Apache Flink® 入门介绍以及编程模型
在业余时间经常来Flink官网查阅文档,零零散散的看不成系统,最近打算系统的做一下笔记。有官网主页我们便知道Flink是什么?
Apache Flink® is an open-source stream processing framework for distributed, high-performing, always-available, and accurate data streaming applications.
Flink是一个开源的分布式,高性能的,总是可用的,精确的流处理框架。

Introduction to Apache Flink®
下面是Flink和流处理的一个宏观概述,我们先看一下关于Flink的一个概念:
Dataflow Programming Model (数据流编程模型)
Levels of Abstraction(抽象层次)
flink支持不同层次的抽象开发流处理或批处理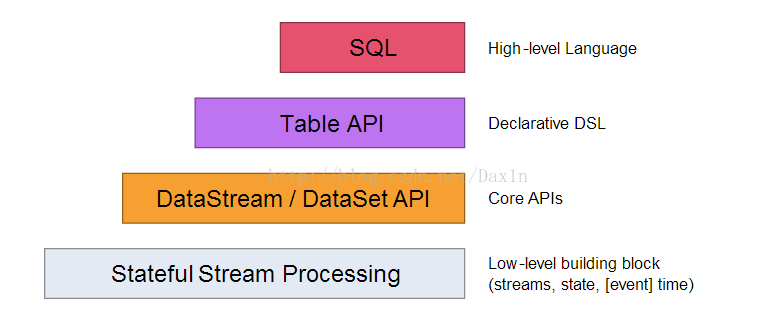
状态流处理: 底层接口,构建处理的数据Block
Core APIs:数据流/数据集的处理接口
Table API:声明特定域指定语言
SQL:高层次的语言
Programs and Dataflows
Flink构建程序块的基本方式就是使用streams和transformations(注意:DataSet在内部实现也是使用的streams的API)
。
概念上讲stream就是一个流数据记录,transformation就是将一个或者多个stream作为输入进行处理的操作算子,然后会产生一个或者多个输出streams作为结果。
当程序执行,Flink程序被映射成streaming dataflows,该streaming dataflows由stream和transformation算子组成。每一个dataflow由一个或者多个输入源并且有一个或者多个输出。dataflows类似于DAG( directed acyclic graphs).
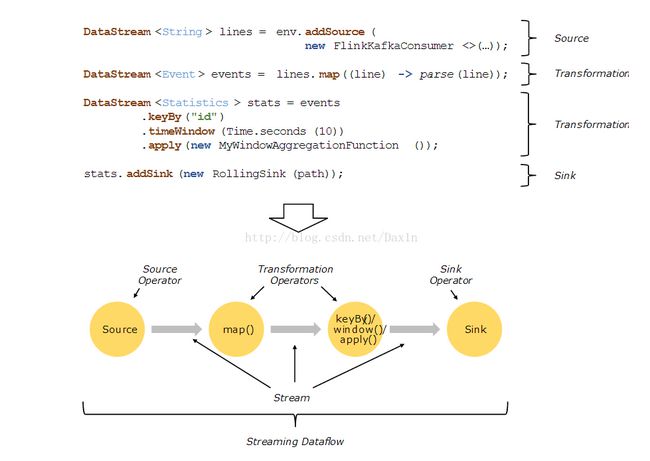
通常在Flink程序中,一个tramsformation和一个dataflow的操作符是一一对应的,但是有时候一个transformation可能包含多个transformation。
Parallel Dataflows
Flink程序必定是并行分布式执行,执行期间,一个stream有一个或者多个stream分区,每一个操作符有一个分区或者 operator subtasks,operator subtasks之间是相互独立的,执行在不同的线程中,或者不同的机器上或者容器中。
operator subtasks的数量是该操作符的并行度。一个stream的并行度由产生该stream的算子决定,同一个程序的不同操作符的并行度可能不同。
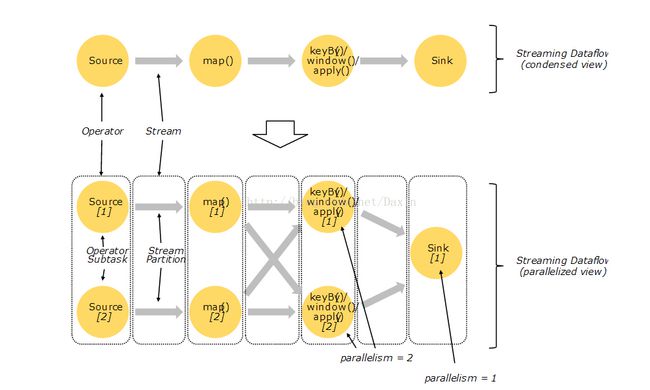
One-to-one streams (for example between the Source and the map() operators in the figure above) preserve the
partitioning and ordering of the elements.
