【阅读笔记】(语义分割最全总结,综述)《A Review on Deep Learning Techniques Applied to Semantic Segmentation》
本文记录了博主阅读论文《A Review on Deep Learning Techniques Applied to Semantic Segmentation》的笔记。这篇论文是首篇综述深度学习用于语义分割的论文(论文作者称),语言很棒,建议读原文感受一下。
这篇博文很长,建议大家挑选自己需要的部分进行阅读,可以不用从头看到尾。需要的时候知道有这么个东西,知道上哪里查就可以了。更新于2019.2.25。
文章目录
- Introduction
- 术语及背景概念
- 常用深度网络结构
- AlexNet
- VGG
- GoogleNet
- ResNet
- ReNet
- 迁移学习(transfer learning)
- 数据预处理和扩张(Data Preprocessing and Augmentation)
- 数据库及挑战赛
- 2D 数据库
- PASCAL Visual Object Classes (VOC)
- PASCAL Context
- PASCAL Part
- Semantic Boundaries Dataset (SBD)
- Microsoft Common Objects in Context (COCO)
- SYNTHetic Collection of Imagery and Annotations (SYNTHIA)
- Cityscapes
- CamVid
- KITTI
- Youtube-Objects
- Adobe's Portrait Segmentation(肖像)
- Materials in Context (MINC)
- Densely-Annotated VIdeo Segmentation (DAVIS)
- Stanford background
- SiftFlow
- 2.5D数据库
- NYUDv2
- SUN3D
- SUNRGBD
- The Object Segmentation Database (OSD)
- RGB-D Object Dataset
- 3D数据库
- ShapeNet Part
- Stanford 2D-3D-S(室内)
- A Benchmark for 3D Mesh Segmentation
- Sydney Urban Objects Datasets(道路)
- Large-Scale Cloud Classification Benchmark
- 方法
- 译码器变体(Decoder Variants)
- 整合上下文信息
- 条件随机场(Conditional Random Fields)
- 扩张卷积(Dilated Convolutions)
- 多尺度估计(Multi-scale Prediction)
- 特征融合(Feature Fusion)
- 循环神经网络(Recurrent Neural Network)
- 实例分割(Instance Segmentation)
- RGB-D数据
- 3D数据
- 视频序列
- 讨论
- 评估标注
- 执行时间(Execution Time)
- 内存消耗(Memory Footprint)
- 准确率(Accuracy)
- 结果
- RGB
- 2.5D
- 3D
- 视频序列
- 附件:术语解释
- 计算摄影学(Computational Photograyphy)
- 高光谱图像(hyperspectral images)
- 迁移学习
- TOP-5 test accuracy
- WordNet hypernym-hyponym
- Vanilla CNNs
Introduction
博主在这一部分总结了论文introduction部分的内容,进行精炼和归类,方便阅读。如果需要完整版本,建议参考原文。
语义分割的应用场景:
- 自动驾驶(autonomous driving)【参考文献(1),(2)kitti,(3)cityscapes】
- 人机交互(human-machine interaction)【参考文献】
- 计算摄影学(computational photography)【参考文献】
- 图片搜索引擎(image search engines)【参考文献】
- 增强现实(augmented reality)
文章主要贡献
- 研究了大量可用于分割任务的深度学习数据库;
- 深入组织了最重大的语义分割深度学习方法,包括其原理和贡献;
- 全面的评估机制,包括准确度(accuracy)、执行时间(execution time)、内存占用(memory footprint)等在内的定量度量;
- 对于上述方法的讨论,并给出未来可行的研究方向。
论文结构安排
- 第二章:介绍语义分割问题、文献中常用的术语和习俗、背景概念(如常用深度神经网络)和数据库;
- 第三章:介绍现有数据库、挑战赛、benchmarks;
- 第四章:按照贡献回顾现有算法,主要关注贡献而不是评估算法表现;
- 第五章:在前文提到的数据库下评估文中提到的算法,并给出未来研究方向的建议。
术语及背景概念
深度学习结构开始解决语义分割问题是一个循序渐进的过程,最开始的起源可以认为是分类任务。给定一个输入,分类任务会将其视作整体,输出一个prediction,比如判断图像中哪一个是目标,或在多个目标同时存在时给出一个列表。之后,更深入的任务开始了。定位(检测)不但需要提供目标类别,同时还要给出目标在空间上的位置信息(如centroids或bounding boxes)。实现这个任务后,很自然地能发现,语义分割是这个任务更深入一步,其目标是:给出每个像素点对应的稠密prediciton。如此一来,每个像素点都有了其属于的那个封闭目标或区域的类别。更进一步,可以实现实例分割(相同类别的不同个体拥有不同的标注),甚至part-based分割(将已经分割好的类别再根据其组件进行进一步的细分)。下图给出了上述的演变过程。

本文主要关注语义分割(即逐像素类别标注),对于重要的实例分割和part-based segmentation也会提及。
最后,给出逐像素类别标注问题(per-pixel labeling problem)的公式化表达:以某种规则给出由一系列随机变量组成的集合 X = { x 1 , x 2 , … , x N } \mathcal X=\{x_1,x_2,\dots,x_N\} X={x1,x2,…,xN}中的所有元素给出标签空间(label space) L = { l 1 , l 2 , … , l k } \mathcal L=\{l_1,l_2,\dots,l_k\} L={l1,l2,…,lk}。每个标签 l l l代表一个不同的类别或目标,比如飞机、车、路牌、背景等等。这个标注空间有 k k k个可能的状态,通常也会被扩展成 k + 1 k+1 k+1,其中增加了 l 0 l_0 l0来表示背景或空集。通常, X \mathcal X X是一个2D的图像,包含 W × H = N W\times H = N W×H=N个像素 x x x。当然,这个集合(the set of random variables)的维度可以任意改变,也可以变成3D数据或高光谱图片(hyperspectral images)。
除了公式化的表述,深度语义分割系统中常用网络结构、方法、基本设计思想等也非常重要。此外,常用训练技巧(如迁移学习)等也有助于读者的了解。最后,数据预处理和扩张方法也非常重要。
常用深度网络结构
如前文所述,有些深度网络由于它们的杰出贡献已经变成了广为人知的标准,比如AlexNet,VGG-16,GoogleNet,ResNet等。这些网络目前也成为了许多分割结构的基础模块(building blocks)。因此,这一部分将介绍这几种方法。
AlexNet
AlexNet是深度CNN的先锋,其以TOP-5测试准确率84.6%赢得了ILSVRF-2012,而与其最相近的对手使用的是传统方法,正确率仅为73.8%。这个由Krizhevsky等人提出的结构相对简单。其包含5个卷积层,max-pooling ones,Rectified Linear Units(ReLUs)引入非线性,3个全连接层,以及dropout。具体结构如下图所示:
(本文给的图:)
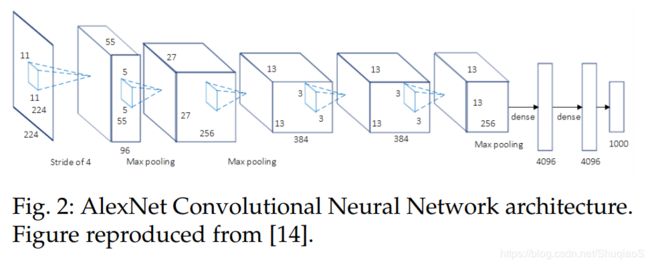
(AlexNet原文给的图:)

