Java SE Primer——集合框架 完全解析
转载请注明出处:http://blog.csdn.net/smartbetter/article/details/51452313
Java集合类也被称为“容器类”,位于java.util包下,Java5之后还在java.util.concurrent包下提供了一些多线程支持的集合类。Java集合主要由两个接口派生而出:Collection和Map,如下图是Java集合类的思维导图(淡绿色圆角矩形框表示接口,淡灰色圆角矩形框表示实现类,实际开发最常用的我已经用红色五角星标注了,建议重点掌握其底层实现原理)。
建议:要养成阅读Java API和Java源码的习惯,这个很重要!

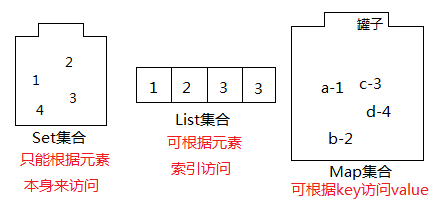
下面是集合关系的示意图,Map集合和Set集合就像是“罐子”,访问List集合元素可直接根据元素索引访问;访问Map集合元素可根据元素key来访问value;访问Set集合元素只能根据元素本身访问,这也是Set集合不允许重复的原因之一。
1.Map集合
Map(也被称为字典或关联数组)用于保存具有映射关系的数据(key-value),key不允许重复。从Java源码来看,Java先实现了Map,然后通过包装一个所有value都为null的Map就实现了Set集合。
1.HashMap
特点:无序;非同步;集合元素值允许为null。
来看看hash(哈希、散列)算法的功能:能保证快速查找被检索的对象,hash算法的价值在于速度,当查询某个元素时,hash算法可以直接根据该元素的hashCode值计算出该元素的存储位置,从而快速定位。下面示例了Map的基本功能。
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
// 成对放入多个key-value对,多次放入的key-value对中value可以重复
map.put("C", 100);
map.put("C++", 80);
map.put("Java", 90);
// 放入重复的key时,新的value会覆盖原有的value
map.put("Java", 70);
System.out.println(map); // 输出的Map集合包含3个key-value对
// 判断是否包含指定key
System.out.println("是否包含值为C++的key:" + map.containsKey("C++"));
// 判断是否包含指定value
System.out.println("是否包含值为90的value:" + map.containsValue(90));
// 获取Map集合的所有key组成的集合,通过遍历key来实现遍历所有key-value对
for (Object key : map.keySet() ) {
// map.get(key)方法获取指定key对应的value
System.out.println(key + ":" + map.get(key));
}
map.remove("C++"); // 根据key来删除key-value对。
System.out.println(map); // 输出结果不再包含C++=80 的key-value对
}
/** * 运行结果: * {C=100, C++=80, Java=70} * 是否包含值为C++的key:true * 是否包含值为90的value:false * C:100 * C++:80 * Java:70 * {C=100, Java=70} */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Java8也为Map新增了很多方法,例如replace()方法替换value值等,新特性建议多阅读API。
2.TreeMap
特点:有序;非同步;集合元素值允许为null。
红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap支持两种排序方式:自然排序和定制排序,TreeMap的使用方法这里不再详细给出,建议查看API文档学习。
2.各Map实现类的性能分析
速度对比:HashMap(最快) > Hashtable > TreeMap
对于一般场景,程序应多考虑使用HashMap,因为HashMap正是为快速查询设计的。
3.Collection和Iterator
1.操作Collection集合里的元素
public class CollectionTest {
public static void main(String[] args) {
Collection list = new ArrayList();
// 1.添加元素
list.add("Java");
list.add(6); // 虽然集合里不能放基本类型的值,但Java支持自动装箱
System.out.println("list集合的元素个数为:" + list.size());
// 2.删除指定元素
list.remove(6);
System.out.println("list集合的元素个数为:" + list.size());
// 3.判断是否包含指定字符串
System.out.println("list集合的是否包含\"Java\"字符串:" + list.contains("Java"));
list.add("Java EE");
System.out.println("list集合的元素:" + list);
Collection set = new HashSet();
set.add("Java EE");
set.add("Android");
System.out.println("list集合是否完全包含set集合?" + list.containsAll(set));
// 4.用list集合减去set集合里的元素
list.removeAll(set);
System.out.println("list集合的元素:" + list);
// 5.删除list集合里所有元素
list.clear();
System.out.println("list集合的元素:" + list);
// 6.控制set集合里只剩下list集合里也包含的元素
set.retainAll(list);
System.out.println("set集合的元素:" + set);
/** * 运行结果: * list集合的元素个数为:2 * list集合的元素个数为:1 * list集合的是否包含"Java"字符串:true * list集合的元素:[Java, Java EE] * list集合是否完全包含set集合?false * list集合的元素:[Java] * list集合的元素:[] * set集合的元素:[] */
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2.使用Lambda表达式遍历集合(Java8新特性)
Java8为Iterable接口新增了一个forEach(Consumer action)默认方法,所需参数为一个函数式接口,Iterable接口是Collection接口的父接口,所以Collection集合可以直接调用forEach方法。
public class CollectionEach {
public static void main(String[] args) {
// 创建一个集合
Collection set = new HashSet();
set.add("Java");
set.add("Java EE");
set.add("Android");
// 调用forEach()方法遍历集合
set.forEach(obj -> System.out.println("迭代集合元素:" + obj));
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.使用Iterator遍历集合元素
