十大经典排序算法 讲解,python3实现
接受各位指出的错误
重点推荐!!!
这个网址可以看到各个算法的运行的直观过程,找到sort
勉强推荐这个吧,前面的几个算法图解还好,后面的几个就不好了
算法概述
这部分内容来自这么大牛
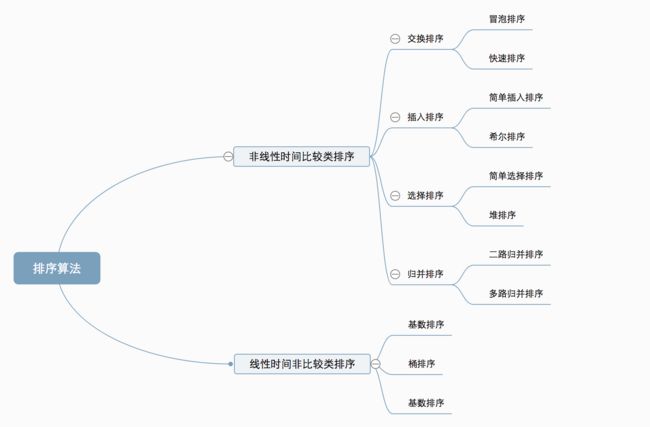
算法分类
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
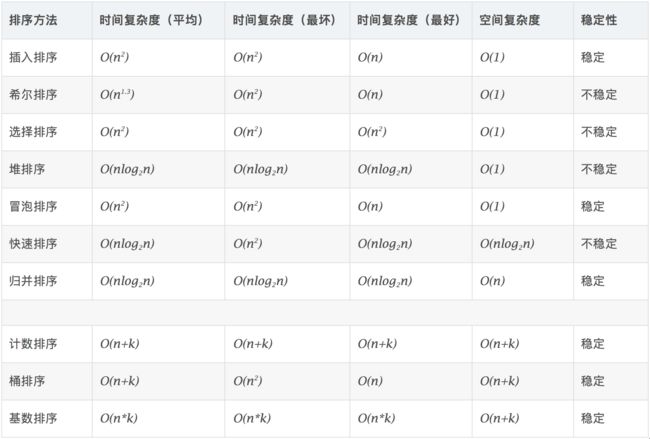
算法复杂度
这个图不是很好,维基百科给的图解非常好
相关概念
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
基于比较的排序算法
冒泡排序(Bubble Sort)
算法思想
冒泡排序算法的运作如下:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
python3 实现
def bubble_sort(nums,reverse=False):
''' 冒泡排序 其时间复杂度是:冒泡排序的时间复杂度为O(n^2)。 :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(len(nums)):
for j in range(0,len(nums)-i-1):
if reverse:
if nums[j]<nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
else:
if nums[j]>nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
选择排序(Selection Sort)
算法思想
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对 n个元素的表进行排序总共进行至多 n-1次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
python3 实现
def select_sort(nums,reverse=False):
''' 选择排序 其时间复杂度是:O(n^2)。 :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(len(nums)-1):
index = i
for j in range(i+1,len(nums)):
if reverse:
if nums[j] > nums[index]:
index = j
else:
if nums[j]<nums[index]:
index=j
if index!=i:
tmp=nums[i]
nums[i]=nums[index]
nums[index]=tmp
插入排序(Insertion Sort)
算法思想
插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
设有一组关键字{K1, K2,…, Kn};
排序开始就认为 K1 是一个有序序列;
让 K2 插入上述表长为 1 的有序序列,使之成为一个表长为 2 的有序序列;
然后让 K3 插入上述表长为 2 的有序序列,使之成为一个表长为 3 的有序序列;
依次类推,最后让 Kn 插入上述表长为 n-1 的有序序列,得一个表长为 n 的有序序列。
具体算法描述如下:
从第一个元素开始,该元素可以认为已经被排序
取出下一个元素,在已经排序的元素序列中从后向前扫描(所以其才是稳定算法)
如果该元素(已排序)大于新元素,将该元素移到下一位置
重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
将新元素插入到该位置后
重复步骤 2~5
时间复杂度是:O(n^2)。
python3实现
def insert_sort(nums,reverse=False):
''' :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(1,len(nums)):
for j in range(i-1,-1,-1):
if reverse:
if nums[j]<nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
else:
break
else:
if nums[j]>nums[j+1]:
tmp = nums[j + 1]
nums[j + 1] = nums[j]
nums[j] = tmp
else:
break
希尔排序(Shell Sort)
算法思想
希尔排序的实质就是分组插入排序,该方法又称缩小增量排序
基本思想是:
将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序
然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时
再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
算法思路:
