基于豆瓣影评数据的完整文本分析

♚
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
文本分析中很多的工作都是基于评论数据来进行的,比如:滴滴出行的评价数据、租房的评价数据、电影的评论数据等等,从这些预料数据中能够挖掘出来客户群体对于某种事物或者事情的看法,较为常见的工作有:舆情分析、热点挖掘和情感分析。
在之前的工作经历中,我对微博数据和电影评论数据进行文本分析工作较多,今天的文章主要就是想以影评数据为切入点介绍一些自己文本分析的流程和方法,本文简单的实现流程如下图所示:
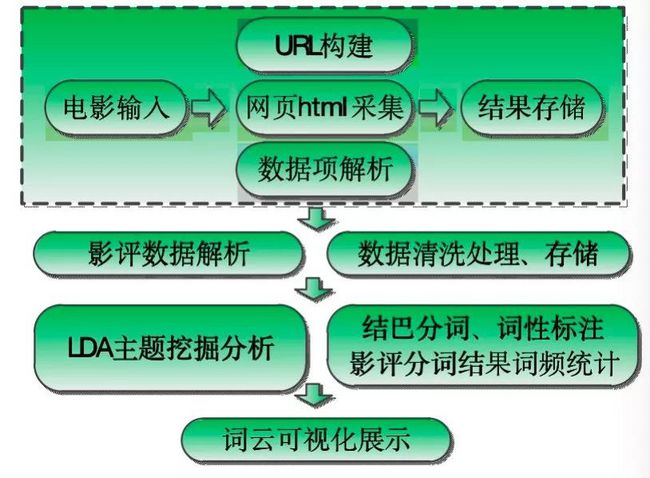
主要分为:数据采集、数据清洗存储、主题挖掘、分词与词频统计、词云展示几个部分。
一、影评数据采集
影评数据有很多网站可以去获取,比如最常用的猫眼电影、豆瓣电影等等,本文是基于豆瓣电影完成的数据采集工作,这个具体的采集项目网上都有很多详细的讲解与实现,这里我就不再对采集过程进行过多的介绍,直接看代码实现。
首选需要实现对于给定电影名称获取到其对应的id功能,因为在数据中电影数据项都是以id作为标识的,这里的代码实现很简单,主要是就是需要找到具体请求的API即可:
1.def getIMDBIdByName(name='勇敢的心',save_path='id_title.txt'):
2. '''''
3. 基于剧名查询获取 id
4. '''
5. url="https://movie.douban.com/j/subject_suggest?q="+urllib.quote(name)
6. data=getJsonData(url)
7. if data:
8. id_list=[one['id'] for one in data]
9. title_list=[one['title'] for one in data]
10. with open(save_path,'a') as f:
11. for i in range(len(id_list)):
12. f.write(','.join([id_list[i],title_list[i]]).strip()+'\n')
获取到的电影id会存储在我们默认的文件id_title.txt中,之后影评数据的获取会从这里读取数据来构建映射字典。
完成上述功能后我们就可以对给定名称的电影获取其对应的影评数据了,这里给出来样例爬虫代码的具体实现:
1.def demoSpider(movie_id='12345689',offset=0):
2. '''''
3. 爬虫数据展示
4. '''
5. res_list=[]
6. url="https://movie.douban.com/subject/{0}/comments?start={1}&limit=20&sort=new_score&status=P".format(movie_id,str(offset))
7. header,proxy=buildProxy()
8. res=getPageHtml(url,header,proxy,flag=True,num_retries=3)
9. soup=BeautifulSoup(res.content,'html5lib')
10. div_comment=soup.find_all('div',class_='comment-item')
11. for one in div_comment:
12. username=one.find('div',class_='avatar').a['title']
13. comment_time=one.find('span',class_='comment-time')['title']
14. votes=one.find('span',class_='votes').get_text()
15. comment=one.p.get_text()
16. one_list=[username.strip(),comment_time.strip(),votes.strip(),comment.strip()]
17. print one_list
18. res_list.append(one_list)
19. offset+=20
20. time.sleep(random.randint(3,8))
21. url="https://movie.douban.com/subject/{0}/comments?start={1}&limit=20&sort=new_score&status=P".format(movie_id,str(offset))
22. header,proxy=buildProxy()
23. res=getPageHtml(url,header,proxy,flag=True,num_retries=3)
24. soup=BeautifulSoup(res.content,'html5lib')
25. div_comment=soup.find_all('div',class_='comment-item')
26. for one in div_comment:
27. username=one.find('div',class_='avatar').a['title']
28. comment_time=one.find('span',class_='comment-time')['title']
29. votes=one.find('span',class_='votes').get_text()
30. comment=one.p.get_text()
31. one_list=[username.strip(),comment_time.strip(),votes.strip(),comment.strip()]