Iterator接口也被称为迭代器,向程序提供了遍历Collection集合元素的统一编程接口。对于遍历List集合元素,ArrayList最好使用随机访问方法(get)来遍历,这样性能最好;LinkedList则最好用迭代器(Iterator)来遍历集合元素。
public class IteratorTest {
public static void main(String[] args) {
// 创建集合、添加元素
Collection set = new HashSet();
set.add("Java");
set.add("Java EE");
set.add("Android");
// 获取set集合对应的迭代器
Iterator it = set.iterator();
while(it.hasNext()) {
// it.next()方法返回的数据类型是Object类型,因此需要强制类型转换
String s = (String)it.next();
System.out.println(s);
if (s.equals("Java EE")) {
// 从集合中删除上一次next方法返回的元素
it.remove();
}
// 对s变量赋值,不会改变集合元素本身
s = "哈哈哈";
}
System.out.println(set);
}
/** * 运行结果: * Android * Java EE * Java * [Android, Java] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
4.使用Lambda表达式遍历Iterator(Java8新特性)
public class IteratorEach {
public static void main(String[] args) {
// 创建集合、添加元素
Collection set = new HashSet();
set.add("Java");
set.add("Java EE");
set.add("Android");
// 获取set集合对应的迭代器
Iterator it = set.iterator();
// 使用Lambda表达式(目标类型是Comsumer)来遍历集合元素
it.forEachRemaining(obj -> System.out.println("迭代集合元素:" + obj));
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.使用foreach遍历集合元素
当使用foreach循环迭代访问Collection集合里的元素时,该集合不能被改变。
public class ForeachTest {
public static void main(String[] args) {
// 创建集合、添加元素
Collection set = new HashSet();
set.add(new String("Java"));
set.add(new String("Java EE"));
set.add(new String("Android"));
for (Object obj : set) {
// 此处的s变量也不是集合元素本身
String s = (String)obj;
System.out.println(s);
// if (s.equals("Android")) {
// // 当使用foreach循环迭代访问Collection集合里的元素时,该集合不能被改变
// 下面代码会引发ConcurrentModificationException异常
// set.remove(s);
// }
}
System.out.println(set);
}
/** * 运行结果: * Android * Java EE * Java * [Android, Java EE, Java] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.Set集合
HashSet和TreeSet是Set的两个典型实现。
1.HashSet(开发首选)
特点:无序;非同步;集合元素值允许为null。
HashSet判断两个元素相等的标准:两个对象通过equals()方法比较相等;两个对象的hashCode()返回值也相等。
HashSet的基本操作同Collection
2.TreeSet
特点:有序;非同步;集合元素值允许为null。
可以确保集合元素处于排序状态,TreeSet采用红黑树的数据结构来存储集合元素,支持两种排序方法:自然排序和定制排序,默认自然排序。如下示例了TreeSet的用法:
public class TreeSetTest {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
// 向TreeSet中添加四个Integer对象
treeSet.add(10);
treeSet.add(30);
treeSet.add(20);
treeSet.add(-15);
// 输出集合元素,看到集合元素已经处于排序状态
System.out.println(treeSet);
// 输出集合里的第一个元素
System.out.println(treeSet.first());
// 输出集合里的最后一个元素
System.out.println(treeSet.last());
// 返回小于25的子集,不包含25
System.out.println(treeSet.headSet(25));
// 返回大于10的子集,如果Set中包含10,子集中还包含10
System.out.println(treeSet.tailSet(10));
// 返回大于等于-10,小于20的子集
System.out.println(treeSet.subSet(-10 , 20));
}
/** * 运行结果: * [-15, 10, 20, 30] * -15 * 30 * [-15, 10, 20] * [10, 20, 30] * [10] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
5.各Set实现类性能分析
HashSet和TreeSet:
HashSet性能总是比TreeSet好,特别是添加、查询等操作,因为TreeSet需要额外的红黑树算法来维护集合元素次序。只有当需要一个保持排序的Set时才用TreeSet。
6.List集合
1.ArrayList
有序可重复,ArrayList是线程不安全的,当多个线程访问同一个ArrayList集合时,如果有超过一个线程修改了ArrayList集合,则必须手动保证该集合的同步性。ArrayList的基本操作同Collection。
2.LinkedList
有序可重复,既可以被当作“栈”使用,也可以当成队列使用。如下示例了LinkedList的用法:
public class LinkedListTest {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
// 将字符串元素加入队列的尾部
linkedList.offer("Java");
// 将一个字符串元素加入栈的顶部
linkedList.push("Java EE");
// 将字符串元素添加到队列的头部(相当于栈的顶部)
linkedList.offerFirst("Android");
// 以List的方式(按索引访问的方式)来遍历集合元素
for (int i = 0; i < linkedList.size(); i++ ) {
System.out.println("遍历中:" + linkedList.get(i));
}
// 访问、并不删除栈顶的元素
System.out.println(linkedList.peekFirst());
// 访问、并不删除队列的最后一个元素
System.out.println(linkedList.peekLast());
// 将栈顶的元素弹出"栈"
