到。这个预先规定的基函数将决定能量函数的公式化形式。尽管我们以参数和非参数来划分,其实这两种形式本质上都有参数。这是因为在任何实例中,我们都需要决定参数来定义能量函数。
能量函数最为重要的两个要素也就呼之欲出:形式和参数,这两者也同时决定了优化问题的解决方案。形式依赖于解f和观察数据d,记作E(f|d)。参数集合记作θ,因此能量函数可以进一步写成E(f|d,θ)。通常,目标解记作f*。当参数作为能量函数定义的一部分时,目标解的求解过程可记作f*=arg minE(f|d),当参数不确定时,这个形式并不完整。这些参数应当提前被设定或者在计算过程中能够通过某些方法估计。这也是MRF模型的一个重要的研究方向。
成像系统的不确定性,使得概率和信息论有了用武之地。例如,当有关数据的一些分布知道,但是先验信息不知道时,我们可以使用maximum likelihood(ML,最大似然)准则。f* = arg max P(d | f)。另一方面,如果只有先验知识,那么maximum entropy(最大熵)就更适合:
 。
。
maximum entropy的准则基于如下事实:熵越大,可能性越大。(Jaynes 1982)
当先验和似然分布都已知时,可以通过贝叶斯准则来获得最好的结果(Therrien 1989)。贝叶斯 统计准则是参数估计和决策只是的重要基础,特别是MAP principle在机器视觉领域应用广泛。MAP也在MRF的模型优化中起着重要作用。
1.4 MAP-MRF Framework
MAP-MRF框架最早出现在1984年(Geman)。在这个框架 中,很多统计图像分析问题已经有所讨论。本节主要针对MAP-MRF的概念已经其在labeling问题中的基本应用来扯淡。
1.4.1 Bayes估计
在贝叶斯估计中,通常使用风险最小化的方法来获得优化估计。f*的贝叶斯风险(Bayes risk)可以定义为:
此处,d是观察到的数据,C(f*, f)是代价函数,P(f|d)是后验分布。首先,我们需要根据先验和似然计算后验分布。这里将用到贝叶斯定理:P(f|d)=p(d|f)P(f)/p(d),此处P(f)是labelings f 的先验概率;p(d|f)是观察数据d的条件pdf,也被叫做f对于d的似然函数;p(d)是d的密度,当给定d时,它是一个常量。
代价函数C(f*, f)决定了当truth是f*时估计f的代价。根据我们的定义,C可以使用f*和f之间的距离来度量:
C(f*, f) = || f* - f||^2
通常,还可以使用δ作为阈值,如果||f*-f||小于δ,那么C(f*, f)=0,反之,则等于1。此时,贝叶斯风险可记作:
当δ->0时,上式可简化为:R(f*) = 1-k*P*(f|d),k是所有||f*-f||<δ的点构成的集合的大小。最小化上式,等价于最小化后验概率。因此,最小化风险估计是:
f*=arg max P(f|d)。
这就是MAP估计。由于p(d)当d固定时是常量,因此P(f|d)正比于联合概率分布P(f, d),也等于p(d|f)*P(f)。最终MAP估计的公式化描述可以写作:
1.4.2 MAP-MRF labeling
在MAP-MRF 标记问题中,P(f|d)是MRF的后验分布。f的一个典型先验分布可以写作:
这里 是能量函数的先验。假设观测的值还需要加上一个高斯噪声,di = fi + ei,这里ei ∼ N(μ, σ2)。那么,思安分布可以写作:
是能量函数的先验。假设观测的值还需要加上一个高斯噪声,di = fi + ei,这里ei ∼ N(μ, σ2)。那么,思安分布可以写作:
此处,
 是先验能量。
是先验能量。
那么,后验概率可记作:
此处,
 是后验能量。
是后验能量。
这样,MAP估计就等价为寻找最小的后验能量函数:f*= arg min U(f|d)。这里只有一个参数需要估计σi。当参数确定时,U(f|d)也被确定,MAP-MRF的解也就明确了。
1.4.3 小结
MAP-MRF方法解决机器视觉问题的主要步骤如下:
1. 将视觉问题转换为labeling的问题,并确定是属于LP1-LP4中的哪一种,然后选择正确的MRF表示f。
2. 定义MAP解的后验能量函数。
3. 寻找MAP解。
二 MRF模型的数学描述
2.1 MRF和Gibbs Distributions
2.1.1 邻域系统(Neighborhood System)
如果把一副图像看做是一个PGM模型,那么图像中的每一个像素就代表PGM模型中的顶点。那PGM模型中顶点之间的边呢?邻域系统就是针对这种相邻位之间的概率依赖而设计的。在之前的文章中曾经提到过,马尔科夫性是指一个事件当前的状态只与它直接的原因(cause)有关,而其他事件无关,这里更多的体现的是时间上的马尔科夫性。那么转移到随机场(Random Filed)中,利用领域系统可以分析空间上的马尔科夫性,也就是说:一个像素点的特性,更可能受它周围像素的影响,与它距离越远的像素,对它的特性的影响越小。为了对这种关系建模,前人引入了“邻域系统”,定义了图像中一个像素(中心像素),受周围哪些像素(Neighbourhood)的影响。中心像素和相邻像素一起,构成的集合,称之为“Cliques”,国内常见的称呼是“组团”,我也实在不知道咋翻译好。
在上图中,x是图像中的任意位置的像素,紫色的点代表的是与x相距为dis1=1的所有相邻像素;淡蓝色的点代表的是与x相距为dis2=sqrt(2)的所有相邻像素。紫色和淡蓝色的点我们都可以称之为X的相邻像素。在具体应用中,选取以x为中心 ,多大范围内的点为x的相邻像素点,不是固定不变的。那么如何定义 邻域系统呢?