32. res_list.append(one_list)
33. return res_list
仔细看上述代码会发现,这里的实现是非常简单的,我们的翻页操作是基于网页的offset偏移量来间接完成的。上述代码实现了指定电影评论数据的采集工作。
如果在实际应用中出现大量数据采集工作的话需要考虑一些网站的反爬虫机制,这里我较为常用的三种反反爬虫机制主要包括:随机休眠机制、随机User-Agent伪装机制和动态IP代理池构建机制,如果对这方面感兴趣的话可以阅读我的头条号系列文章,搜索《反反爬虫机制三重奏》即可,这里我基于代码实现了随机UA和代理池的功能,具体不多解释了,直接看代码实现即可:
1.def buildProxy():
2. '''''
3. 构建代理信息
4. '''
5. header_list=generateRandomUA(num=500)
6. header={'User-Agent':random.choice(header_list)}
7. ip_proxy=random.choice(ip_list)
8. one_type,one_ip,one_port=ip_proxy[0],ip_proxy[1],ip_proxy[2]
9. proxy={one_type:one_type+'://'+one_ip+':'+one_port}
10. return header,proxy
二、影评数据清洗存储
完成第一部分的工作后,我们就采集到了所需的评论数据,但是这里的评论数据难以直接用于分析工作,我们需要对其进行解析处理后,对所需的评论文本数据进行清洗后才能够使用,这里简单对相关的工作进行说明。
我们随便打开一部电影《红海行动》的影评数据文件,找出前3条评论数据样例如下所示:
1.评论人:梦梦梦梦
2.评论时间:2018-02-16 00:05:42
3.支持人数:14673
4.评论内容:本来对这类电影不感兴趣,陪着男朋友去看的,很意外,还不错,一部很燃的片子,俩个多小时的电影,至少一个半小时的高潮,全程无尿点,据说是根据真实事件改编的,海陆空作战,超级帅。算是春节档电影的一股清流,大家真的要感受一下中国军人的风采,只想说威武!!佟莉炸飞机还有狙击手对战那段太帅了
5.评论人:乌鸦火堂
6.评论时间:2018-02-13 15:35:16
7.支持人数:10557
8.评论内容:春节档最好!最好不是战狼而是战争,有点类似黑鹰坠落,主旋律色彩下,真实又残酷的战争渲染。故事性不强,文戏不超20分钟,从头打到尾,林超贤场面调度极佳,巷战、偷袭、突击有条不紊,军械武器展示效果不错。尺度超大,钢锯岭式血肉横飞,还给你看特写!敌人如丧尸一般打不完,双方的狙击手都是亮点
9.评论人:sylvia晓霄小小
10.评论时间:2018-02-11 00:11:02
11.支持人数:7839
12.评论内容:超前点映场。场面真实,剧情紧凑。中间其实很想上厕所,但是愣是没有找到任何尿点…作为战争片,已超额完成任务,在真实度还原上,达到了国产影片从未有过的高度。细节处理也很妙,剥糖纸的那一段看的揪心。被海清和蒋璐霞的演技圈粉…看到最后,感觉自己整个人都在燃烧。准备春节的时候带着爸妈二刷。
13.评论人:华盛顿樱桃树
14.评论时间:2018-02-06 00:06:34
15.支持人数:10171
16.评论内容:国产类型片的里程碑,2个多小时节奏全程紧绷清晰,真热血真刺激。叙事,人物,情感,动作,制作都几乎无可挑剔。该有的都有,演员群像都比想象中出色,但最出色的还是导演。这个格局,超越某狼N倍。
分析发现:对于单条影评数据主要包含:评论人、评论时间、支持人数和评论内容四部分,我们需要的是评论内容,这里需要对原始获取到数据进行解析,具体实现如下:
1.def singeCommentParse(data='comments/1291546.txt',save_path='handle/1291546.json'):
2. '''''
3. 单个影评数据的解析处理
4. 数据样式:
5. 评论人:phoebe
6. 评论时间:2007-11-21 20:38:33
7. 支持人数:22660
8. 评论内容:陈凯歌可以靠它吃两辈子饭了,现在看来江郎才尽也情有可原
9. '''
10. with open(data) as f:
11. data_list=[one.strip() for one in f.readlines() if one]
12. comment_list=cutList(data_list,c=4)
13. res_list=[]
14. for i in range(len(comment_list)):
15. one_list=comment_list[i]
16. try:
17. one_dict={}
18. one_dict['person'],one_dict['timestamp'],one_dict['number'],one_dict['content']='N','N','N','N'
19. for one in one_list:
20. if one.startswith('评论人'):
21. one_dict['person']=one.split(':')[-1].strip()
22. elif one.startswith('评论时间'):
23. one_dict['timestamp']=one.split(':')[-1].strip()
24. elif one.startswith('支持人数'):
25. one_dict['number']=one.split(':')[-1].strip()
26. elif one.startswith('评论内容'):
27. one_dict['content']=one.split(':')[-1].strip()
28. res_list.append(one_dict)
