Apache Storm 开发 零基础入门
Apache Storm 开发 零基础入门
作者:张航东
Linux:CentOS 7
Apache Storm:1.1.1
本文主要用于个人学习、总结,欢迎转载,但请务必注明作者和出处,感谢!
Apache Storm是一个免费、开源的分布式实时计算系统,关于其相关的介绍和安装网上的资料很多,大家可以自行baidu,这里就不重复介绍了。
本文主要是手把手的教大家,如何在零基础的情况下开启Apache Storm开发之路。
1 环境准备
有2种方式可以让我们开发的应用程序在Storm上运行,即:本地模式和远程模式
- 本地模式: 一般用于测试和开发阶段,即直接在Eclipse上运行storm和应用程序
- 远程模式:将应用程序打包部署到真实环境(需要先部署Storm)运行。
1.1 本地模式:
本地模式下,我们只需要在自己的电脑上安装 JDK 和 Eclipse 即可(剩下的让maven来搞定)。
1.2 远程模式:
远程模式下,我们需要至少一台Linux电脑/虚拟机,并在其上安装:
- JDK
- Zookeeper
- Apache Storm
即先要保证Apache Storm可以正常运行。
3 代码开发
这里,我们以统计英文字符个数(wordcount)为例。
3.1 Eclipse上创建工程
首先,创建一个maven的工程,工程名就叫“wordcount”。
工程创建好后,修改pom.xml文件,增加依赖,我们至少需要增加3个依赖:
1> Storm的依赖
<dependency> <groupId>org.apache.stormgroupId> <artifactId>storm-coreartifactId <version>1.1.1version> <scope>providedscope> dependency>2> 日志的依赖
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-apiartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-slf4j-implartifactId>
<version>2.7version>
dependency> 3> clojure的依赖(Storm是基于clojure开发的)
<dependency>
<groupId>org.clojuregroupId>
<artifactId>clojureartifactId>
<version>1.8.0version>
dependency>依赖添加好后,我们就可以正常开发了。
3.2 设计 Topology
在着手敲代码之前,先设计好 Storm 的 Topology,会让编码变的更简单,也更能体会到 Storm 的强大。
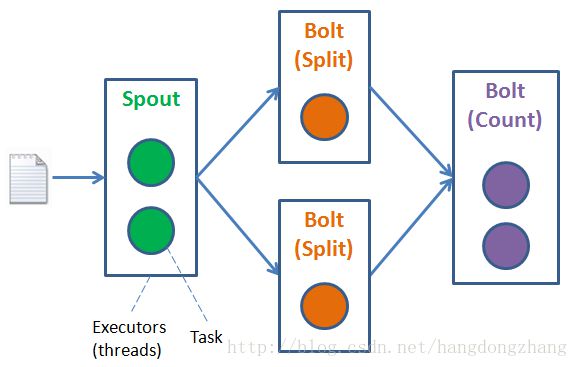
这里,我们设计了:
- 1个Spout线程(2个Task),用于从文件中(按行)读取字符串。
- 2个Split Bolt(各1个Task),用于(按空格)分隔字符串。
- 1个Count Bolt(2个Task),用于统计字符的个数。
3.3 编码
3.3.1 功能
根据设计,我们需要定义以下4个类:
Spout
主要功能:
1> 从文件中(按行)读取字符串
2> 将数据发送出去
3> 校验数据处理结果,并打印输出结果
Split Bolt
主要功能:
1> 获取数据
2> 处理数据(字符串),将其(按空格)分隔
3> 将处理后的数据发送出去
Count Bolt
主要功能:
1> 获取数据
2> 处理数据(字符),定义全局 Map 进行个数统计
TopologyDriver 类 (Main)
1> 构造 Topology,定义 Spout 和 Bolt 之间的数据流向
2> Topology 配置
3> 将 Topology 提交给 Storm 运行
3.3.2 代码
Spout
package org;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Map;
import org.apache.storm.shade.org.apache.commons.io.IOUtils;
import org.apache.storm.shade.org.apache.commons.io.LineIterator;
import org.apache.storm.shade.org.apache.commons.lang.StringUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Spout extends BaseRichSpout{
private static final long serialVersionUID = 76587948080518253L;
private static final Logger logger = LoggerFactory.getLogger(Spout.class);
private SpoutOutputCollector collector;
private LineIterator lineIterator;
private int index = 1;
// 打开文件
public void open(Map stormConf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
InputStream in = null;
try
{
in = new FileInputStream(new File("test.txt"));
if (in != null) {
this.lineIterator = IOUtils.lineIterator(in, "utf-8");
}
}
catch (Exception e) {
e.printStackTrace();
}
}
public void nextTuple() {
if (lineIterator != null && lineIterator.hasNext()) {
// 1 从文件中(按行)读取字符串
String line = lineIterator.next();
if (StringUtils.isNotEmpty(line)) {
// 2 将数据发送出去
Values values = new Values(line);
collector.emit(values, index++);
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
// 3 校验数据处理结果,并打印输出结果(成功时)
public void ack(Object msgId) {
logger.info(" ### A message has been done successfully !!! the msgId is " + (Integer)msgId);
logger.info("### The result is " + CountBolt.countedWord.toString());
}