对于图像X中任意像素x,X的邻域系统可以记作N。那么N={Nx, x∈X},Nx代表x的相邻像素的集合;同时,相邻的关系还满足如下约束:
(1)x不属于Nx;(2)相邻关系是相互的,也就是说对于像素x和y,y∈Nx且 x∈Ny。
相邻像素的集合可以定义为:
Nx={y∈X | dis(x,y) < τ, y≠x},此处dis(x , y )通常采用欧几里得距离(Euclidean distance)。上图紫色的四个点N1-N4,也常被称为4邻域系统;紫色和淡蓝色的点N1-N7,常被称作 8邻域系统。图像X和邻域系统N一一对应,X包含所有的顶点,N根据相邻关系决定顶点间的连线。
“Clique”是与x有关的属于X的一个子集,更多的分析的是Nx里的几种依赖关系:(1)单点,x;(2)成对点,x和y,比如x和N1;(3)三相邻点组:x,y,z,例如x,N1,N2。一般来说这三种情况形成的集合被记作C1,C2,C3:
C1={x | x∈X};
C2={{x , y}|y∈Nx, x∈X};
C3={{x , y , z}|x,y,z∈X,并且三者互相邻近}。并且,由于x的邻域与y的邻域不完全相等,因此{x,y}与{y,x}不等价,以此类推。
综上所述,对于(X , N)的所有Clique为:
C=C1 U C2 U C3.....
2.1.2 MRF的定义
经过前面一堆乱七八糟的东西,终于要来认识下什么叫MRF了。令F={F1,.....,Fm}是一组定义在集合S上的随机变量,其中Fi代表在标签集L中的一个取值fi,Fi=fi代表取值为fi的事件,(F1=f1,...,Fm=fm)代表联合事件(joint event)。假设f={f1,....fm},那么刚才叙述的联合事件则可简记为F=f。对于离散的标签集合L,Fi=fi的概率记作P(Fi=fi),简称P(fi);联合事件的概率记作P(f)。对于连续的标签集合L,我们可以知道pdf p(Fi=fi)和p(F=f)。
对于一个邻域系统N,如果如下两条性质满足:
(1) P(f) >0 , 对任意的f。(非负性)
(2) P(fi| fs-{i})=P(fi|fNi)。(马尔科夫性)
那么,我们就称F是一个马尔科夫随机场。
上述(1)(2)中,S-{i}是i除i之外的所有点,如果对于图像来讲,i是其中一个像素,那么S-{i}就是除i之外的其他所有像素;fs-{i}代表的是S-{i}中的所有点的标签集合;fNi={fi'|i'∈Ni}表示点i的邻域的点的标签集合。
在利用MRF建模解决实际问题时,往往将使用多个MRF。比如在边缘检测时,一般会用到两个MRF模型,一个对像素建模,一个对边缘建模。
马尔科夫随机场的概念和思想,来源于随机过程中的马尔科夫过程。不过马尔科夫过程更多的是针对时间序列建模而MRF更多的针对的是空间关系建模。Besag于1974年指出了MRF中求联合概率方法的和条件概率方法的优缺点。首先,没有好的方法来根据条件概率求联合概率。其次 ,条件概率本身受制于不明且高度限制的条件 。第三,联合概率比条件概率更自然。这也是为什么目前大多数MRF都没有直接解MRF,而是多采用Gibbs采样的原因。Hammersley和Clifford于1971年证明了 MRF和Gibbs分布的等价性,这位解MRF中的联合概率提供了一种特别的方法。证明实在又臭又长,不讲了。
2.1.3 GRF相关
有了Hammersley和Clifford的理论后,MRF的计算就可以通过Gibbs采样来进行。在这之前,我们先来了解下GRF和Gibbs Distribution。
Gibbs Distribution也是一个概率分布,它的公式化定义为:
其中,
 ,Z是一个归一化常数,常被称为partition function;T是Temperature的简写,一般情况下T=1;U(f)是能量函数,等于所有可能的Clique的集合C的潜在能量的和,这个潜在能量的大小根据具体设定而有所不同。根据上述形式,可以看出Gaussian distribution是Gibbs distribution分布的一个特例。U(f)是MRF模型的核心