先取一个正整数 d1(d1 < n),把全部记录分成 d1 个组,所有距离为 d1 的倍数的记录看成一组,然后在各组内进行插入排序
然后取 d2(d2 < d1)
重复上述分组和排序操作;直到取 di = 1(i >= 1) 位置,即所有记录成为一个组,最后对这个组进行插入排序。一般选 d1 约为 n/2,d2 为 d1 /2, d3 为 d2/2 ,…, di = 1。
python3 实现
def shell_sort(nums,reverse=False):
''' :param nums: 一个list :param reverse: :return: 无需返回 已经在原来的数组上进行修改 '''
step=len(nums)//2 #注意 取商
while step>0:
for i in range(step,len(nums)):#这里的述写方法是没错的 不理解的可以去这篇博客找解答
j=i-step
while j>=0:
if reverse:
if nums[j+step] > nums[j]:
tmp=nums[j]
nums[j]=nums[j+step]
nums[j+step]=tmp
j-=step
else:
break
elif nums[j+step] < nums[j]:
tmp=nums[j]
nums[j]=nums[j+step]
nums[j+step]=tmp
j-=step
else:
break
step=step//2
归并排序(Merge Sort)
算法思路
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,
该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
python3实现
def merge_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 返回已经排序好的数组 '''
def merge(l_list,r_list):
res=[]
i=0
j=0
while i<len(l_list) and j<len(r_list):
if reverse:
if l_list[i]>r_list[j]:
res.append(l_list[i])
i+=1
else:
res.append(r_list[j])
j+=1
else:
if l_list[i]<r_list[j]:
res.append(l_list[i])
i+=1
else:
res.append(r_list[j])
j+=1
if i<len(l_list):
res.extend(l_list[i:])
if j<len(r_list):
res.extend(r_list[j:])
return res
if len(nums)<=1:
return nums
mid=len(nums)//2
l_nums=MergeSort.merge_sort(nums[:mid],reverse)
r_nums=MergeSort.merge_sort(nums[mid:],reverse)
res=merge(l_nums,r_nums)
return res
快速排序(Quick Sort)
算法思路
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,
快速排序是一种划分交换排序。它采用了一种分治的策略,通常称其为分治法
基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
挖坑填数+分治法:
python3实现
@staticmethod
def quick_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 在原有的nums上进行修改 没有返回 '''
def quickSort(nums, left, right,reverse):
if left >= right:
return
low = left
high = right
key = nums[low]
while left < right:
if reverse:
while left < right and nums[right] <= key:
right -= 1
nums[left] = nums[right]
while left < right and nums[left] > key:
left += 1
nums[right] = nums[left]
else:
while left < right and nums[right] > key:
right -= 1
nums[left] = nums[right]
while left < right and nums[left] <= key:
left += 1
nums[right] = nums[left]
nums[right] = key
quickSort(nums, low, left-1,reverse) #这地方一定要注意 left-1 !!!!!!!!!!!!!!!!!!!!!
quickSort(nums, left + 1, high,reverse) # left + 1 这地方一定要注意!!!!!!!!!!!!!!!!!!!!!