VGG
Visual Geometry Group (VGG)是由牛津大学(University of Oxford)的视觉几何组(Visual Geometry Group,VGG)提出的。他们提出了多种深度CNN模型和配置,其中一个被提交至了ImageNet Large Scale Visual Recognition Challenge (ILSVRC)-2013。这个模型有16个权重层,因此被称为VGG-16。它取得了TOP-5 test accuracy 92.7%的好成绩,从而流行起来。下图为VGG-16的配置:
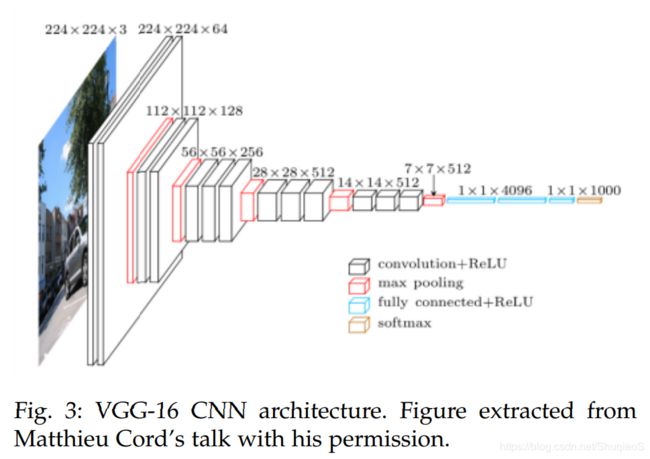
与前序工作不同的是,VGG-16前几层采用了一系列小感受野的卷积层,而非很少的基层大感受野的卷积层。这么做在减少了参数个数的同时增大了函数内部的非线性,从而使得决策函数(decision function)的识别力更强,也更容易训练。
GoogleNet
GoogleNet是由Szegedy等人提出的网络结构,其参加了ILSVRC-2014,并取得了TOP-5 test accuracy 93.3%的好成绩。这个CNN结构以其复杂性为特点,包含22层和新提出的inception模块(如下图所示)。
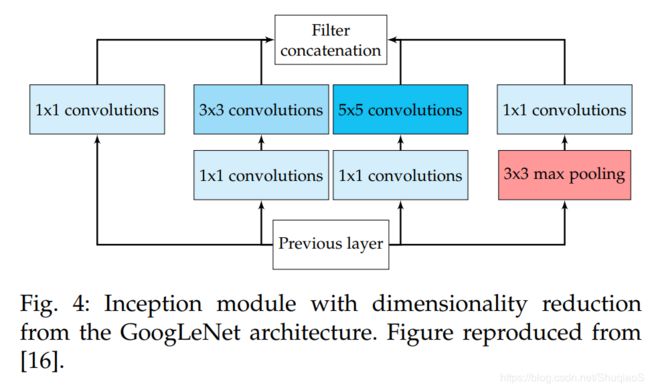
这个网络结构证明了CNN不仅可以像之前那样顺序排列,也可以以更多样的方式排布。实际上,这些模块包括Network in Network(NiN)层、pooling操作、large-sized卷积层和small-sized卷积层,这些层平行计算,之后通过一个1x1的卷及操作降维。正是因为这些操作,GoogleNet特别考虑了内存和计算量,因而大量减少了参数个数和操作次数。
ResNet
微软的ResNet因赢得了ILSVRC-2016(正确率96.4%)而出名。除此之外,其也由于其深度(152层)和残差模块(如下图所示)而备受关注。
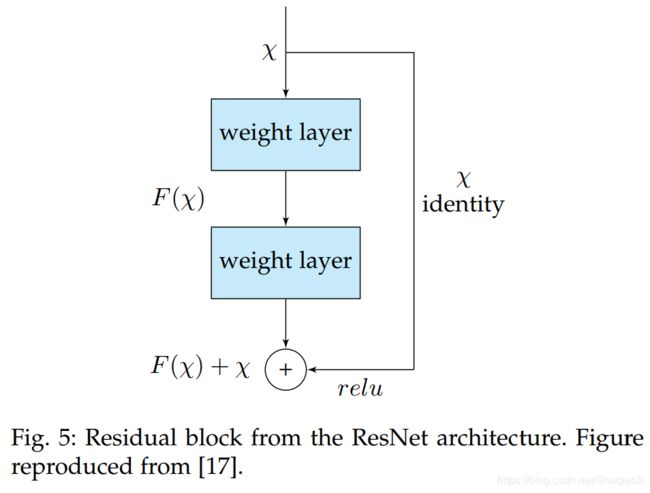
残差模块通过引入skip connections解决了非常深的网络的训练问题,因为这一操作使得后面的层可以复制其之前的层的输入。直观上,这种做法背后的道理就是,允许后面的层在已知前面层的输出的前提下,从前一层的输入中习得一些不同的东西。此外,这种做法也有助于解决梯度消失的问题。
ReNet
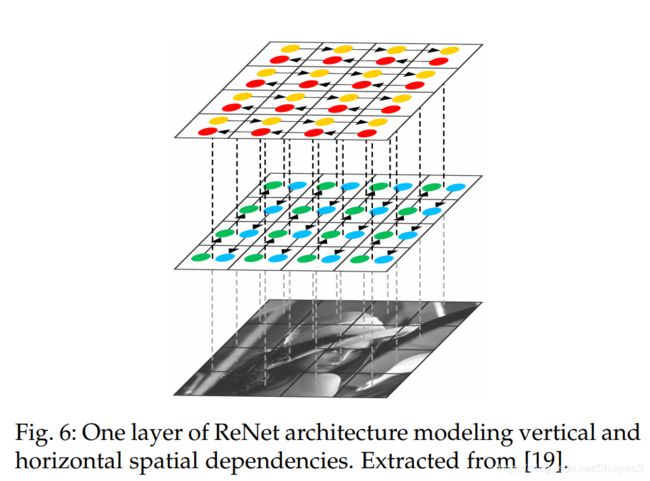
为了将循环神经网络(RNNs, Recurrent Neural Networks)结构应用到多维任务(multi-dimensional tasks)中,Graves等人提出了Multi-dimensional Recurrent Neural Network (MDRNN),其用 d d d connections替换掉了标准RNNs中的每个recurrent connection。其中, d d d是时空数据维数(number of spatio-temporal data dimensions)。基于这个基本做法,Visin等人提出了ReNet结构。该结构使用了usual sequence RNNs,而不是multidimensional RNNs。如此一来,RNNs的个数就可以根据输入图像( 2 d 2d 2d)的维数 d d d在每层中进行线性缩放。在这个方法中,每个卷积层(convolution+pooling)都由四个RNNs对图像的水平和竖直方向进行打扫(sweep),具体如下图所示:
迁移学习(transfer learning)
从最开始训练一个神经网络通常不太可行的主要原因是:需要一个具有足够尺寸的数据集(通常很难获得);且收敛所需要的时间太长,有时并不值得。即使数据集够大,收敛的时间也没有那么长,从一个已经预训练好的权重开始训练也比从随机的权重开始要好(参考【1】【2】)。从一个预训练的网络考试训练是迁移学习一个最常见的手法。
Yosinski等人证明了即使从非常不同的任务中得到的特征开始训练也比用随机初始化要好,因为特征的可转移性会随着预训练任务与目标任务之间的差异的增大而减弱。
然而,应用这种迁移学习的方法也不是这么简单。一方面,要求网络结构匹配才能传递权重。尽管如此,也不是所有情况都需要用一个全新的网络结构(或组成部分),因此还是可以使用迁移学习的。另一方面,从头训练和fine-tuning的训练流程还是有区别的。选择合适的层去fine-tune还是很重要的(通常选择网络的heigher-level的部分,因为底层通常包含更普适的特征),同时还要确定合适的学习率规则(通常学习率要小一些,因为预训练的权重通常都比较好了,因此不需要很大幅度的调整)。
由于逐像素标注分割数据集固有的收集和创建难题,这些数据库的规模通常没有分类数据集(比如ImageNet【1】【2】)那么大。这个问题在RGB-D或3D数据库上体现的更加明显,这些数据库也更小。基于此,从分类网络应用迁移学习的做法在分割网络中非常常见, 下文也将介绍许多成功的应用。
数据预处理和扩张(Data Preprocessing and Augmentation)
数据扩张对于训练常规和深结构的训练都有好处,也非常普遍。其既可以加速收敛也可以作为regularizer,从而避免过拟合并提升网络的泛化性(参考)。
数据扩张通常包括对数据或特征空间的一系列变换,有时甚至对两者同时进行。不过常见的数据扩张都是对数据进行的,这种扩张会通过变换在已有数据集的基础上生成新的样本。常用的变换有:平移(translation),旋转(rotation),warping,缩放(scaling),颜色空间平移(color space shifts),截取(crops)等。这些变换最本质的目的是创造更大的数据集,从而避免过拟合(overfitting)或潜在归一化模型,还可以平衡数据集中的类别,甚至整体上产生更适合手头目的或任务的新样本。
数据扩张对于小数据库的优势更加明显,一系列的成功案例也证明了这一点。比如,在这篇论文中,一个含有1500个肖像的数据库,通过四个尺度(0.6, 0.8, 1.2, 1.5)、四个转角(-45, -22, 22, 45)和四个gamma变换(0.5, 0.8, 1.2, 1.5),生成了一个新的数据集,包含19000张训练图像。这个过程使得文章作者能够成功地通过在扩张后的数据集上fine-tuning,将他们网络的IoU(Intersection over Union)正确率从73.09提升到了94.20。
数据库及挑战赛
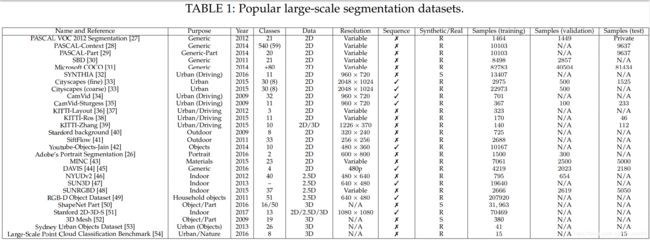
下面我们列出了一些目前还在用的大规模流行数据库。所有列出的数据库都有合适的pixel-wise或point-wise标注。根据数据属性,这份清单被分成三个部分:2D或平面RGB数据库,2.5D或RGB-Depth(RGB-D)数据库,和纯立体或3D数据库。下表给出了所有涉及到的数据库的总结。
2D 数据库
PASCAL Visual Object Classes (VOC)
论文 | 网站
这个挑战赛包括有注释的图像数据集和5个不同的比赛:分类(classification)、检测(detection)、分割(segmentation)、行为分类(action classification)和人体布局(person layout)。其中,分割任务的目的是标注出每幅测试图像中的每个像素点对应的目标类别。
分割数据库共包括21个类别,归类为“交通工具(vehicles)”、“家庭(household)”、“动物(animals)”和“其他”:飞机(aeroplane)、自行车(bicycle)、船(boat)、公交车(bus)、车(car)、摩托车(motorbike)、火车(train)、瓶子(bottle)、椅子(chair)、餐桌(dining table)、盆栽(potted plant)、沙发(sofa)、电视/监控(TV/monitor)、鸟(bird)、猫(cat)、牛(cow)、狗(dog)、马(horse)、羊(sheep)和人(person)。如果一个像素不属于上面的任何一个类别,其将被划分至“背景”。数据库被分成两个子集:1464张图片的训练集(training)和1449张图片的验证集(validation)。测试集(test)作为挑战赛的保留部分,不被公开。
