Java爬虫框架(一)--架构设计
一、 架构图
那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。
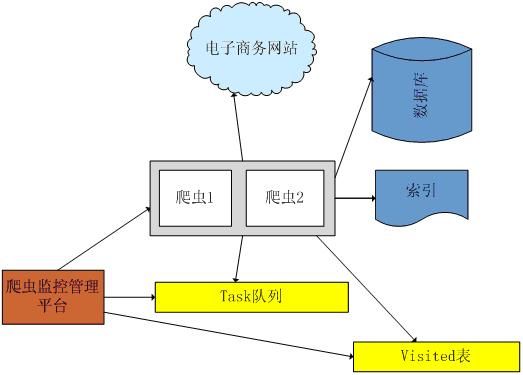
爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容
数据库:存储商品信息
索引:商品的全文搜索索引
Task队列:需要爬取的网页列表
Visited表:已经爬取过的网页列表
爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。
二、 爬虫
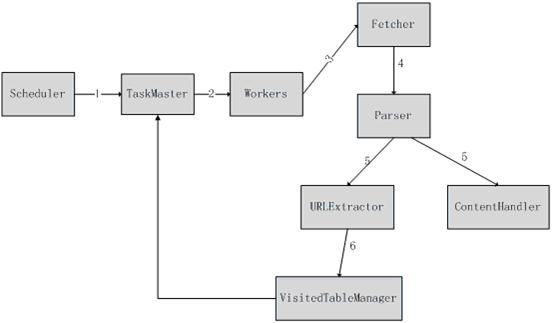
1. 流程
1) Scheduler启动爬虫器,TaskMaster初始化taskQueue
2) Workers从TaskQueue中获取任务
3) Worker线程调用Fetcher爬取Task中描述的网页
4) Worker线程将爬取到的网页交给Parser解析
5) Parser解析出来的数据送交Handler处理,抽取网页Link和处理网页内容
6) VisitedTableManager判断从URLExtractor抽取出来的链接是否已经被爬取过,如果没有提交到TaskQueue中
2. Scheduler
Scheduler负责启动爬虫器,调用TaskMaster初始化TaskQueue,同时创建一个monitor线程,负责控制程序的退出。
何时退出?
当TaskQueue为空,并且Workers中的所有线程都处于空闲状态。而这种形势在指定10分钟内没有发生任何变化。就认为所有网页已经全部爬完。程序退出。
3. Task Master
任务管理器,负责管理任务队列。任务管理器抽象了任务队列的实现。
l 在简单应用中,我们可以使用内存的任务管理器
l 在分布式平台,有多个爬虫机器的情况下我们需要集中的任务队列
在现阶段,我们用SQLLite作为任务队列的实现。可供替代的还有Redis。
任务管理器的处理流程:
l 任务管理器初始化任务队列,任务队列的初始化根据不同的配置可能不同。增量式的情况下,根据指定的URL List初始化。而全文爬取的情况下只预先初始化某个或几个电子商务网站的首页。
l 任务管理器创建monitor线程,控制整个程序的退出
l 任务管理器调度任务,如果任务队列是持久化的,负责从任务队列服务器load任务。需要考虑预取。
l 任务管理器还负责验证任务的有效性验证,爬虫监控平台可以将任务队列中的某些任务设为失效?
4. Workers
Worker线程池,每个线程都会执行整个爬取的流程。可以考虑用多个线程池,分割异步化整个流程。提高线程的利用率。
5. Fetcher
Fetcher负责直接爬取电子商务网站的网页。用HTTP Client实现。HTTP core 4以上已经有NIO的功能, 用NIO实现。
Fetcher可以配置需不需要保存HTML文件
6. Parser
Parser解析Fetcher获取的网页,一般的网页可能不是完好格式化的(XHTML是完美格式化的),这样就不能利用XML的类库处理。我们需要一款比较好的HTML解析器,可以修复这些非完好格式化的网页。
熟悉的第三方工具有TagSoup,nekohtml,htmlparser三款。tagsoup和nekohtml可以将HTML用SAX事件流处理,节省了内存。
已知的第三方框架又使用了哪款作为他们的解析器呢?
l Nutch:正式支持的有tagsoup,nekohtml,二者通过配置选择
l Droids:用的是nekohtml,Tika
l Tika:tagsoup
据称,tagsoup的可靠性要比nekohtml好,nekohtml的性能比tagsoup好。nekohtml不管是在可靠性还是性能上都比htmlparser好。具体结论我们还需要进一步测试。
我们还支持regex,dom结构的html解析器。在使用中我们可以结合使用。
进一步,我们需要研究文档比较器,同时需要我们保存爬取过的网站的HTML.可以通过语义指纹或者simhash来实现。在处理海量数据的时候才需要用上。如果两个HTML被认为是相同的,就不会再解析和处理。
7. Handler
Handler是对Parser解析出来的内容做处理。
回调方式(visitor):对于SAX event处理,我们需要将handler适配成sax的content handler。作为parser的回调方法。不同事件解析出来的内容可以存储在HandlingContext中。最后由Parser一起返回。
主动方式:需要解析整个HTML,选取自己需要的内容。对Parser提取的内容进行处理。XML需要解析成DOM结构。方便使用,可以使用Xpath,nodefilter等,但耗内存。
ContentHandler:它还包含组件ContentFilter。过滤content。
URLExtractor负责从网页中提取符合格式的URL,将URL构建成Task,并提交到Task queue中。
8. VisitedTableManager
访问表管理器,管理访问过的URLs。提取统一接口,抽象底层实现。如果URL被爬取过,就不会被添加到TaskQueue中。
三、 Task队列
Task队列存储了需要被爬取的任务。任务之间是有关联的。我们可以保存和管理这个任务关系。这个关系也是URL之间的关系。保存下来,有助于后台形成Web图,分析数据。
Task队列在分布式爬虫集群中,需要使用集中的服务器存放。一些轻量级的数据库或者支持列表的NoSql都可以用来存储。可选方案:
l 用SQLLite存储:需要不停地插入删除,不知性能如何。
l 用Redis存储
四、 Visited表
Visited表存储了已经被爬的网站。每次爬取都需要构建。
l SQLLite存储:需要动态创建表,需要不停地查询,插入,还需要后台定期地清理,不知性能如何。
l Mysql 内存表 hash index
l Redis: Key value,设过期时间
l Memcached: key value, value为bloomfilter的值
针对目前的数据量,可以采用SQLLite
五、 爬虫监控管理平台
l 启动,停止爬虫,监控各爬虫状态
l 监控,管理task队列,visited表
l 配置爬虫
l 对爬虫爬取的数据进行管理。在并发情况下,很难保证不重复爬取相同的商品。在爬取完后,可以通过爬虫监控管理平台进行手动排重。
转自:http://ldd600.iteye.com/blog/1151953