return quickSort(nums,0,len(nums)-1,reverse)
堆排序(Heap Sort)
算法思路
需要知识
必须看得:!!!在学习该算法之前一定要在这篇博客中学习堆的相关必须知识
堆:
存储:一般采用数组进行存储 是一个"近似完全二叉树" 节点i 其父节点为(i-1)/2 左右子节点2i+1;2i+2
插入:将数据插入到最后一个
删除:删除第一个元素,同时将最后一个元素换到第一个个位置 再进行最大堆调整
堆排序:
最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
创建最大堆(Build Max Heap):将堆中的所有数据重新排序
堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
python3实现
@staticmethod
def heap_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 所有的操作均在nums数组上修改得,没有返回 '''
def sift_down(root, end):
""" 这个函数的作用 每次执行 都是为了让这个 nums[root],插入到正确的位置 最大堆调整: 针对的是每个内节点 叶子节点默认都是最大堆 然后 我们保证每个以内节点为跟的子树都是"最大堆" 思路:下沉 """
while True:
if root > end:
break
child = 2*root+1
if child>end:
break
if child+1 <= end and nums[child]<nums[child+1]:#注意这里的是 最大堆调整
child+=1
if nums[root]<nums[child]:
nums[root],nums[child]=nums[child],nums[root]
root=child
else:
break
for index in range((len(nums)-2)//2,-1,-1):#我们只需要对内节点实施 最大堆调整,叶子节点已经默认了是最大堆了
sift_down(root=index,end=len(nums)-1)
#这里已经是最大堆了
#下面是进行堆排序 我们这里首先按升序进行排序
for index in range(len(nums)-1,0,-1):#当剩余一个元素的时候,我们终止
nums[index],nums[0] = nums[0],nums[index]
sift_down(0,index-1)
if reverse:
for index in range(len(nums)//2): # 当剩余一个元素的时候,我们终止
nums[index], nums[len(nums)-1-index] = nums[len(nums)-1-index], nums[index]
基于非比较的排序的算法
计数排序(Counting Sort)
算法思想
这个算法我认为本身是非常简单的,我建议结合代码和博客同步开,不然不好理解呢
辅助理解博客,写的不算太好,不过可以看看
计数排序是一种基于非比较的排序算法,其空间复杂度和时间复杂度均为O(n+k),其中k是整数的范围。
基于比较的排序算法时间复杂度最小是O(nlogn)的。
注意:计数排序对于实数的排序是不可行的(博客中有解释的)
前面说了计数排序对于实数的排序是不可行的,这是因为我们无法根据最小值和最大值来确定数组C的长度,比如0.1和0.2之间有无限个实数。
但是如果限制实数精度,依然是可行的,比如说数组A中的数字只保留5位小数。
但是这已经不是实数了,相当于整数,因为相当于给原来数组A的所有数都乘以10^5。
python3实现
def count_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: '''
min_value=min(nums)
max_value=max(nums)
C=[0]*(max_value-min_value+1)
for token in nums:
C[token-min_value]+=1
i=0
for index,num in enumerate(C):
while num>0:
nums[i] = min_value+index
num-=1
i+=1
if reverse:
nums.reverse()
基数排序(Radix Sort)
直观理解
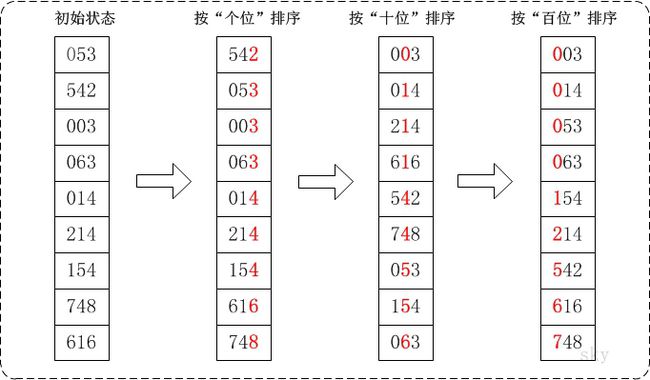
在上图中,首先将所有待比较树脂统一为统一位数长度,接着从最低位开始,依次进行排序。
- 按照个位数进行排序。
- 按照十位数进行排序。
- 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
算法思路
基数排序 (Radix Sort) 是一种非比较型整数排序算法
原理:
是将整数按位数切割成不同的数字,然后按每个位数分别比较。
排序过程:
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。
然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序法会使用到桶 (Bucket),顾名思义,将通过要比较的位(个位、十位、百位…),将要排序的元素分配至 0~9 个桶中,
借以达到排序的作用,在某些时候,基数排序法的效率高于其它的比较性排序法。
python3实现
def radix_sort(nums,reverse=False,radix=10):
import math
num_bit= math.ceil(math.log(max(nums),radix))
for bit in range(1,num_bit+1):
buckets = [[] for _ in range(radix)] # 这是由基数确定的桶
for num in nums:
index=num%(radix**bit)//(radix**(bit-1))
buckets[index].append(num)
del nums[:] #注意这里的方法 因为我们是在原数组的基础上进行修改的 所以 我们要保留引用地址
for bucket in buckets:
nums.extend(bucket)
if reverse:
nums.reverse()
桶排序(Bucket Sort)
算法理解
桶排序当待排序的数据是服从均匀分布的时候 速度是最快
桶排序的基本思想是:把数组 arr 划分为n个大小相同子区间(桶),每个子区间各自排序,最后合并。
计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。
具体的步骤:
1.找出待排序数组中的最大值max、最小值min