System.out.println(linkedList.pop());
// 下面输出将看到队列中第一个元素被删除
System.out.println(linkedList);
// 访问、并删除队列的最后一个元素
System.out.println(linkedList.pollLast());
// 下面输出:[Java EE]
System.out.println(linkedList);
}
/** * 运行结果: * 遍历中:Android * 遍历中:Java EE * 遍历中:Java * Android * Java * Android * [Java EE, Java] * Java * [Java EE] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
7.Queue集合
1.ArrayDeque
Deque接口实现了Queue接口,代表双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素。Deque接口提供了一个典型的实现类ArrayDeque,ArrayDeque是基于数组实现的双端队列,ArrayDeque不仅可以当成“栈”使用,而且还可以当成“队列”使用。
把ArrayDeque当成“栈”使用:
public class ArrayDequeStack{
public static void main(String[] args){
ArrayDeque stack = new ArrayDeque();
// 依次将三个元素push入"栈"
stack.push("Java");
stack.push("Java EE");
stack.push("Android");
System.out.println(stack);
// 访问第一个元素,但并不将其pop出"栈"
System.out.println(stack.peek());
System.out.println(stack);
// pop出第一个元素
System.out.println(stack.pop());
System.out.println(stack);
}
/** * 运行结果: * [Android, Java EE, Java] * Android * [Android, Java EE, Java] * Android * [Java EE, Java] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
把ArrayDeque当成“队列”使用:
public class ArrayDequeQueue {
public static void main(String[] args) {
ArrayDeque queue = new ArrayDeque();
// 依次将三个元素加入队列
queue.offer("Java");
queue.offer("Java EE");
queue.offer("Android");
System.out.println(queue);
// 访问队列头部的元素,但并不将其poll出队列"栈"
System.out.println(queue.peek());
System.out.println(queue);
// poll出第一个元素
System.out.println(queue.poll());
System.out.println(queue);
}
/** * 运行结果: * [Java, Java EE, Android] * Java * [Java, Java EE, Android] * Java * [Java EE, Android] */
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
8.各种线性表性能分析(包括List、Queue)
ArrayList和LinkedList:
由于数组以一块连续内存区保存所有数组元素,所以内部以数组作为底层实现的集合在随机访问时性能最好;而内部以链表作为底层实现的集合在执行插入、删除操作时有较好的性能。总体ArrayList性能优于LinkedList,大部分考虑使用ArrayList。
注意:
1.对于遍历List集合元素,ArrayList最好使用随机访问方法(get)来遍历,这样性能最好;LinkedList则最好用迭代器(Iterator)来遍历集合元素。
2.如果要经常插入删除大量数据的List,建议使用LinkedList。
9.操作集合的工具类Collections
Collections提供了大量方法对集合元素进行排序、查询、修改等操作。
List list = new ArrayList();
... // 添加集合元素
排序,Collections提供了用于对List集合元素进行排序的方法:
Collections.reverse(list); // 将List集合元素的次序反转
Collections.sort(list); // 将List集合元素的按自然顺序排序
Collections.shuffle(list); // 将List集合元素的按随机顺序排序
查找、替换:
Collections.max(list); // 获取List集合最大元素
Collections.min(list); // 获取List集合最小元素
Collections.replaceAll(list , 0 , 1); // 将List中的0使用1来代替(假设0、1为集合元素值)
Collections.frequency(list , 1); // 判断1在List集合中出现的次数(假设1为集合元素值)
Collections.binarySearch(list , 1); // 使用二分法搜索指定的List集合,以获得List集合中的索引,只有排序后的List集合才可用二分法查询
同步控制,下面程序创建了四个线程安全的集合对象:
Collection c = Collections.synchronizedCollection(new ArrayList());
List l = Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());
设置不可变集合:
List unList = Collections.emptyList(); // 创建一个空的、不可改变的List对象
Set unSet = Collections.singleton("Java"); // 创建一个只有一个元素,且不可改变的Set对象
Map map = new HashMap(); // 创建一个普通Map对象
map.put("HTML5" , 90);
map.put("CSS3" , 80);
Map unMap = Collections.unmodifiableMap(map); // 返回普通Map对象对应的不可变版本
// 下面任意一行代码都将引发UnsupportedOperationException异常
unList.add("C");
unSet.add("C");
unMap.put("C" , 100);
10.线程安全的集合
1.较早的线程安全集合
使用工具类Collections,上面已经提到过了:
/** * 同步控制 * 下面程序创建了四个线程安全的集合对象 */
Collection c = Collections.synchronizedCollection(new ArrayList());
List l = Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.高效的映射表、集合和队列
java.util.concurrent包提供了映射表、有序集和队列的高效实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、ConcurrentLinkedDeque。
这些集合使用复杂的算法,通过允许并发地访问数据结构的不同部分来使竞争极小化。