29. except:
30. pass
31. with open(save_path,'wb') as f:
32. f.write(json.dumps(res_list))
33.
34.
35.def allCommentsHandle(dataDir='comments/',saveDir='handle/'):
36. '''''
37. 对整个目录下的影评数据全部处理
38. '''
39. if not os.path.exists(saveDir):
40. os.makedirs(saveDir)
41. txt_list=os.listdir(dataDir)
42. for one_txt in txt_list:
43. one_name=one_txt.split('.')[0].strip()
44. one_txt_path=dataDir+one_txt
45. one_json_path=saveDir+one_name+'.json'
46. singeCommentParse(data=one_txt_path,save_path=one_json_path)
上述代码实现了对所有电源原始评论数据的解析处理,执行后就得到了所需的评论内容数据。
完成解析处理后需要对影评内容数据进行清洗,这里的清洗我主要是去除评论数据中的特殊字符等信息,具体实现如下:
1.def dataClean(one_line):
2. '''''
3. 去脏、去无效数据
4. '''
5. with open('stopwords.txt') as f:
6. stopwords_list=[one.strip() for one in f.readlines() if one]
7. sigmod_list=[',','。','(',')','-','——','\n','“','”','*','#','《','》','、','[',']','(',')','-',
8. '.','/','】','【','……','!','!',':',':','…','@','~@','~','「一」','「','」',
9. '?','"','?','~','_',' ',';','◆','①','②','③','④','⑤','⑥','⑦','⑧','⑨','⑩',
10. '⑾','⑿','⒀','⒁','⒂','"',' ','/','·','…','!!!','】','!',',',
11. '。','[',']','【','、','?','/^/^','/^','”',')','(','~','》','《','。。。',
12. '=','⑻','⑴','⑵','⑶','⑷','⑸','⑹','⑺','…','']
13. for one_sigmod in sigmod_list:
14. one_line=one_line.replace(one_sigmod,'')
15. return one_line
到这里文本数据的预处理工作就结束了,之后需要对数据进行存储,这里我是直接将数据存储到了MySQL数据库中。
首先需要创建对应的表,具体实现如下:
1.def createTableMySQL(tablename='mytable'):
2. '''''
3. 创建表
4. '''
5. conn=pymysql.connect(**mysql)
6. cur=conn.cursor()
7. try:
8. drop_sql="drop table if exists %s" % tablename
9. cur.execute()
10. except Exception,e:
11. print 'Drop Exception: ',e
12. try:
13. create_sql="""CREATE TABLE %s (
14. movieId VARCHAR(50) NOT NULL,
15. movieName VARCHAR(50) NOT NULL,
16. personName VARCHAR(50) NOT NULL,
17. supportNum VARCHAR(50),
18. content VARCHAR(255),
19. timePoint VARCHAR(50) NOT NULL,
20. """ %(table)
21. cur.execute(create_sql)
22. conn.commit()
23. cur.close()
24. conn.close()
25. except Exception,e:
26. print 'createTableMySQL Exception: ',e
数据入库操作实现如下:
到此就完成了影评数据的清洗与存储工作!
三、LDA主题挖掘分析
这一部分主要是基于LDA主题挖掘模型来对处理好的影评数据进行主题倾向性的分析挖掘工作。具体实现如下所示:
结果输出如下:
1.{"蝶衣": 1, "记得": 1, "故事": 1, "哥哥": 6, "背景": 1, "作品": 2, "时代": 1, "真的": 1, "疯魔": 1, "女娇": 1, "霸王": 1, "说好": 1, "生活": 1, "角色": 1, "陈凯歌": 3, "电影": 6, "人生": 2, "风华绝代": 1, "成活": 1, "中国": 4, "喜欢": 1, "一年": 1, "人物": 1, "这部": 3, "一辈子": 2, "历史": 2, "时辰": 1, "经典": 3, "看过": 1, "感情": 1, "导演": 1, "程蝶衣": 6, "真虞姬": 1, "一部": 2, "霸王别姬": 2, "不算": 1, "关注": 1, "虞姬": 3, "一个月": 1, "永远": 1, "张国荣": 5, "一出": 1, "巅峰": 1, "之作": 1}