2.桶的数量我们选择的step有关。例如max=100,min=10,step=10那么,那么桶分别是
[10,20),[20,30),[30,40),[40,50)…[90,100),共有9个桶。计数排序就是特殊的一种桶排序,step=1
3.遍历数组 arr,计算每个元素 arr[i] 放的桶
4.每个桶各自排序
5.遍历桶数组,把排序好的元素放进输出数组
python3实现
def bucket_sort(nums,step=10,reverse=False):
''' :param nums: :param reverse: :return: '''
import math
max_val=max(nums)
min_val=min(nums)
buckets_num=math.floor((max_val-min_val)/step)+1
buckets=[[] for _ in range(buckets_num)] #这就是桶子
for num in nums:
index=math.floor((num-min_val)/step)
buckets[index].append(num)
del nums[:]
for bucket in buckets:
if len(bucket)>0:
MergeSort.insert_sort(bucket)
nums.extend(bucket)
以上所有的算法的代码整合
class MergeSort:
@staticmethod
def bubble_sort(nums,reverse=False):
''' 冒泡排序 其时间复杂度是:冒泡排序的时间复杂度为O(n^2)。 :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(len(nums)):
for j in range(0,len(nums)-i-1):
if reverse:
if nums[j]<nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
else:
if nums[j]>nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
@staticmethod
def select_sort(nums,reverse=False):
''' 选择排序 其时间复杂度是:O(n^2)。 :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(len(nums)-1):
index = i
for j in range(i+1,len(nums)):
if reverse:
if nums[j] > nums[index]:
index = j
else:
if nums[j]<nums[index]:
index=j
if index!=i:
tmp=nums[i]
nums[i]=nums[index]
nums[index]=tmp
@staticmethod
def insert_sort(nums,reverse=False):
''' 时间复杂度是:O(n^2)。 :param nums: 一个list :return: 无需返回 已经在原来的数组上进行修改 '''
for i in range(1,len(nums)):
for j in range(i-1,-1,-1):
if reverse:
if nums[j]<nums[j+1]:
tmp=nums[j+1]
nums[j+1]=nums[j]
nums[j]=tmp
else:
break
else:
if nums[j]>nums[j+1]:
tmp = nums[j + 1]
nums[j + 1] = nums[j]
nums[j] = tmp
else:
break
@staticmethod
def shell_sort(nums,reverse=False):
''' :param nums: 一个list :param reverse: :return: 无需返回 已经在原来的数组上进行修改 '''
step=len(nums)//2 #注意 取商
while step>0:
for i in range(step,len(nums)):#这里的述写方法是没错的 不理解的可以去这篇博客找解答
j=i-step
while j>=0:
if reverse:
if nums[j+step] > nums[j]:
tmp=nums[j]
nums[j]=nums[j+step]
nums[j+step]=tmp
j-=step
else:
break
elif nums[j+step] < nums[j]:
tmp=nums[j]
nums[j]=nums[j+step]
nums[j+step]=tmp
j-=step
else:
break
step=step//2
@staticmethod
def merge_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 返回已经排序好的数组 '''
def merge(l_list,r_list):
res=[]
i=0
j=0
while i<len(l_list) and j<len(r_list):
if reverse:
if l_list[i]>r_list[j]:
res.append(l_list[i])
i+=1
else:
res.append(r_list[j])
j+=1
else:
if l_list[i]<r_list[j]:
res.append(l_list[i])
i+=1
else:
res.append(r_list[j])
j+=1
if i<len(l_list):
res.extend(l_list[i:])
if j<len(r_list):
res.extend(r_list[j:])
return res
if len(nums)<=1:
return nums
mid=len(nums)//2
l_nums=MergeSort.merge_sort(nums[:mid],reverse)
r_nums=MergeSort.merge_sort(nums[mid:],reverse)
res=merge(l_nums,r_nums)
return res
@staticmethod
def quick_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 在原有的nums上进行修改 没有返回 '''
def quickSort(nums, left, right,reverse):
if left >= right:
return
low = left
high = right