这个数据集是语义分割领域公认的最权威的数据集,因此几乎所有知名的文献中所提到的算法都被提交至这个数据集以与其他方法比较。算法既可以仅用数据集训练,也可以用辅助信息训练。排名可以看这里。
PASCAL Context
论文 | 网址
这个数据库是PASCAL VOC 2010检测挑战赛的扩展,其中包括10103张pixel-wise标注的训练图片。共有540个类别(包括PASCAL VOC包含的原始的20个类别和背景),共可以分为3个大类:目标(objects)、东西(stuff)和混合(hybirds)。尽管这个数据库包括许多类别,但是最常用的只有59个,而其他的会被relabel成背景。
PASCAL Part
论文 | 网址
这个数据集也是PASCAL VOC 2010的一个扩展,其优势是为每个类别提供了per-pixel segmentation mask标注(或至少是轮廓)。原始的PASCAL VOC类别被保留了下来,但是引入了它们的part,比如,自行车被分解成了后轮(back wheel)、链轮(chain wheel)、手把(handlebar)、前灯(headlight)和车座(saddle)。该数据集包括了所有PASCAL VOC的训练集、验证集的标注,以及9637张测试集的标注。
Semantic Boundaries Dataset (SBD)
论文 | 网址
这个数据集也是前文提到的PASCAL VOC的扩展版本,其提供了VOC中没有提供标注的图像的语义分割真值,包括11355张来自PASCAL VOC 2011的图片标注。除了每个类别的边界外,标注中还包括category-level和instance-level的信息。由于信息来自于整个PASCAL VOC挑战赛(而不仅仅是分割部分),SBD的训练集(8498张)和验证集(2857张)的区分与其不同。由于其增加了训练数据的数量,这个数据集经常被用作PASCAL VOC在深度学习上的替代品。
Microsoft Common Objects in Context (COCO)
论文 | 网址
这个是另一个图像识别(recognition)、分割(segmentation)、字幕(captioning)的大规模数据集,包括80个类别,超过82783张训练图片,40504张验证图片和80000余张测试图片。特别地,测试集被分成了不同的子集:test-dev(20000张)用于作为验证集的补充集合,test-standard(20000张)是默认的数据集用于比较state-of-the-art methods,test-challenge(20000张)用于评估提交至挑战赛的算法,以及test-reserve(20000张)用于防止挑战赛中可能出现的过拟合(如果一个方法提交了太多版本,就会用这个集合比较)。由于规模巨大,COCO数据集面世之后便广受欢迎且持续升温。挑战赛的结果与ImageNet的结果一同加入了ECCV(European Conference on Computer Vision)。
SYNTHetic Collection of Imagery and Annotations (SYNTHIA)
论文 | 网址
这个数据集包括大量描述虚拟城市(virtual city)的语义分割好的图像,其目的是用于驾驶和城市景观(urban scenario)的景物理解(scene understanding)。数据集包括11个fine-grained pixel-level标注好的类别,包括空集(void)、天空(sky)、建筑(building)、路(road)、人行道(sidewalk)、栅栏(fence)、植被(vegetation)、杆(pole)、车(car)、标识(sign)、行人(pedestrian)和骑车的人(cyclist)。其包括13407张从视频序列中提取的训练图像,场景也很多元化(towns, cities, highways),包含动态目标、季节、天气等。
Cityscapes
论文 网址
这是一个关注城市道路场景的语义理解的大型数据库,提供了语义层面、实例层面和稠密像素级标注的30个类别,共分为8大类:平面(flat surfaces)、人(humans)、交通工具(vehicles)、建筑(constructions)、物体(objects)、自然(nature)、天空(sky)和空集(void)。数据库包括约5000张精心标注的图片和20000粗标的图片。这些数据拍摄于50个不同的城市,横跨数月,拍摄于不同时间和天气。拍摄时拍摄的是视频,后期人工筛选出满足条件的图片:包括大量动态目标,场景不同,背景不同。
CamVid
论文1 论文2 | 网址
这个数据集最开始是记录道路和行驶场景的5个拍摄到的视频,分辨率960x720,相机放在车辆仪表盘上。随后以一定采样频率(4个是1 fps,1个是15fps)采样得到701帧。手动标注成32个类别:空(void)、建筑(building)、墙(wall)、树(tree)、植被(vegetation)、栅栏(fence)、人行道(sidewalk)、停车位(parking block)、圆柱(column/pole)、路障(traffic cone)、桥(bridge)、路标(sign)、混合(miscellaneous text)、信号灯(traffic light)、天空(sky)、隧道(tunnel)、拱门(archway)、路(road)、路肩(road shoulder)、车道标识(lane markings)(driving)、车道标识(lane markings)(non-driving)、动物(animal)、行人(pedestrain)、孩子(child)、行李(cart luggage)、骑自行车的人(bicyclist)、摩托车(motorcycle)、车(car)、SUV/小卡车/卡车(SUV/pickup/truck)、卡车/公交车(truck/bus)、火车(train)和其他移动物体(other moving object)。需要特别注意一下Sturgess等人在论文里提到的分类:367个训练集、100个验证集、233个测试集。这种分类利用了上述分类的一个子集:建筑、树、天空、车、路标、路、行人、栅栏、柱子、人行道和骑自行车的人。
KITTI
论文 | (网址)
这是自动驾驶和移动机器人领域最常用的数据库之一,然而数据库本身并不包含语义分割的标注。然而,许多作者为了满足自己的需要手动标注了部分数据集。比如Alvarez等人(论文1,论文2)为323张来自于道路检测挑战的图片标注了真值,类别包括道路(road)、交通工具(vehicle)、天空(sky)。Zhang等人标注了252张(140张用来训练,112张用来测试)来自于跟踪挑战的获得物(包括RGB和Velodyne扫描结果),包含10个类别:建筑、天空、道路、植被、人行道、车、行人、骑自行车的人、路牌/柱子、栅栏。Ros等人标注了170张训练图像和46张测试图像(图像来自于视觉测距挑战(visual odometry challenge)),包括11个类别:建筑、树、天空、车、标识、路、行人、栅栏、柱子、人行道、骑自行车的人。
Youtube-Objects
论文
这个数据库中的视频是从Youtube上挑选出来的,包括10个PASCAL VOC类别:飞机、鸟、船、车、猫、牛、狗、马、摩托车、火车。这个数据库不包含像素级的标注,但是Jain等人手动标注了一个126个序列组成的子集。他们从每个视频序列中提取10帧,生成语义标注,一共生成了10167张标注的帧,分辨率为480x360。
