mysql中文乱码(字符集)问题及校对集
中文数据问题
中文数据问题本质是字符集问题;
计算机只能识别二进制:人类更多是识别符号,需要有个二进制与字符的对应关系(字符集),
客户端向服务器插入中文数据:没有成功

原因: \xD5\xC5\xD4\xBD代表的是’张越’ 在当前编码(字符集)下对应的二进制编码转换成十六进制:两个汉字->四个字节(GBK)
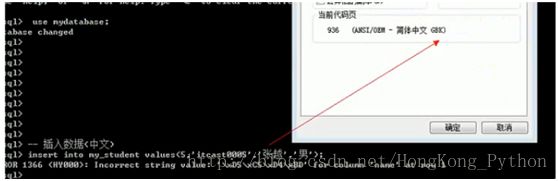
报错:服务器没有识别对应的四个字节:服务器认为数据是UTF8,一个汉字有三个字节,读取三个字节转换成汉字(失败),剩余的再读三个字节(不够),最终失败.
所有的数据库服务器认为(表现)的一些特性都是通过服务器的变量来保存:
系统先读取自己的变量,看看应该怎么表现.
//查看服务器到底识别哪些字符集: show character set;
服务器基本上的字符集都支持;
//既然服务器识别那么多:总有一种是服务器默认的跟客服端打交道的字符集
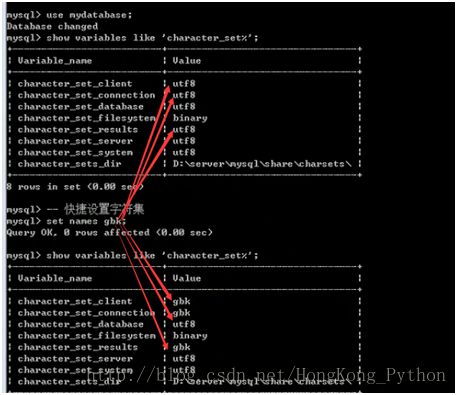
show variable like 'charcter_set%';
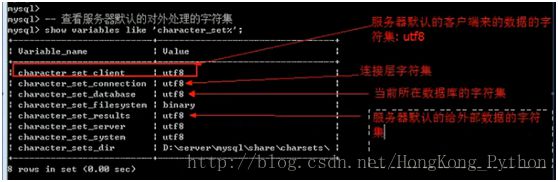
问题根源:客户端数据只能是GBK,而服务器认为是UTF8,矛盾产生
解决问题:改变服务器,默认是接收字符集为GBK
set character_set_client=gbk;
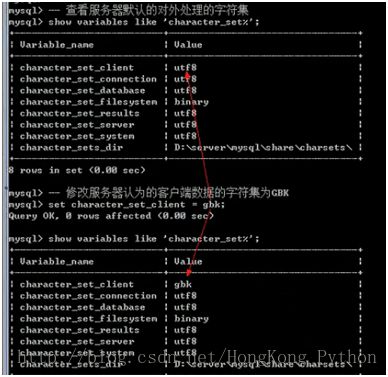
插入中文的效果:

查看数据效果:依然是乱码
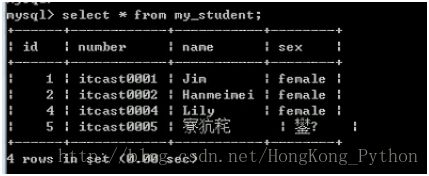
原因:数据来源服务器,解析数据是客服端(只识别GBK,只会两个字节一个汉字,但是事实服务器给的数据却是UTF8,三个字节一个汉字:所有乱码)
解决方案:这时我们对服务器给客户端的数据字符集进行改GBK;
set character_set_results=gbk
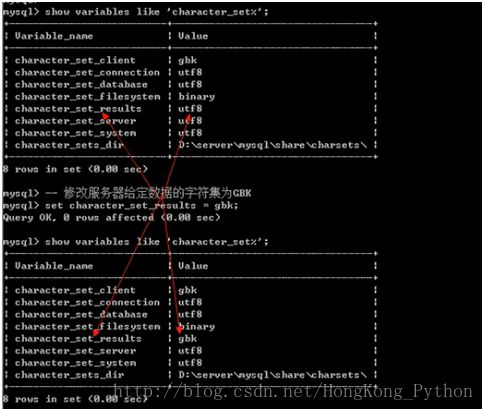
查看效果:
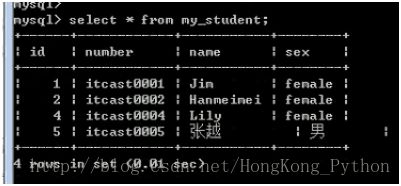
Set 变量 = 值;修改只是会话级别(当前客户端,单次连接有效;关闭失效)
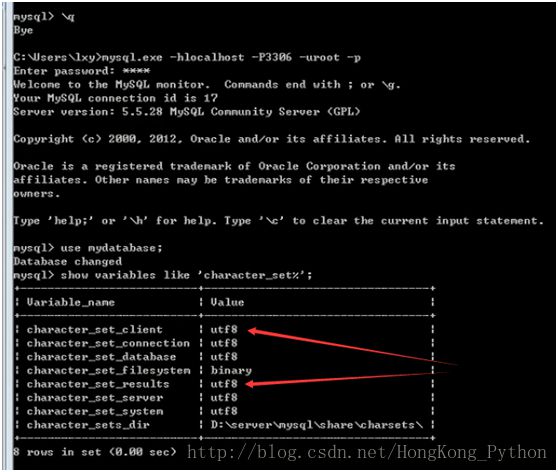
设置服务器对客户端的字符集的认知:可以使用快捷方式:set names 字符集
Ste names gbk==>把下面三条件的都改了
character_set_client =gbk,
character_set_results=gbk,
character_ste_connenction=gbk.
Connection 连接层:是字符集转变的中间者,如果统一了效率更高,不统一也没问题;
校对集问题
校对集:数据比较的方式
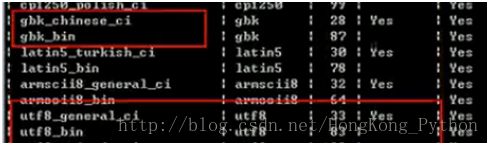
校对集有三种格式
_bin: binary,二进制比较,取出二进制,一位一位的比较,区分大小写
_cs: case sensitive, 大小写敏感,区分大小写
_ci: case insensitive,大小写不敏感,不区分大小写
查看数据库所支持的校对集: show collation;
校对集的应用: 只有当数据产生比较的时候才会生效

一般默认 _ci:不区分大小写
对比:使用utf8的_bin和_ci来验证不同的校对集的效果
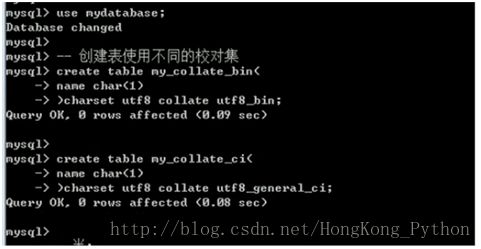
1. 创建不同校对集对应的表
Create table my_collate_bin( name char(2) ) charset utf8 collate utf8_bin;
Create table my_collate_ci( name char(2)) charset utf8 collate utf8_general_ci;
2. 插入数据
Insert into my_collate_bin values(‘a’),(‘A’),(‘b’),(‘B’);
Insert into my_collate_ci values(‘a’),(‘A’),(‘b’),(‘B’);
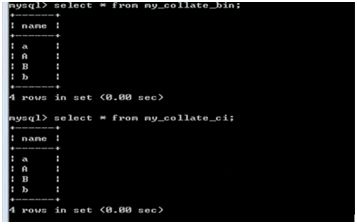
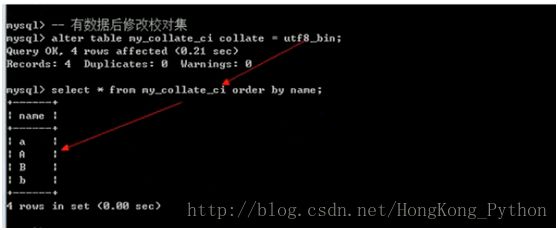
3. 比较:根据某个字段进行排序:order by 字段名 [asc | desc];asc升序,desc降序默认是asc
排序查找
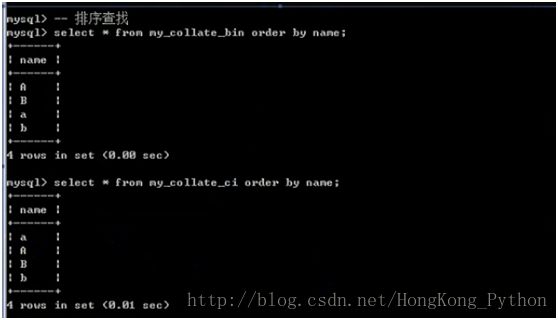
校对集:必须在没有数据之前声明好,如果有了数据,再修改校对集是无效的;
alter table my_collate_ci collate=utf8_bin;