,Z是一个归一化常数,常被称为partition function;T是Temperature的简写,一般情况下T=1;U(f)是能量函数,等于所有可能的Clique的集合C的潜在能量的和,这个潜在能量的大小根据具体设定而有所不同。根据上述形式,可以看出Gaussian distribution是Gibbs distribution分布的一个特例。U(f)是MRF模型的核心
2.1.4
我们知道,两个label之间的上下文约束(Contextual constraints)可以算作是传递上下文信息的最低阶约束。这种约束,形式简单且计算量小。这种约束可以变成Gibbs的能量函数,一般被叫做“pair-site clique potentials”。之所以叫做这个名字,是因为:(1)这种约束的主要对象有两个;(2)对两个对象建模符合PGM对关系建模的思想;(3)以能量表示两个对象之间的关系,适用于GRF。
更多的,也可以考虑三个label之间的关系,等等。但是机器视觉里最常用的,仍旧以成对能量函数为主。此时,能量函数的形式可以写成:
这个式子也常备叫做二阶能量。U(f)决定了GRF或者MRF模型的不同之处。
一个简单的GRF或者MRF模型的例子是auto-models(Besag 1974):
这个模型能能够通过对fi的假设来进行分类。
对于最简单的二分类问题来说,L可以看做是取两个离散值0或者1。那么此时能量函数可以写作:
此处的β是i和i'的相互作用系数。如果N代表i的邻域集合,对于图像而言,当N代表4邻域集合时,auto-logistic model退化成为Ising model。此时条件概率:
很多前辈对于MRF模型的改进,都是基于设计特别的适用于实际应用场景的能量函数。上面的模型还有各种各样的变形,比如 auto-normal model(Gaussian MRF),auto-regression model等等。
三 CRF(Conditional Random Fields),条件随机场
(最最简单的MRF终于忽悠完了,终于轮到高端大气的CRF了。啊,好几天没动笔写,罪过罪过。)首先我们来复习一下MRF的核心思想:针对标签集合F中任一元素fi,其满足马尔科夫性:P(fi| fs-{i})=P(fi|fNi),也就是说fi只跟其领域系统的取值有关。对于图像的标记问题,MRF的应用可以看做根据周围图像像素的标签,来推测目标像素的标签。其实这里同样隐含着对图像底层信息的抽象,比如两个相邻像素亮度越接近,那么像素越有可能被给予相同的标签。这种抽象更多的体现在了能量函数U(f)的形式中。CRF由Lafferty于2001年提出,其核心思想是不仅考虑f的马尔科夫性,同时也将抽象信息作为一个观察层。对于观察数据集合D中任意元素d,标签集合F中任意 元素fi,如果每个fi都满足马尔科夫性:
那么我们称F为一个条件随机场。“条件”二字,更多的是强调CRF是直接对后验建模,而不是对先验或者似然建模。根据Gibbs等价性,我们也可将CRF写成:
CRF在图像分析中的应用比其在自然语言处理中的应用相对简单,它与MRF有两点主要的区别。(1)对于单点势能(unary potential),CRF包含所有的观测数据建模,而MRF仅对当前点计算;对于成对点势能(pairwise potential),CRF依旧包含所有点,而MRF仅包含观察数据di及其领域系统内点di'。
四 DRF (Discriminative Random Fileds),判别随机场
DRF由Kumar于2003年提出,它更多的是CRF的延伸。一方面,DRF只能用于二维的场景,比如图像;另一方面,DRF通过局部判别式分类器计算单点势能与成对点势能。

Kumar利用线性模型来重新定义了能量函数。
其中,σ[x]是logistic函数(例如,σ[x] = 1/(1+exp(-x))), α 和 β是需要学习的参数, δ(fi, fi‘� )是预测函数。