Adobe’s Portrait Segmentation(肖像)
论文 | 网址
这个数据集包括的是从Flickr上获得的分辨率为800x600像素的人像图片,主要用手机前置摄像头获取。数据集共有1500张训练图像和300张保留图像(测试),两个数据集都有完整的二维标注:人物或背景。图像标注的方法是半自动的:首先对每个图片运行人脸检测算法,随后截取600x800像素,之后手动用Photoshop的快速选择(quick selection)工具进行标注。这个数据集主要贡献是提供了具体的应用场景:人作为前景。
Materials in Context (MINC)
论文
这个数据集主要用于对patch类材料进行分类,对全景类材料进行分割。其包括23个类别的分割标注:木头(wood)、油漆(painted)、布(fabric)、玻璃(glass)、金属(metal)、瓷砖(tile)、天空(sky)、叶子(foliage)、打磨的石头(polished stone)、地毯(carpet)、皮革(leather)、镜子(mirror)、砖头(brick)、水(water)、其他(other)、塑料(plastic)、皮肤(skin)、石头(stone)、陶瓷(ceramic)、头发(hair)、食物(food)、纸(paper)、墙纸(wallpaper)。数据集共包括7061个标注好的材料作为训练集,5000个作为测试集,2500个作为验证集。大部分图像来源于OpenSurfaces dataset,其也从诸如Flickr或Houzz这样的图像来源分割而来。因此,MINC数据集的图像分辨率是变化的。总的来说,分辨率大概在800x500或500x800左右。
Densely-Annotated VIdeo Segmentation (DAVIS)
论文1 论文2 | 网址
这个挑战赛针对的是视频目标分割。其数据集由50个高清(high-definition)序列组成,一共含有4219帧训练集和2023帧验证集。视频序列的分辨率虽然不同,为了挑战赛所有的帧都被压缩到了480p(高为480)。每帧都有逐像素标注,包括4个类别:人、动物、交通工具、物体。这个数据集的另一个特点是,每个序列都包括至少一个前景目标物体。除此之外,数据库默认没有许多具有大位移的物体。对于那些有多个前景物体的场景,数据库针对每一个都提供了真值,从而允许实例分割。
Stanford background
论文 | 网址(慎点,直接下载数据集)
来自于现有数据集(LabelMe, MSRC, PASCAL VOC, Geometric Context)的室外场景图片。数据集包括715张图片(尺寸320x240像素),至少有一个前景目标,且包含图片内的水平位置信息。数据集逐像素标注(水平位置、像素分割类别、像素几何学类别、图像区域)用于评估场景理解分割算法。
SiftFlow
论文
包括2688张全标注的图像,其是LabelMe数据库的一个子集。大部分图像基于8类室外场景,包括路(street)、山、田野(fields)、沙滩、建筑。图像尺寸为256x256,属于33个语义类别。未标注的像素或者标注为不同类别的像素被视为“未标注”。
2.5D数据库
NYUDv2
论文 | 网址
这个数据集包括1449个用Microsoft Kinect设备获取的室内RGB-D图像。Gupta等人将其提供了逐像素稠密标注(类别和实例级)合并到了40个室内场景类别中,包括795张训练集图片和654张测试集图片。这个数据集的室内场景属性使得其特别适合一些家居机器人的任务。然而,其相对较小的规模阻碍了它在深度学习结构上的应用。
SUN3D
论文 | 网址
与NYUDv2类似,这个数据库包含大尺寸的RGB-D视频数据,共有8个标注的序列。每帧都有物体的语义标注以及相机位姿。这个数据库仍在更新,其将包括在41个不同的建筑中的254个不同空间内拍摄的415个视频序列。除此之外,每个位置都有在一天内不同时间下拍摄的结果。
SUNRGBD
论文 | 网址
这个数据库由4个RGB-D传感器拍摄得到,包括10000张RGB图片,规模与PASCAL VOC相近。其包括来自于NYU depth v2、Berkeley B3DO和SUN3D的图片。整个数据集是稠密标注的,包括polygons、带朝向的bounding boxes、以及3D房间平面图和类别,适合场景理解任务。
The Object Segmentation Database (OSD)
网址
(注:这个数据库博主没有找到文中所提到的对应的论文。)
这个数据库主要用于在场景中分割出未知的目标(即使在遮挡条件下),包括111个条目(entries),同时提供深度图和彩色图像,并含有每组图片的逐像素标注,用于评估物体分割方法的表现。然而,这个数据库没有对不同物体的类别区分,因此其类别就退化为两类:是目标和不是目标。
RGB-D Object Dataset
论文 | 网址
这个数据库由300个常见家用物体的视频组成,所有物体按照WordNet hypernym-hyponym(上下位)关系共分为51个类别。数据库由Kinect格式3D相机以30 H z Hz Hz频率同时记录640x480分辨率的RGB图像和深度图像。对于每一帧,数据库都提供对应的RGB-D图像深度图像,每个裁剪图像(croped ones)都包含物体、位置、逐像素标注的mask。此外,每个物体都被放置在一个转盘上,单独提供约360度的视频序列。对于验证过程,数据库提供22个标注好的视频序列,内容为包括已提供物体的自然室内场景。
3D数据库
纯3D数据库比较匮乏,这种数据库通常提供计算机辅助设计(CAD,Computer Aided Design)网格或其他立体描述(比如点云)。生成用于分割的大规模3D数据库成本很高,也很困难,且很少有深度学习算法能够直接以数据本身的类型对其进行处理。基于这些原因,目前3D数据库不是非常流行。尽管如此,我们仍然描述了一些手头有的最受认可的数据库。
ShapeNet Part
论文 | 网址
这是ShapeNet的一个子集,主要关注fine-grained 3D目标分割。其包括从原始数据库的16个类别(飞机、耳机、帽子cap、摩托车、包、杯子mug、笔记本电脑、桌子、吉他、刀、火箭、灯lamp、椅子、手枪pistol、车、滑板skateboard)中提取的31693个mesh。比如,每个从类别“飞机”中提取的mesh都会被标注有翅膀、机身、尾翼、发动机。从mesh中采样得出的point会被标注有真值标注。
Stanford 2D-3D-S(室内)
论文 | 网址1 网址2
这个数据库包括多种模型下的大规模室内场景,由斯坦福3D语义理解(Stanford 3D Semantic Parsing)工作中扩展来的。其提供了带有语义标注的多种类型:2D(RGB)、2.5D(深度图+曲面法线)、3D(网格和点云)。数据库包括70496张高分辨率(1080x1080)的RGB图像以及其对应的深度图、表面法线、网格(mesh)和带有语义标注的点云(逐像素或逐点)。这些图片跟别从来自于3座不同的教学或工作建筑中的6个不同室内场景得来。一共有271个房间和大约7亿个带有标注的点,来自于13个类别:天花板、地板、墙、柱子(column)、房梁(beam)、窗户、们、桌子、椅子、书柜(bookcase)、沙发、黑/白板(board)、杂物(clutter)。
A Benchmark for 3D Mesh Segmentation
论文 | 网址
这个数据库包括属于19个类别(人、杯子、玻璃、飞机、蚂蚁、椅子、章鱼、桌子、泰迪Teddy、收、钳子镊子plier、与、鸟、犰狳armadillo、半身像bust、机械mech、轴承bearing、花瓶vase、四脚fourleg)的380个网格。每个网格都由人工标注成不同的操作部件(functional parts),其主要目的是提供一种概念:“人类如何将每个东西分割成操作部件”。
由于这个数据库的类别比较奇怪,博主把图片放在下面,给大家一点提示。