Redistributing streams (as between map() and keyBy/window above, as well as between keyBy/window and Sink)
change the partitioning of streams.
Windows
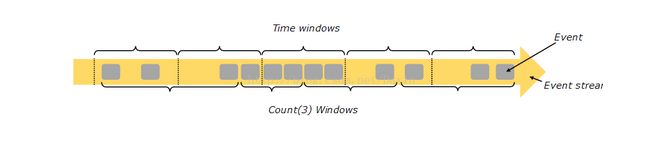
聚合事件在流上的处理不同于批处理。例如:由于流是无限的数据,因此就无法执行count计算所有元素个数,相反在count,sum算子可以计算在窗口上,例如:计算前五分钟或者计算上100个元素。
窗口大小可以有时间确定或者元素个数确定(例如上100个元素)。滑动窗口有:滚动窗口(没有重叠),滑动窗口(有重叠),和会话窗口
(punctuated by a gap of inactivity).
Time
当在streaming程序中提time一般指的是如下不同概念:
Event Time
:时间时间一般是指时间创建的时间,通常由一个时间戳描述事件,Flink访问时间戳可以通过timestamp assigners.
Ingestion time:摄入时间,一般是指一个时间进入Flink dataflow的源操作符时间
Processing Time :处理时间是本地时间,每一个操作符基于时间操作执行的时间
More details on how to handle time are in the event time docs
.
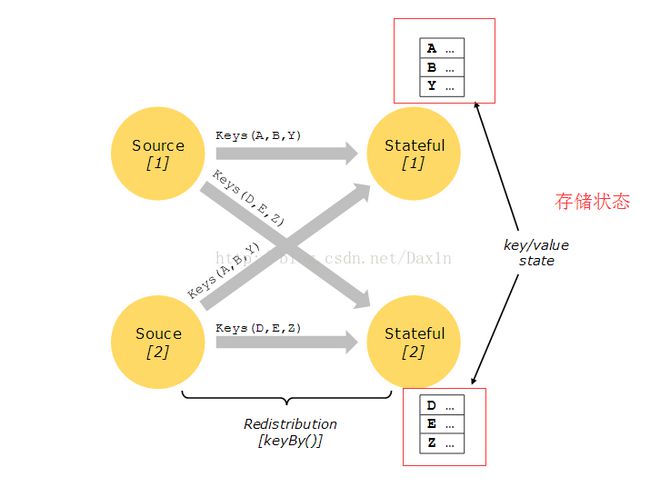
Stateful Operations
然而许多操作在dataflow看起来只是一个事件,但是有些操作需要记住多个事件的信息,这些操作我们称为有状态的。
有状态的操作的状态我们可以认为是保存在一个key/value的容器中。这些状态和读取状态的操作符存储在一起。
Checkpoints for Fault Tolerance
Flink实现stream repay和checkpoint实现容错,checkpoint可以理解为一个时间点的备份,当出错时候可以根据该点checkpoint进行恢复。Batch on Streaming
批处理是streaming的一个特例,批处理中stream是一个有边界的数据集,该数据集可以被看做是stream data,上述 适用于流处理的概念都适用于批处理, 但是有几个特例:
1:DataSet API不需要使用checkpoint,因为数据是有边界的,故障护恢复可以重新计算进行恢复,使用checkpoint恢复的成本一般大于常规的计算恢复成本。(对于DataSet的checkpoint的恢复成本较高)
2:
Stateful operations in the DataSet API use simplified in-memory/out-of-core data structures, rather than key/value indexes(没有理解).
3:The DataSet API introduces special synchronized (superstep-based) iterations, which are only possible on
bounded streams. For details, check out the iteration docs(没有理解).