TXT 数据文件批量导入DB
应用背景:
现有100-200个TXT数据文件,每个文件中存贮的数据量不尽相同,例如有的存储2~3万条,有的存贮2~3百条数据,现需要将这些文件导入到Sql Server数据库中;导入过程需在前台页面中显示出每个文件导入的基本情况(导入数量,状态码,出错的行数等)。
思路探寻:
(1)项目DAO层使用的Hibernate,经测试导入一个2万多条的文件,加上TXT文件逐行解析,和生成List;加上使用Hibernate的插入到数据库中大约需要15-20秒的时间,用时太长;
(2)使用原生JDBC技术进行分批(随机分组和按文件大小分组)操作;最终导入全部文件大约需要3.5分钟左右,
本文目的:
记录本次导入笔记,希望 猿友 在导入过程中和多线程并发上给出宝贵的意见,在此先表谢意!
STEP 1 : 定义文件导入过程中每个文件导入的信息 ENTITY
/**
* @Description 记录TXTGPS文件导入过程信息;
*/
public class ReceiveGpsTO {
// 导入批TXT文件所在目录
private String importDir;
// 要导入的文件名称
private String importfileName;
// 导入成功的总行数
private int importRows;
// 导入状态
private String importState;
// 导入过程中备注信息
private String importRemark;
// 导入过程中出错的行号
private int errorRow;
// 导入一个文件所需时间,默认毫秒
private int importTime;
public String getImportDir() {
return importDir;
}
public String setImportDir(String importDir) {
this.importDir = importDir
}
......
}
STEP 2 : 接收页面请求,开始进行导入
public class ReceiveGpsDataFS implements IReceiveGpsDataFS {
private final static Logger logger = LoggerFactory.getLogger(ReceiveGpsDataFS.class);
@Override
public GpsTableDataInfo receiveGpsData(ReceiveGpsTO gpsTO, int rangeStart,
int fetchSize) {
Long bTime = System.currentTimeMillis();
GpsTableDataInfo tableData = new GpsTableDataInfo();
tableData.setRltMsg(GPSConstants.IMPORT_SUCCESS);
int sumNum = 0;
List rltList = new ArrayList();
if(StringUtils.hasText(gpsTO.getImportDir())){
File dirFile = new File(gpsTO.getImportDir());
if(dirFile.isDirectory()){
File[] importFiles = dirFile.listFiles();
//MARK: 对导入的大量文件进行两种策略分组处理;
List> groupList = (GPSConstants.RANDOM_OR_SIZE_DIDIVE_STRATEGY) ?
RandomGroupUtil.getGroupByRandom(importFiles, GPSConstants.FILE_NUM_4_GROUP) :
RandomGroupUtil.getGroupBySize(importFiles, GPSConstants.FILE_NUM_4_GROUP);
for(List gl : groupList){
//MARK: 阻塞执行;执行完一组,拿到结果后执行下一组;
logger.info("开始导入GPS组文件:{}", gl);
List eachGroupRltList = ImportGpsData2DB.importGpsData(gl);
rltList.addAll(eachGroupRltList);
logger.info("开始导入GPS组文件:{} 结束", gl);
}
}else{
logger.error("导入的文件路径{}不是正确的目录", gpsTO.getImportDir());
tableData.setRltMsg(GPSConstants.IMPORT_DEFAULT);
}
for(ReceiveGpsTO t : rltList){
sumNum += t.getImportRows();
}
tableData.setTotalCount(sumNum);
tableData.setData(rltList);
Long eTime = System.currentTimeMillis();
logger.info("导入文件数量:"+rltList.size()+" 总耗时分钟: "+(eTime-bTime)/GPSConstants.SECOND_2_MS);
}
return tableData;
}
}
对STEP 2 中用到的常量和文件分组方式进行简单说明:
对需要导入的100多个TXT文件进行分组导入,分组时提供两种分组方式: 一种,随机进行分组,也就是在同一个组内,可能有的文件比较大,有的文件比较小,例如:(File1:3M, File2 : 1M, File3: 4M, File4: 20KB);这种分组的好处:每组文件总的大小相对稳定,不会导致一组文件特别到,因为后期导入时按组开线程,使用Callable接口 拿CONNECTION操作,可以降低OOM概率;第二种:按文件大小分组,也就是说同一组内,每个文件的大小不相上下,好处,后期插入时,使用Future.get方法时是阻塞方法,可以有效的减下彼此间的等待时间,速度快,同时也增加了OOM概率。
常量:
public class GPSConstants {
//导入STATE
public static final String IMPORT_DEFAULT = "FAILURE";
public static final String IMPORT_SUCCESS = "SUCCESS";
public static final int SECOND_2_MS = 1000;
//导入文件进行随机分组:好处:减小OOM概率