Sydney Urban Objects Datasets(道路)
论文 | 网址
这个数据库包括多种由Velodyn HDK-64E LIDAR采集的常见城市道路目标。共有631个单独的目标点云,分属类别交通工具、行人、路标、树。特别地,除了单独的扫描(scans),数据库还提供标注好的全景360度扫描。
Large-Scale Cloud Classification Benchmark
论文 | 网址
这个数据库提供多种自然和城市景观的人工标注的3D点云,包括教堂、街道、铁轨(railroad tracks)、广场、村庄、足球场、城堡等。这个数据库的特点是点云数据包括精细的细节且密度高。其包含用于训练的15个大规模点云,另外15个用于测试。其规模可以通过这一点来理解:其包含有超过10亿个已标注的点。

方法
目前比较成功的语义分割state-of-the-art深度学习技巧大部分都来自于同一个先驱:Long等人提出的Fully Convolutional Network (FCN)(博主之前的文章有提到这个网络,感兴趣具体细节可以看这里)。FCN证明了在分割问题上可以通过端到端网络实现,因此被视为milestone,也基于多种原因(如博文中说的),FCN成为了应用深度学习解决语义分割的奠基石。卷积过程如下图所示:

FCN的局限:
- 没有考虑全局信息
- 没有默认的实例敏感度
- 效率远远达不到实时
- 不能够直接适应不定型数据,如3D点云或模型
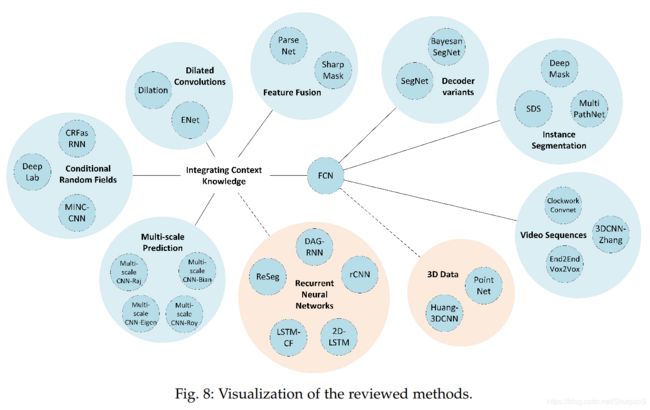
下表给出了本章将总结的方法,每个方法都有1至3星(*)的标注,以指明其对于该问题的关注程度,若该问题没有被考虑则用标注(X)表示。

下图给出了将要讨论的方法的关系,用于直观的感觉。
译码器变体(Decoder Variants)
除了基于FCN的网络结构,还存在一些由分类网络改编的用于分割任务的网络。毋容置疑,基于FCN网络的结构更受欢迎且效果更好,但也存在许多其他同样优秀的选择。总体来讲,这些网络都会采用一个用于分类任务的结构,比如VGG-16等,再移除其全连接层。这一类分割结构通常被命名为编码器(encoder),它们生成的是低分辨率图像的特征图。那么剩下的问题就是如何从这些低分辨率图像的特征图中学习得到全分辨率的像素级分割结果。这个过程的网络通常被称为译码器(decoder),这个部分也是这一类网络结构不同的地方。
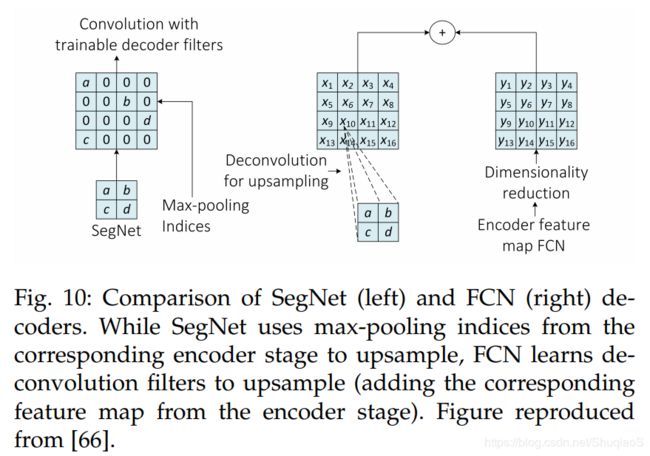
SegNet(博主另一篇文章有介绍)可以很明显地体现这种不同,其网络结构如下图所示。SegNet的解码部分有一系列上采样和卷积层构成,最后是一个softmax分类器,用于估计得到一个与输入图像分辨率相同的像素级的标签。每个解码器中的上采样都对应编码器中的一个max-pooling层。

此外,基于FCN的网络结构利用可学习的deconvolutional filters进行上采样操作。之后,上采样后的特征图被element-wise加回到编码器所生成的对应的部分。下图表示了这两种方法。
整合上下文信息
语义分割这个任务需要整合多空间尺寸下的信息,也意味着整合局部和全局信息。一方面,详细的和局部信息对于实现高精度像素级分割至关重要;而另一方面,也需要整合图像中的全局上下文以防止局部混淆(local ambiguities)。
Vanilla CNNs(即原始的CNNs)费尽心思保持二者的平衡。Pooling层允许网络实现某种程度上的空间不变性,同时保持计算量相对较低的情况下处理全局信息。即使是纯CNNs(没有pooling层),也会受到感受野尺寸的限制,因为感受野只能随着层数的增加线性增长。
许多方法都可以使得CNN意识到全局信息:利用条件随机场(CRFs)作为后处理优化结果,扩张卷积(dilated convolutions),多尺度整合(multi-scale aggregation),或者甚至将上下文模型换成另外一种网络结构(比如RNNs)。
条件随机场(Conditional Random Fields)
CRF将诸如像素间相互关系(文献1,文献2)等低级图像信息和生成逐像素score的多类别推理系统整合起来。这种结合对于捕获远程依赖关系和维护细节至关重要,而这恰恰是CNNs没有考虑到的。
DeepLab模型(文献1,文献2,博文)利用了Krahenbuhl和Koltun的pairwise CRF(文献1,文献2)作为单独的后处理部分。其将每个像素视为场内的一个点(node),然后对没对点(无论相距多远)都应用一个pairwise term(这个模型被称为dense or fully connected factor graph)。应用这个模型后,无论是近距离还是远距离相互关系都被考虑了,这就使得那些被CNN空间不变性忽略掉的细节结构信息被恢复了。尽管全连接模型通常效率不高,但是这个模型可以通过probabilistic inference有效近似。
下图显示了基于CRF的后处理对于DeepLab模型的影响。

