Pandas读取与存储MySQL数据

01 前言
在许多工作应用中,常使用的文件来源于数据库。本节讲解Pandas解析MySQL数据库的方法,并学会MySQL数据库的存储方法。
这个是我们今天使用的MySQL数据。为我之前爬取的豆瓣电影数据。
02 Pandas读取MySQL数据
我们都知道,pandas读取csv用readcsv,读取Excel文件用readexcel,当然,读取数据库文件,可以用read_sql。
其方法的参数如下:
read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)我们常用的就是前两个参数:
sql 为可执行的sql语句
con为数据库的连接
为了读取mysql数据库,我们使用pymysql库(记得安装)来进行连接,然后使用read_sql读取即可。
conn = pymysql.connect(
host = 'localhost',
user = 'root',
passwd = '123456',
db = 'mydb',
port=3306,
charset = 'utf8'
)
df = pd.read_sql('select * from douban',conn)
df.head()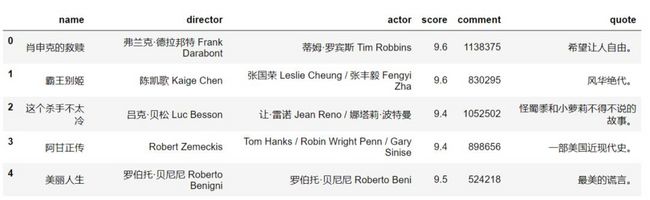
03 Pandas存储MySQL数据
同样的,存储数据的方法有tocsv,toexcel等,那要将DataFrame存储到数据库中,我们同样可以使用to_sql方法来完。
其方法的参数如下:
to_sql(name, con, flavor=None, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)(1)name参数为存储的表名;(2)con参数为连接数据库,这里和读取有区别,不能用pymysql连接;(3)if_exists参数用于判断是否有重复表名。填写fail表示:如果有重复表名,就不保存。填写replace用作替换。填写append,就在该表中继续插入数据。
df[:9].to_sql(name='test',con='mysql+pymysql://root:123456@localhost:3306/mydb?charset=utf8',if_exists='replace',index=False)
注意:如果报错,可能是因为数据库高于5.7版本的原因,需要更新pymysql库。
今天的分享就到这了,我们下期再见~