key = nums[low]
while left < right:
if reverse:
while left < right and nums[right] <= key:
right -= 1
nums[left] = nums[right]
while left < right and nums[left] > key:
left += 1
nums[right] = nums[left]
else:
while left < right and nums[right] > key:
right -= 1
nums[left] = nums[right]
while left < right and nums[left] <= key:
left += 1
nums[right] = nums[left]
nums[right] = key
quickSort(nums, low, left-1,reverse)
quickSort(nums, left + 1, high,reverse)
return quickSort(nums,0,len(nums)-1,reverse)
@staticmethod
def heap_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: 所有的操作均在nums数组上修改得,没有返回 '''
def sift_down(root, end):
""" 这个函数的作用 每次执行 都是为了让这个 nums[root],插入到正确的位置 最大堆调整: 针对的是每个内节点 叶子节点默认都是最大堆 然后 我们保证每个以内节点为跟的子树都是"最大堆" 思路:下沉 """
while True:
if root > end:
break
child = 2*root+1
if child>end:
break
if child+1 <= end and nums[child]<nums[child+1]:#注意这里的是 最大堆调整
child+=1
if nums[root]<nums[child]:
nums[root],nums[child]=nums[child],nums[root]
root=child
else:
break
for index in range((len(nums)-2)//2,-1,-1):#我们只需要对内节点实施 最大堆调整,叶子节点已经默认了是最大堆了
sift_down(root=index,end=len(nums)-1)
#这里已经是最大堆了
#下面是进行堆排序 我们这里首先按升序进行排序
for index in range(len(nums)-1,0,-1):#当剩余一个元素的时候,我们终止
nums[index],nums[0] = nums[0],nums[index]
sift_down(0,index-1)
if reverse:
for index in range(len(nums)//2): # 当剩余一个元素的时候,我们终止
nums[index], nums[len(nums)-1-index] = nums[len(nums)-1-index], nums[index]
@staticmethod
def count_sort(nums,reverse=False):
''' :param nums: :param reverse: :return: '''
min_value=min(nums)
max_value=max(nums)
C=[0]*(max_value-min_value+1)
for token in nums:
C[token-min_value]+=1
i=0
for index,num in enumerate(C):
while num>0:
nums[i] = min_value+index
num-=1
i+=1
if reverse:
nums.reverse()
@staticmethod
def radix_sort(nums,reverse=False,radix=10):
import math
num_bit= math.ceil(math.log(max(nums),radix))
for bit in range(1,num_bit+1):
buckets = [[] for _ in range(radix)] # 这是由基数确定的桶
for num in nums:
index=num%(radix**bit)//(radix**(bit-1))
buckets[index].append(num)
del nums[:] #注意这里的方法 因为我们是在原数组的基础上进行修改的 所以 我们要保留引用地址
for bucket in buckets:
nums.extend(bucket)
if reverse:
nums.reverse()
@staticmethod
def bucket_sort(nums,step=10,reverse=False):
''' :param nums: :param reverse: :return: '''
import math
max_val=max(nums)
min_val=min(nums)
buckets_num=math.floor((max_val-min_val)/step)+1
buckets=[[] for _ in range(buckets_num)] #这就是桶子
for num in nums:
index=math.floor((num-min_val)/step)
buckets[index].append(num)
del nums[:]
for bucket in buckets:
if len(bucket)>0:
MergeSort.insert_sort(bucket)
nums.extend(bucket)
if __name__=="__main__":
nums=[31,13,19,41,151,23,85,55,5]
# MergeSort.bubble_sort(nums,True)
# MergeSort.select_sort(nums,True)
# MergeSort.insert_sort(nums,True)
# MergeSort.insertionSort(nums)
# print(MergeSort.merge_sort(nums,False))
# MergeSort.quick_sort(nums)
# MergeSort.heap_sort(nums,True)
# MergeSort.count_sort(nums,True)
# MergeSort.radix_sort(nums,True)
# MergeSort.bubble_sort(nums)
print(nums)