上述代码中我们数据的数据是《霸王别姬》的评论数据,输出的是对应的10个主题中主题词的词频数据。基于词云对其可视化结果如下所示:
接下来我们借助于主题可视化分析工具对其各个主题进行展示如下所示:
Topic0:

Topic1:

Topic2:

Topic3:
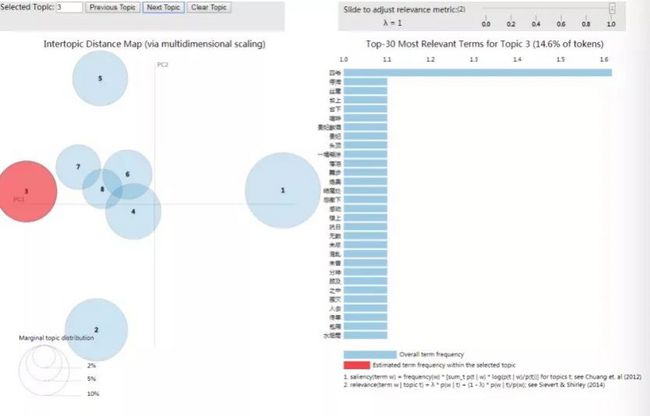
这里仅展示出前4个主题的分布情况,借助于可视化工具来呈现主题还是一种不错的方式。
四、分词与词频统计
这部分的工作主要是对原始的影评数据进行分词和词频统计,相对来说较为简单,就不多说明了,直接看代码实现即可:
1.def singleCommentCut(data='1291546.json',word_path='1291546.txt',fre_path='1291546.json'):
2. '''
3. 对单个影评数据清洗、分词处理
4. '''
5. with open(data) as f:
6. data_list=json.load(f)
7. content=[]
8. fre_dict={}
9. for one_dict in data_list:
10. one_clean=dataClean(one_dict['content'])
11. one_cut=seg(one_clean)
12. one_line='/'.join(one_cut)
13. content.append(one_line)
14. for one in one_cut:
15. if one in fre_dict:
16. fre_dict[one]+=1
17. else:
18. fre_dict[one]=1
19. with open(word_path,'w') as f:
20. for one_line in content:
21. f.write(one_line.strip()+'\n')
22. with open(fre_path,'w') as f:
23. f.write(json.dumps(fre_dict))
上述代码实现了对输入影评数据的分词与词频统计,并存储到本地文件中。
五、词云可视化分析
这里是本文的最后一个部分,主要是对前面几章中计算处理得到的文本数据进行可视化展示分析,对于文本数据的可视化我用的最多的也就是词云了,简单看下具体的效果吧。
原始影评数据词云可视化结果如下:
《我不是药神》

《流浪地球》

《肖申克的救赎》

《红海行动》

主题挖掘词云可视化分析结果如下:
《我不是药神》

《流浪地球》

《肖申克的救赎》

《红海行动》

对于完整影评数据的可视化来说更全面地展现出来了评论数据的信息,对于主题挖掘的可视化来说,突出了在广大评论数据中的主题倾向性。
到这里本文的工作就结束了,很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持,谢谢!
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY!