机器学习(周志华) 西瓜书 第四章课后习题4.6—— Python实现
机器学习(周志华) 西瓜书 第四章课后习题4.6—— Python实现
-
实验题目
试选择4个UCI数据集,对上述3种算法所产生的未剪枝、预剪枝、后剪枝决策树进行实验比较,并进行适当的统计显著性检验。
-
实验原理
因为4.3、4.4、4.5实现的程序鲁棒性很差,没有考虑到很多特殊情况,比如数据集有连续值、缺失值等,所以如果单存将其直接应用到UCI数据集上,可能程序会无法运行,或者准确率不高。所以采用sklearn中的决策树API实现本题,另外省略后剪枝这一复杂操作。
sklearn.tree.DecisionTreeClassifier
参数:
criterion:Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain. 划分选择类别:基尼指数,信息熵增益
min_impurity_decrease:A node will be split if this split induces a decrease of the impurity greater than or equal to this value. 判断是否预剪枝的阈值,如果优化值大于阈值,则不采用预剪枝,否则则采用预剪枝;默认值为正无穷
参考文档:传送门
sklearn.linear_model.LogisticRegression
参数
solver:Algorithm to use in the optimization problem. 选择对数几率回归模型中数值最优化算法,例如梯度下降法,牛顿法等
max_iter:Maximum number of iterations taken for the solvers to converge. 设置迭代次数,默认为100次
multi_class:If the option chosen is ‘ovr’, then a binary problem is fit for each label. For ‘multinomial’ the loss minimised is the multinomial loss fit across the entire probability distribution, even when the data is binary. 设置分类学习的种类,为二分类还是多分类
参考文档:传送门
-
实验过程
数据集获取
UCI数据官网:http://archive.ics.uci.edu/ml/index.php
选取最受欢迎的Iris数据集:
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
算法实现
划分数据集
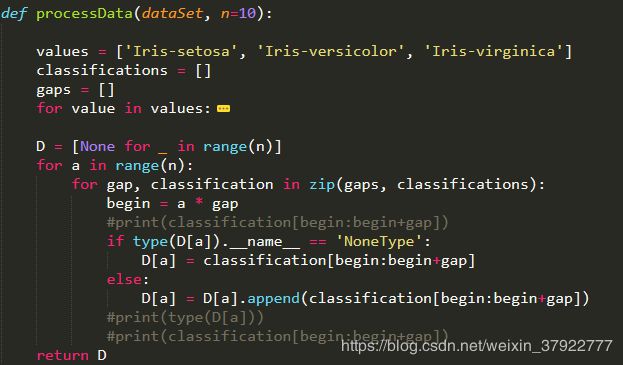
将数据集以样例类别比例划分成n等分,默认划分为10等分,但实际传入n=3,也就是将数据集划分为3等分,分别都是50个正例和50个反例;之所以分为3个等分,是为了让训练集分到2个等分,测试集获得1个等分,使其比例为2:1
运行函数
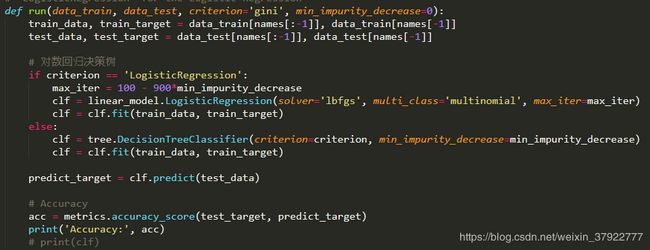
run函数为主要运行函数,传入的参数意义如下:
criterion: 选择决策树划分选择,'gini', 'entropy', 'LogisticRegression'
min_impurity_decrease: 选择是否预剪枝,默认值为0,即不剪枝
输出每次决策树预测的准确率;
主函数
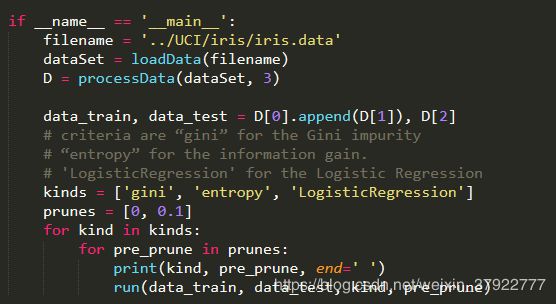
按划分选择,是否选择预剪枝组合,总共有6种情形。每个情形运行一次run函数;
-
实验结果
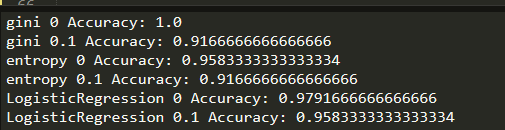
-
程序清单:
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn import linear_model
from sklearn import metrics
names = ['sepal length', 'sepal width', 'petal length', 'petal width', 'class']
def loadData(filename):
dataSet = pd.read_csv(filename, names=names)
return dataSet
# 将数据集划分中对等的训练集和测试集
def processData(dataSet, n=10):
values = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
classifications = []
gaps = []
for value in values:
temp = dataSet.loc[dataSet['class']==value]
classifications.append(temp)
gap = temp.shape[0]//n
gaps.append(gap)
D = [None for _ in range(n)]
for a in range(n):
for gap, classification in zip(gaps, classifications):
begin = a * gap
#print(classification[begin:begin+gap])
if type(D[a]).__name__ == 'NoneType':
D[a] = classification[begin:begin+gap]
else:
D[a] = D[a].append(classification[begin:begin+gap])
#print(type(D[a]))
#print(classification[begin:begin+gap])
return D
# criteria are “gini” for the Gini impurity
# “entropy” for the information gain.
# 'LogisticRegression' for the Logistic Regression
def run(data_train, data_test, criterion='gini', min_impurity_decrease=0):
train_data, train_target = data_train[names[:-1]], data_train[names[-1]]
test_data, test_target = data_test[names[:-1]], data_test[names[-1]]
# 对数回归决策树
if criterion == 'LogisticRegression':
max_iter = 100 - 900*min_impurity_decrease
clf = linear_model.LogisticRegression(solver='lbfgs', multi_class='multinomial', max_iter=max_iter)
clf = clf.fit(train_data, train_target)
else:
clf = tree.DecisionTreeClassifier(criterion=criterion, min_impurity_decrease=min_impurity_decrease)
clf = clf.fit(train_data, train_target)
predict_target = clf.predict(test_data)
# Accuracy
acc = metrics.accuracy_score(test_target, predict_target)
print('Accuracy:', acc)
# print(clf)
if __name__ == '__main__':
filename = '../UCI/iris/iris.data'
dataSet = loadData(filename)
D = processData(dataSet, 3)
data_train, data_test = D[0].append(D[1]), D[2]
# criteria are “gini” for the Gini impurity
# “entropy” for the information gain.
# 'LogisticRegression' for the Logistic Regression
kinds = ['gini', 'entropy', 'LogisticRegression']
prunes = [0, 0.1]
for kind in kinds:
for pre_prune in prunes:
print(kind, pre_prune, end=' ')
run(data_train, data_test, kind, pre_prune)