//导入文件按大小分组:好处:导入速度相当较快;坏处:当每组文件数量比较多时,增加OOM概率
//true : 随机分组 false: 按大小分组;
public static final boolean RANDOM_OR_SIZE_DIDIVE_STRATEGY = true;
//public static final boolean SIZE_DIDIVE_STRATEGY = true;
//导入文件分组:每组中文件个数;建议当JVM XMx<300不要超过5个;
public static final int FILE_NUM_4_GROUP = 4;
}
两种分组方式:
/**
* @Description 随机分组工具类, 提供按文件大小分组和随机分组方式
*/
public class RandomGroupUtil {
/**
* @Dscription 随机分组模式
* @param origData 要分组的数据;
* @param numOfEachGroup 每组中成员数量;
* @return
*/
public static List> getGroupByRandom(T[] origData, int numOfEachGroup) {
int len = origData.length;
List origList = new ArrayList();
List> groupsList = new ArrayList>();
for(T f : origData)
origList.add(f);
if(len < numOfEachGroup) {//只分一组
groupsList.add(origList);
return groupsList;
}
// 计算可以分多少组
int groupNum = ((len + numOfEachGroup) - 1) / numOfEachGroup;
for (int i = 0; i < groupNum-1; i++) {
List group = new ArrayList();
for (int j = 0; j < numOfEachGroup; j++) {
int random = getRandom(origList.size());
group.add(origList.get(random));
origList.remove(random);
}
groupsList.add(group);
}
// 最后剩下的人分成一组;
groupsList.add(origList);
return groupsList;
}
/**
* @Decription 按文件大小进行分组,每组成员中所含的文件大小相近
* @param files
* @param numOfEachGroup 每组中要包含的成员数量;
* @return 分好的组
*/
public static List> getGroupBySize(File[] files, int numOfEachGroup) {
int len = files.length;
List orgList = new ArrayList();
List> groupsList = new ArrayList>();
for(File f : files)
orgList.add(f);
if(len < numOfEachGroup) {//只分一组
groupsList.add(orgList);
return groupsList;
}
//按文件大小排序
Collections.sort(orgList, new Comparator(){
public int compare(File o1, File o2) {
if( o1.length() == o2.length())
return 0;
return (o1.length() - o2.length() > 0) ? 1 : -1;
}
});
// 计算可以分多少组
int groupNum = ((len + numOfEachGroup) - 1) / numOfEachGroup;
for (int i = 0; i < groupNum-1; i++) {
List group = new ArrayList();
for (int j = 0; j < numOfEachGroup; j++) {
group.add(orgList.get(orgList.size()-1));
orgList.remove(orgList.size()-1);
}
groupsList.add(group);
}
// 最后剩下的人分成一组;
groupsList.add(orgList);
return groupsList;
}
private static int getRandom(int num) {
Random r = new Random();
return r.nextInt(num);
}
}
STEP 3 : 使用 Executors 和 DataSource 数据源连接池按组进行批量导入
/**
* @Description : 使用executor调用call, 导入状态信息封入ReceiveGpsTO
*
*/
public class ImportGpsData2DB {
private static final Logger logger = LoggerFactory.getLogger(ImportGpsData2DB.class);
private static ExecutorService executor = null;
private static WrapDataSource dataSource = null;
static{
executor = Executors.newFixedThreadPool(GPSConstants.FILE_NUM_4_GROUP);
dataSource = (WrapDataSource) ZBus.findCommonService("dataSource");
}
public static List importGpsData(List gl) {
List rList = new ArrayList();
List> fList = new ArrayList>();
for(File file : gl){
Connection conn = null;
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
logger.error("{}从连接池中获取数据库连接失败, 本组文件 {} 导入失败", ImportGpsData2DB.class.getName(), gl);
e.printStackTrace();
return rList;
}
// 开启线程进行导入
Future future = executor.submit(new ImportGpsCallable(file, conn));
fList.add(future);
}
for(Future f : fList){
try {
ReceiveGpsTO rTO = f.get();
rList.add(rTO);
} catch (Exception e) {
logger.error("{} 获取本组文件{} 导入状态失败", ImportGpsData2DB.class.getName(), f);
e.printStackTrace();
}
}
return rList;
}
}
数据源配置:
classpath:*.db.properties
STEP 4 : 实现 CALLABLE 线程进行导入,每组中得每一个文件对应一个导入线程;
/**
* @Description GPS数据导入线程,主要完成txt文件解析和数据库导入;
* @author ***
*
*/
public class ImportGpsCallable implements Callable {
private static final String SQL_STR = "INSERT INTO [ZXX_MXX].[dbo].[GPS_XXX_PASS_RECORD]( ORDER_NUM, HPHM, HPZL, PASS_TIME, LONGITUDE, "
+ "LATITUDE, SPEED, DIRECTION, POSITION_STATE, MILEAGE, RELATIVE_MILEAGE, VEHICLE_STATE, LOCATION) VALUES("
+ "?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
private File file;
private Connection conn;
//通过构造方法传入所需的资源
public ImportGpsCallable(File file, Connection conn) {
this.file = file;
this.conn = conn;
}
@Override
public ReceiveGpsTO call() throws Exception {
ReceiveGpsTO gpsRlt = new ReceiveGpsTO();
gpsRlt.setImportfileName(file.getName());
Long beginImpTime = System.currentTimeMillis();
// 通过工具类DataClearTools对TXT文件进行格式验证和数据解析;
List rList = DataClearTools.getGpsRecords(file, gpsRlt);
PreparedStatement ps = null;
try{
if(null != conn){
conn.setAutoCommit(false);
ps = conn.prepareStatement(SQL_STR);
int[] rows = null;
if( rList.size() > 0 ){
for(GpsVehiclePassRecord g : rList){
ps.setLong(1, g.getOrderNum());
ps.setString(2, g.getHphm());
ps.setString(3, g.getHpzl());
ps.setTimestamp(4, new Timestamp(g.getPassTime().getTime()));
ps.setString(5, g.getLongitude());
ps.setString(6, g.getLatitude());
ps.setInt(7, g.getSpeed());
ps.setString(8, g.getDirection());
ps.setString(9, g.getPositionState());
ps.setString(10, g.getMileage());
ps.setString(11, g.getRelativeMileage());
ps.setString(12, g.getVehicleState());
ps.setString(13, g.getLocation());
ps.addBatch();
}
rows = ps.executeBatch();
conn.commit();
}else{
gpsRlt.setImportRemark("数据导入失败");
gpsRlt.setImportState(GPSConstants.IMPORT_DEFAULT);
}
gpsRlt.setImportRows(rows.length);
Long endImpTime = System.currentTimeMillis();
gpsRlt.setImportTime((int) (endImpTime-beginImpTime));
System.out.println(Thread.currentThread().getName()+" "+gpsRlt.getImportTime());
gpsRlt.setImportRemark("数据导入成功");
gpsRlt.setImportState(GPSConstants.IMPORT_SUCCESS);
}
}catch(Exception e){
conn.rollback();
e.printStackTrace();
gpsRlt.setImportRemark("数据导入失败");
gpsRlt.setImportState(GPSConstants.IMPORT_DEFAULT);
}finally{
if(null != ps){
ps.close();
}
if(null != conn){
conn.close();
}
}
return gpsRlt;
}
}
对TXT文件进行格式验证和解析的工具类 DataClearTools 如下
/**
* @Description 对TXT文件进行解析;
* @author ***
*
*/
public class DataClearTools {
private static final Logger logger = LoggerFactory.getLogger(DataClearTools.class);
private static final String DEF_HPZL = "01";
private static final String ENCODING = "UTF-8";
/**
* @Description 解析TXT -> List
* @param file 被解析的TXT文件
* @param to 解析过程中的状态MODEL
* @return 解析完成的List
*/
public static List getGpsRecords(File file, ReceiveGpsTO to) {
List gpsList = new ArrayList();
List duplicateList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
int row=0;
try {
if (file.isFile() && file.exists()) {
read = new InputStreamReader(new FileInputStream(file), ENCODING);
bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
row++;
if(1 == row){
continue;
}
if (StringUtils.isNotBlank(lineTxt)) {// 不等于空才运行
GpsVehiclePassRecord pass = null;
try{
pass = lineTxt2GpsPass(lineTxt);
}catch(Exception e){
throw e;
}
if(null != pass)
gpsList.add(pass);
}else{
row++;
}
}
//根据hphm和过车时间去掉重复行
if(gpsList.size()>0){
duplicateList = DuplicateGpsRecord(gpsList);
}
}
}
} catch (IOException e) {
logger.error("解析GPS文件{}出错! ",file.getName());
to.setImportRemark("解析文件过程中出错");
to.setImportRows(0);
duplicateList.clear();
e.printStackTrace();
} catch (Exception e){
logger.error("解析GPS文件{}出错! ",file.getName());
to.setImportRemark("解析文件行信息过程中出错");
to.setImportRows(0);
to.setErrorRow(row);
duplicateList.clear();
e.printStackTrace();
}finally{
if(bufferedReader!=null){
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(null != read){
try {
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return duplicateList;
}
/**
* @Description 根据hphm和过车时间去重;
* @param gpsList
* @return
*/
private static List DuplicateGpsRecord(List gpsList) {
List duplicateList = new ArrayList();
for(GpsVehiclePassRecord g : gpsList){
if(duplicateList.contains(g)){
continue;
}else{
duplicateList.add(g);
}
}
return duplicateList;
}
/**
* @Description 根据读到的每行信息解析成Gps Model
* @param lineTxt
* @return
* @throws Exception
*/
private static GpsVehiclePassRecord lineTxt2GpsPass(String lineTxt) throws Exception {
GpsVehiclePassRecord record = new GpsVehiclePassRecord();
try{
String[] strArr = lineTxt.split("\\s+");
String hphmStr;
//序号
record.setOrderNum(Long.parseLong(strArr[0].trim()));
//XXXX 转换过程
return record;
}catch(Exception allE){
logger.error("解析行内容到GpsVehicelPassRecord出错");
throw allE;
}
}
}
结果展示:
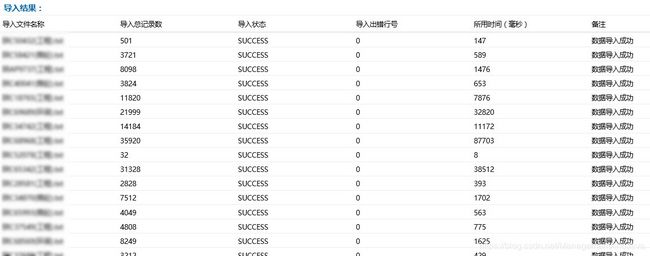
CASE 1 : 对 120个TXT 文件,总共 97万5千 条数据进行导入:采用文件 随机分组策略,每组 4 个文件 ;进行导入:总共用时:576秒;
所需的Heap Size 最大不超过200M (PS: 自然包括工程其它东西占用); 在此需说明,由于 导入线程使用的是Callable,其Future.get() 方法是阻塞方法,所以每次导入的时间可能不一样,不过总体相差不会太多;

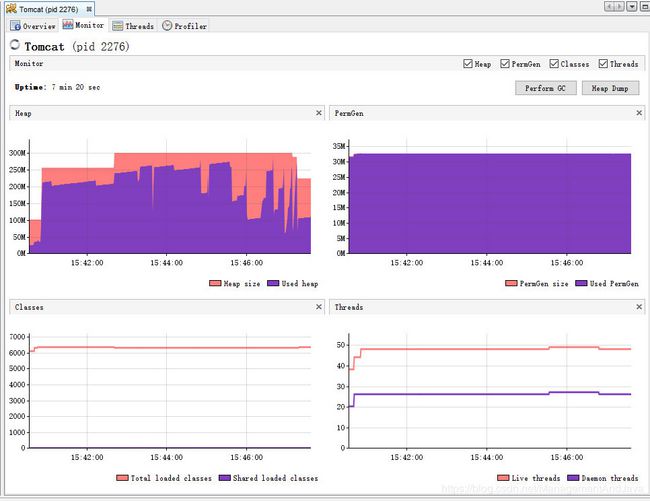
CASE 2 : 对 120个TXT 文件,总共 97万5千 条数据进行导入:采用文件 按文件大小分组策略,每组 4 个文件 ;进行导入:总共用时:366秒;所需的Heap Size 最大不超过300M (PS: 自然包括工程其它东西占用); 不过可以明显看出,时间缩短了但是需要的最大Heap Size 有所增加,
需要的HEAP SIZE 比随机导入时大的原因,按文件大小进行排序,当一组文件都比较大时,自然H S也就比较大,
所需的导入时间 366 < 576的原因是,在导入过程中使用了Callable接口,Future.get() 方法是阻塞方法,相同大小的文件在一起导入,批次不会等待太多时间;

CASE 3 : 采用 文件按大小分组,每组成员数量为5个,导入时间大概3分多点,此处不再罗列,注意并不是 每组的成员越多越好,当成员过高时需要的数据库链接也越多,到达一定量时,会方式IO阻塞问题;
尾声:
希望 朋友可以在 异常处理; 数据回归;和并发问题上给出宝贵的意见和批评,感谢;