// 3 校验数据处理结果,并打印输出结果(失败时)
public void fail(Object msgId) {
logger.error(" !!! A message was failed. the msgId is " + (Integer)msgId);
}
}Split Bolt
package org;
import org.apache.storm.shade.org.apache.commons.lang.StringUtils;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class SplitBolt extends BaseBasicBolt {
private static final long serialVersionUID = -5517905015897808351L;
public void execute(Tuple input, BasicOutputCollector collector) {
// 1 获取数据
String pickLine = input.getStringByField("line");
if (StringUtils.isNotEmpty(pickLine)) {
// 2 处理数据(字符串),将其(按空格)分隔
String[] splitStrs = pickLine.split(" ");
for (String str : splitStrs) {
// 3 将处理后的数据发送出去
// values对象会帮助我们生成一个list
Values values = new Values(str, 1);
collector.emit(values);
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}Count Bolt
package org;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
public class CountBolt extends BaseBasicBolt{
private static final long serialVersionUID = 5085772150587505422L;
public static Map countedWord = new HashMap();
public void execute(Tuple input, BasicOutputCollector collector) {
// 1 获取数据
String pickWord = input.getStringByField("word");
Integer pickNum = input.getIntegerByField("num");
// 2 处理数据(字符),定义全局 Map 进行个数统计
Integer num = countedWord.get(pickWord);
if (num == null || num == 0) {
countedWord.put(pickWord, pickNum);
} else {
countedWord.put(pickWord, pickNum.intValue() + num.intValue());
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
} Topology
package org;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TopologyDriver {
private static final Logger logger = LoggerFactory.getLogger(TopologyDriver.class);
public static void main(String[] args) throws Exception {
logger.error("#### I am starting ...");
// 1 构造 Topology,定义 Spout 和 Bolt 之间的数据流向
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new Spout());
builder.setBolt("split_bolt", new SplitBolt()).shuffleGrouping("spout");
builder.setBolt("count_and_print_bolt", new CountBolt(), 2).shuffleGrouping("split_bolt").setNumTasks(4);
StormTopology topology = builder.createTopology();
// 2 Topology 配置
Config conf = new Config();
//conf.setNumWorkers(2); //设置worker数量(即进程数)
// 3 将 Topology 提交给 Storm 运行
// 远程模式
//StormSubmitter.submitTopology("wordcount", conf, topology);
// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount", conf, topology);
}
}3.3.3 字符串文件
在 Spout 中我们定义的是读取 “test.txt” 文件中的字符串。
所以,我们需要在该工程的workspace的根目录下创建这个文件,并添加一些英文内容。
4 程序运行
在第1章节的时候,我们提到程序运行分为:本地模式和远程模式。
这个主要是在Class TopologyDriver 在“将 Topology 提交给 Storm 运行”时决定的。
// 远程模式
StormSubmitter.submitTopology("wordcount", conf, topology);// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount", conf, topology);4.1 本地模式
直接在Eclipse运行即可。
4.2 远程模式
注意:
1> 使用 StormSubmitter.submitTopology() 提交 Topology
2> 修改 “test.txt”文件的路径为目标机上的路径
将工程导出为 Jar 文件。
“File”-> “Export”->选择”Jave”下的”JAR File”
剩下的一路”Next”即可。
将该 Jar 文件和 “test.txt” 拷贝到目标机上(已安装并运行Storm)
启动
使用命令:
# storm jar wordcount.jar org.TopologyDriver查看输出结果
由于我们的程序是托管给Storm运行的,所以在我们无法再控制台看到打印的日志。
打印的日志存放在:
.../apache-storm-x.x.x/logs/workers-artifacts/wordcount-x-xxxxxxxx/xxxx/worker.log