Bell等人提出的用wild network实现的材料识别用了多种训练好的CNNs识MINC数据库中的图块。他们以滑动窗口的形式使用这些CNNs以区分图块。Their weights are transferred to the same networks converted into FCNs by adding the corresponding upsamplinglayers(这一句博主没看懂……欢迎评论)。随后,平均输出得到最终的probability map。最后,应用与DeepLab相同的CRF(但是分开优化(discretely optimized))以估计和优化每个像素的材料。
另一个应用CRF优化FCN分割的是由Z恒等人提出的CRFasRNN。这篇论文的主要贡献之一是用对势(pairwise potentials)将稠密CRF视作一个整体重新公式化。By unrolling the mean-field inference steps as RNNs, they make it possible to fully integrate the CRF with a FCN and train the whole network end-to-end。(这句话太专业了,涉及到的物理知识,感兴趣可以点连接看一下。)这项工作将CRFs重新公式化为RNNs以构建深度网络的一部分,刚好与Pinheiro等人的工作相反,他们利用RNNs来模拟大空间依赖(large spatial dependencies)。
扩张卷积(Dilated Convolutions)
Dilated convolutions也称作a-trous convolutions,是Kronecker-factored convolutional filters的一般化(generalization),其支持感受野的指数扩展且不需要牺牲分辨率。换言之,dilation convolution是利用upsampled filters的归一化。扩张率(dilation rate) l l l控制着上采样因子(upsampling factor)。如下图所示,堆叠的 l l l-dilated卷积使得感受野成指数增长,而网络参数却是线性增长的。这意味着,扩张卷积允许任何分辨率下的有效稠密特征提取。特别需要注意的是,典型的卷及操作其实就等同于1-dilated convolution。
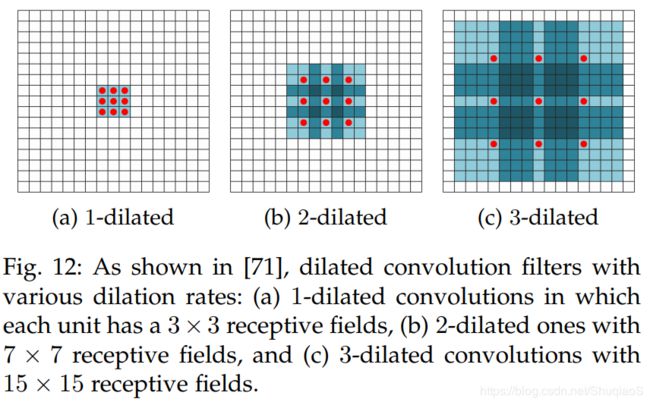
实践中,这与在常规卷积操作之前扩张滤波器的效果是等同的,即根据dilation rate扩张滤波器的尺寸,再用0填满空的区域。换句话说,当dilation rate大于1的时候,滤波器的权重对应的将不再是与之相邻的元素,而是较远距离的元素。下图给出了dilated filter的示例。
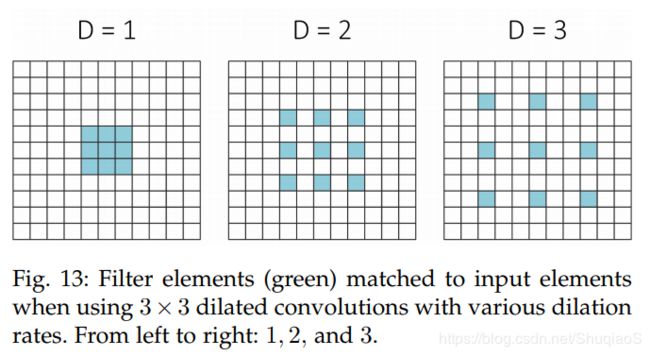
用到扩张卷积最重要的工作就是Yu等人提出的multi-scale context aggregation module、之前提到的DeepLab(及其改进版本)和实时网络ENet。上述这些工作都用到了逐步增加的扩张率的扩张卷积的组合以实现在不增加额外代价的基础上增加感受野,同时也避免了对特征图的过度下采样。这些工作显示出了一个共同的趋势:扩张卷积与多尺度上下文整合(multi-scale context aggregation)有着密不可分的关系。
多尺度估计(Multi-scale Prediction)
另一个实现上下文信息整合的方法就是多尺度估计。CNN中的几乎每一个参数都影响着生成的特征图的scale。因此,滤波器就影响了所提取到的特征到底对应了多大的输入尺寸(想必有一定的不变性程度)。为了解决实际应用中可能遇到的不同尺度之间的问题,一个比较普遍的操作就是用神经网络提取多尺度下的信息,随后再将这些信息整合成一个输出。
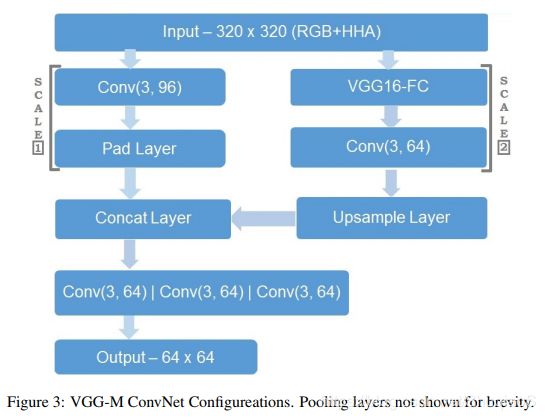
Raj等人提出了一个全卷积VGG-16的多尺度版本,该网络有两条分支,一个用于处理原始分辨率下的输入,另一个则将原始分辨率翻倍。第一条通路经过一个浅卷及网络(shallow convolutional network),第二条通路经过一个全卷积网络VGG和一个额外的卷积层。第二条通路的输出经过上采样与第一条通路的输出整合。整合的结果通过另一个卷积层组成的集合,生成最终输出。因此,这个网络对于尺度变化更加鲁棒。下图是该网络的网络结构。
Roy等人用四个多尺度CNN实现了另外一种方法,这四个网络的结构与Eigen等人提出的结构(下图来源于此结构)相同。其中一个网络用来为场景查找语义标签,该网络采用由粗而细逐渐变化的一系列尺度提取特征(如下图所示)。

另一个值得一提的网络是Bian等人提出的网络,该网络由 n n n个用于处理不同尺度的FCNs组成。这些网络提取到的特征经过整合(必要的上采样和合适的padding)后经过一个额外的卷积层以生成最终的跟个结果。这个结构的追要贡献是two-stage学习过程,该过程先单独训练每个网络,再将结果整合进行fine-tune。这个多尺度模型可以有效增加任意数量的新训练的网络。
特征融合(Feature Fusion)
另一个将上下文信息加到用于分割的全卷积网络的方法是特征融合。这种方法将全局特征(由网络前几层提取)和由后几层提取的局部特征融合在一起。如FCN等常见结构通常利用skip connections连接不同层提取出来的特征。如下图所示。(late fusion)

另一种方法是早期融合(early fusion)。ParseNet采用了这种方法。全局特征被unpool成与局部特征相同的空间尺寸,之后将它们级联(concatenate)在一起以组成一个新的特征,再进入之后的层学习得到一个分类器。下图展示了该过程。

Pinheiro等人在他们的SharpMask网络中延续了这个特征融合的概念,which introduced a progressive refinement module to incorporate(包含) features from the previous layer to the next in a top-down architecture。这个网络主要关注实例分割,因此在后面再详细介绍。
循环神经网络(Recurrent Neural Network)
尽管CNNs能够成功地处理多维度数据(比如图像),但是其依赖人工指定的核函数(hand specified kernels),限制了该结构在局部上下文处理上的表现。循环神经网络(RNNs)的拓扑结构使得其在长、短时间间隔序列的处理上非常成功。考虑到这一点,通过连接像素级局部特征,RNNs能够成功地model全局上下文,从而提升语义分割的效果。
基于用于图像分割的ReNet模型,Visin等人提出了称为ReSeg的用于语义分割的结构,如下图所示。这一方法中,输入图像首先由前几层的VGG-16网络进行处理,随后将得到的特征数输入一个或多个ReNet层中fine-tuning。最后,特征图通过基于转置卷积(transposed convolutions)组成的上采样层。这里应用了Gated Recurrent Units (GRUs),因为其能够很好地平衡内存消耗和计算能力(computational power)。原始RNNs会面临梯度消失的问题,因此没有办法处理远距离依赖。Long Short-Term Memory (LSTM) 网络和GRUs是最近几种解决了这个问题的衍生的模型。

受到同种ReNet结构的启发,论文提出了一种新颖的Long Short-Term Memorized Context Fusion (LSTM-CF)模型用于场景标注。这种方法中他们使用了两种不同的数据源:RGB和深度。RGB分支依赖的是一种DeepLab结构变体,用于将三个不同尺度下的特征进行整合,从而丰富特征描述(受到这篇论文的启发)。The global context is modeled vertically over both, depth and photometric (光度计的) data sources, concluding with a horizontal fusion in both direction over these vertical contexts.
论文作者注意到,通过在水平地和竖直地在输入图像上应用网络,图像全局信息的建模与2D循环方法之间可以联系起来。(原文:As we noticed, modeling image global contexts is related to 2D recurrent approaches by unfolding vertically and horizongtally the network over the input iamges.)基于这个思想,Byeon等人提出了一个简单的2D LSTM-based结构,其将输入图片分成不重叠的窗口,分别送入四个独立的LSTM记忆模块(memory blocks)。这个工作的亮点在于在单核CPU上的低运算复杂度和简单模型。
另一种提取全局信息的方式是基于更大的输入窗口,从而能够建模更多的上下文。然而,这种方法降低了图像的分辨率,也引入了由于窗口重叠造成的问题。尽管如此,PinHeiro等人提出了一种Recurrent Convolutional Neural Network (rCNNs),其能够在考虑到前序用不同窗口尺寸产生的估计的基础上,重复用不同尺寸的输入窗口进行训练。如此一来,估计标签被自动平滑了,从而提升了算法表现。
无向循环图(Undirected cyclic graphs,UCGs)也同样可以用于语义分割的图像上下文建模。尽管如此,RNNs也不是直接可以应用于UCG的,这个问题需要分解成几个定向图(directed graphs,DAGs)。这个方法用三层不同的层来处理图像:由CNN提取图像特征图,用DAG-RNNs建模图像上下文依赖关系,用反卷积层上采样特征图。这项工作展示了RNNs如何可以与图(graphs)组合在一起,成功建模长距离上下文依赖关系(long-range contextrual dependencies)。
实例分割(Instance Segmentation)
实例分割通常被视作是语义分割的下一步,也是与其他low-level像素分割任务相比最难的一个。其主要目的是将从属于同一类别的物体区分成不同的实例。这一过程的自动实现不是很直观,因此,通常实例的个数最开始是不知道的,算法的评估也不是像语义分割那样逐像素进行。尽管这个问题没有被完全解决,仍然有很多人考虑到其潜在的应用场景而热衷于这个问题。实例标注给我们提供了额外的信息用于在遮挡情况下的判断,可以帮助我们了解属于同一类别的物体的个数,也可以辅助机器人抓取任务中检测特定目标,等等。
基于此,Hariharan等人提出了Simultaneous Detection and Segmentation (SDS)方法用于提高现存算法的表现。该算法首先应用了自下而上的层级图像分割和候选目标生成过程(称为Multi-scale Combinatorial Grouping, MCG)以获得区域方案(region proposal)。对于每一个区域,通过Region-CNN(R-CNN)的一个适应性版本提取特征,随后用MCG方法提供的bounding box进行fine-tune,替代了selective search。之后,通过一个线性支持向量机(Support Vector Machine, SVM)在CNN特征的基础上实现区域方案的分类。最后,应用非极大值抑制(Non-Maximum Suppression,NMS)对之前的proposal进行优化。
随后,Pinheiro等人提出了基于单个ConvNet的object proposal方法——DeepMask模型。给定一个输入图块,这个模型给出每个图快的segmentation mask,同时给出图块中包含目标的概率。这两个任务是同时习得的,由一个网络实现,该结构共享除了最后几层task-specific以外的大多数层。
基于高效的DeepMask结构,其作者又提出了一个用于目标实例分割的新型结构。该结构采用了自上而下的精调过程(top-down refinement process),并在精度和速度上表现良好。这个过程的目标是为了有效将low-level特征与网络upper network layers提取的high-level语义信息融合在一起。这个网络结构由堆叠在一起的不同refinement modules组成(每个module都有一个pooling layer),从而将pooling操作转化成上采样目标编码。下图是SharpMask中的refinement module。

Zagoruyko等人提出了一种MultiPath分类器,该方法以Fast R-CNN开始,利用DeepMask object proposal而非Selective Search。该方法在COCO数据集上提升了效果,并推理对Fast R-CNN做了如下三点修改:以聚合损失提高定位表现,用中心凹(foveal)区域提供上下文信息,用skip connections为网络提供多尺度特征。该系统对其baseline Fast R-CNN提升了66%。
可以看出,上面提到的方法到部分是基于现存的目标检测器提出的,因此限制了它们的表现。即便如此,实例分割仍然是一个未解决的问题,上面的方法也只是这个具有挑战性的领域的一部分成果。
RGB-D数据
尽管大量的方法都是基于光度数据(photometric data)提出的,低成本RGB-D传感器提供了包含几何线索(geometric clue)的深度信息(depth information)激励了结构信息(structural information)的使用。基于深度信息的分割任务相对较困难,因为不可预测的场景光照以及遮挡问题。尽管如此,仍有许多成功利用深度信息增加精度的工作。
将深度信息利用在关注光度数据的方法上不是很直观的,需要将深度数据编码到每个像素的三通道上(如果是RGB图像的话)。诸如Horizontal Height Angle (HHA)等方法利用如下技术将深度信息编码到三通道上:水平视差、距地高度、局部平面发现与推断重力方向之间的角度。 如此一来,就可以将深度图像输入为RGB图像设计的网络中以学习新的结构信息的特征了。这篇文章等方法就是基于这种编码技巧。
文献中也可以找到一些利用RGB-D数据和多视点方法提高现存single-view方法的工作。
Zeng等人提出了利用多视点RGB-D数据和深度学习技巧的目标分割方法。从每个视点提取的RGB-D图像被传入一个FCN网络,该网络对图像中的每一个像素点输出一个40个类别的概率。概率的阈值的计算方式是:所有视点平均概率的标准差的三倍。他们还训练了用于特征提取的多网络(AlexNet、VGG-16),评估了用深度信息的优势。他们发现引入深度没有对分割表现有明显提升,这可能是由于深度信息中的噪声导致的。 上述方法是在2016 Amazon Picking Challenge上提出的,由于RGB图像是独立送入FCN网络的,该方法被视为是对于多视点深度学习系统的一个小贡献。
Ma等人提出了一种基于多视点深度学习技巧的用于目标类别分割(obejct-class segmentation)的新型方法。多视点由运动的RGB-D相机获得。在训练阶段,相机轨迹通过RGB-D SLAM方法获得,随后RGB-D图像warp到真值标注的帧上以保证多视点训练的一致性。所提方法是基于FuseNet的,其将RGB和深度图像结合起来用于语义分割,Ma等人的方法对该工作增加了多尺度损失最小化。
3D数据
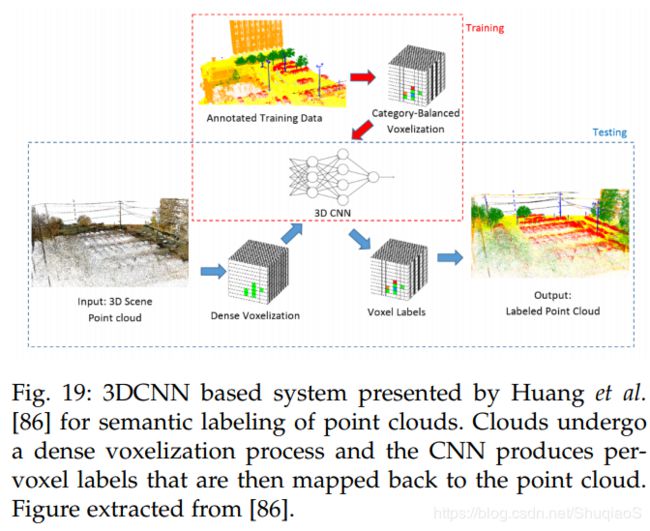
由于大部分成功的分割网络(如CNNs)并不是为了无序数据创造的,因此大部分方法在将3D点云数据或多边数据送入网络之前,都会将它们转化成3D voxel grids或将无结构、无序数据映射成规则描述。比如Huang等人通过稠密体元网格解析点云数据(如下图所示),生成一系列有内容的体元,作为3D CNN的输入,随后生成每个体元的标签。之后,再将标签映射回点云。尽管该方法能够成功应用,但也有许多局限,比如数字化(quantization)、丢失空间信息、比必要的大规模描述。基于这些原因,许多研究人员致力于研究出能够直接处理3D点云集合或mesh的网络。
PointNet是最早提出深度神经网络可以直接处理点云数据的论文,其给出了一个集分割和分类任务为一体的神经网络。下图显示了其网络结构:
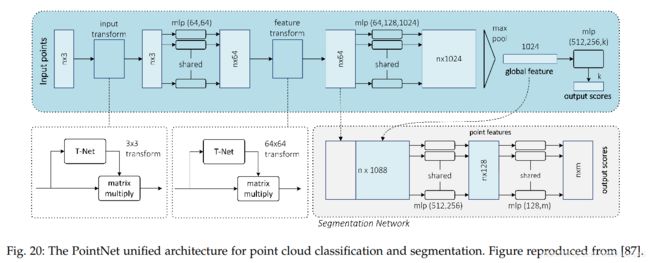
可以看出,PointNet之所以突出,是因为其只用了全连接层,而没有使用卷积层。
(博主关于这篇文章以及其后续研究工作写过博文,感兴趣可以查看:PointNet学习笔记(一)—— 论文、PointNet学习笔记(二)——支撑材料(理论证明)、PointNet++论文学习笔记、《Frustum PointNets for 3D Object Detection from RGB-D Data》论文及代码学习(一)——论文部分、《Frustum PointNets for 3D Object Detection from RGB-D Data》论文及代码学习(二)——代码部分)
视频序列
视频序列的处理问题上,如果完全忽略时间信息而用与图片相同的方式处理是可行的,但是其计算量非常巨大。在这个问题上,Shelhamer等人提出的clockwork FCN是无可争议最了不起的工作。这个网络是FCN对于时间的适应版,其在保证正确率的同时利用时间线索缩短了网络的推理时间。该网络基于这个观察:帧间特征速度(feature velocity,网络中特征改编的时间率(temporal rate))在不同层之间是不同的,即浅层变化快,深层变化慢。基于这个假设,层可以被分成不同级别,并根据它们的深度以不同的更新率处理。如此一来,深层特征可以由于它们的语义稳定性而在帧之间传递,从而节省了推理时间。下图是Clockwork FCN的网络结构。

Clockwork FCN的作者提出了两种更新率:固定的(fixed)和适应的(adaptive)。前者设定了一个固定时间更新特征;后者则以数据启动的方式更新,如下图所示。

Zhang等人利用了3DCNN提出了另外一种方法。3DCNN最初是用于从volumes中学习特征的,比如从多通道输入(如视频)中学习等级化的时空特征(hierarchical spatio-temporal features)。与此同时,他们将视频序列分割成supervoxels,随后学习其中的特征,最后用graph-cut实现每个supervoxel graph的分割。
另一个了不起的工作是Tran等人基于3D卷积(C3D)提出的深度端到端体元到体元估计系统(end-to-end voxel-to-voxel)。下图显示了2D和3D卷积应用到多通道输入时的区别,从而证明了3D卷积在处理视频分割问题上的有效性。

讨论
这一部分给出了前文提到的算法的定量描述,包括运行时间、内存消耗和准确率三个方面。之后列举了可能的未来研究方向。
评估标注
执行时间(Execution Time)
通常来讲,不关心训练时间(除非训练时间过于长),因为训练是一个离线过程。另外,给出具体时间也不太科学。但是,为了方便后面的研究者再现成果,或者帮助人们判断算法是否有用,通常会给出在具体执行条件下的时间以供参考。
内存消耗(Memory Footprint)
尽管内存消耗不如执行时间那么重要,但是对于如机器人用到的板载芯片等的内存不充足的应用场景,限制内存消耗就很必要了。另外,即使是在服务器上,GPU的内存也不是无限的。因此,考察算法的内存消耗也是必要的。
准确率(Accuracy)
目前存在多种准确率度量,通常这些度量都是基于像素准确率(pixel accuracy)和IoU的。这里给出几种用于像素级语义分割的度量。为了表述方便,下面给出几个说明:假设总共有 k + 1 k+1 k+1类(从 L 0 L_0 L0到 L k L_k Lk,包括一个空集/背景), p i j p_{ij} pij表示类别 i i i下的像素点被判断成类别 j j j的像素点的个数。换句话说, p i i p_{ii} pii表示true positives, p i j p_{ij} pij和 p j i p_{ji} pji分别表示false positives和false negative。
-
Pixel Accuracy (PA)
这是最简单的度量,单纯计算正确分类的点的个数,除以总共的像素数:
P A = ∑ i = 0 k p i i ∑ i = 0 k ∑ j = 0 k p i j PA=\frac{\sum_{i=0}^kp_{ii}}{\sum_{i=0}^k\sum_{j=0}^kp_{ij}} PA=∑i=0k∑j=0kpij∑i=0kpii -
Mean Pixel Accuracy (MPA)
PA的改进,分别计算每个类别的正确率,再取平均:
M P A = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j MPA=\frac{1}{k+1}\sum_{i=0}^k\frac{p_{ii}}{\sum_{j=0}^kp_{ij}} MPA=k+11i=0∑k∑j=0kpijpii -
Mean Intersection over Union (MIoU)
这是分割任务中的标准度量,最常用。
M I o U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i MIoU=\frac{1}{k+1}\sum_{i=0}^k\frac{p_{ii}}{\sum_{j=0}^kp_{ij}+\sum_{j=0}^kp_{ji}-p_{ii}} MIoU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii -
Frequency Weighted Intersection over Union (FWIoU)
是MIoU的改进版本,根据不同类别的出现频率对各类别进行加权
F W I o U = 1 ∑ i = 0 k ∑ j = 0 k p i j ∑ i = 0 k ∑ j = 0 k p i j p i i ∑ j = 0 k p i j − p i i FWIoU = \frac{1}{\sum_{i=0}^k\sum_{j=0}^kp_{ij}}\sum_{i=0}^k\frac{\sum_{j=0}^kp_{ij}p_{ii}}{\sum_{j=0}^kp_{ij}-p_{ii}} FWIoU=∑i=0k∑j=0kpij1i=0∑k∑j=0kpij−pii∑j=0kpijpii
结果
这些算法根据它们的输入分成了4类:2D、2.5D、3D、视频序列。
RGB
对于2D类别,这里采用了7个数据库:PASCAL VOC2012、PASCAL Context、PASCAL Person-Part、CamVid、CityScapes、Standford Background和SiftFlow。
下表给出了在最常用的PASCAL VOC2012数据库上给出数据的算法的准确率。可以看出从最早起的SegNet和FCN到后期复杂网络的明显进步趋势。DeepLab精度最高。
PASCAL VOC2012
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DeepLab | 79.70 |
| 2 | Dilation | 75.30 |
| 3 | CRFasRNN | 74.70 |
| 4 | ParseNet | 69.80 |
| 5 | FCN-8s | 67.20 |
| 6 | Multi-scale-CNN-Eigen | 62.60 |
| 7 | Bayesian SegNet | 60.50 |
下表给出了在PASCAL-Context中的结果,DeepLab精度还是最高。
PASCAL-Context
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DeepLab | 45.70 |
| 2 | CRFasRNN | 39.28 |
| 3 | FCN-8s | 39.10 |
PASCAL-Person-Part
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DeepLab | 64.94 |
除了PASCAL数据库,论文还给出了城市驾驶数据库下的表现,如下表所示。
CamVid
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DAG-RNN | 91.60 |
| 2 | Bayesian SegNet | 63.10 |
| 3 | SegNet | 60.10 |
| 4 | ReSeg | 58.80 |
| 5 | ENet | 55.60 |
下表是一个目前更常用但是更有难度的数据库CityScapes下的表现,其中精度变化趋势与PASCAL中差不多。
CityScapes
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DeepLab | 70.40 |
| 2 | Dilation10 | 67.10 |
| 3 | FCN-8s | 65.30 |
| 4 | CRFasRNN | 62.50 |
| 5 | ENet | 58.30 |
Stanford Background
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | rCNN | 80.20 |
| 2 | 2D-LSTM | 78.56 |
SiftFlow
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | DAG-RNN | 85.30 |
| 2 | rCNN | 77.70 |
| 2 | 2D-LSTM | 70.11 |
2.5D
SUN-RGB-D
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | LSTM-CF | 48.10 |
NYUDv2
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | LSTM-CF | 49.40 |
SUN-3D
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | LSTM-CF | 58.50 |
3D
ShapeNet Part
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | PointNet | 83.70 |
Stanford 2D-3D-S
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | PointNet | 47.71 |
视频序列
Cityscapes
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | Clockwork Convnet | 64.40 |
Youtube-Objects
| # | Method | Accuracy (IoU) |
|---|---|---|
| 1 | Clockwork Convnet | 68.50 |
总结及对未来的建议等请参照原文。
附件:术语解释
计算摄影学(Computational Photograyphy)
参考网址
计算摄影学(Computational Photography)是一门将计算机视觉、数字信号处理、图形学等深度交叉的新兴学科,旨在结合计算、数字传感器、光学系统和智能光照等技术,从成像机理上来改进传统相机,并将硬件设计与软件计算能力有机结合,突破经典成像模型和数字相机的局限性,增强或者扩展传统数字相机的数据采集能力,全方位地捕捉真实世界的场景信息。
一般的数码摄影分为两个大步骤:
-
通过相机采集图像;
-
后期处理。
而在每个大步骤里又有很多小的要素,比如第一个步骤里面,需要考虑光照,相机角度,镜头组(光学系统),传感器等等。
第二个步骤涉及到的方方面面就更多了,降噪,调曲线,各种PS滤镜等等。如果这其中的每一个要素,我们都想办法进行拓展和改变。比如用特殊手段照明,可以从不同角度,或者按一定的时序打闪光灯,再或者用可见光之外的光。
又比如改变光学系统,可以调整光圈大小,调整相机镜头位置,或是改变光圈形状等。而每一项采集图像的改变,往往都需要相应的计算机算法后期处理,甚至采集到的数据可以用除了普通显示器以外的方式呈现,那么前面这些一套的成像办法,就都可以归入计算摄影学的范畴。
更笼统一下,就是拓展了传统数码摄影中的某个或多个因素的维度来成像的方法,就是计算摄影学。
其实现在早就被用的烂熟的HDR就是计算摄影学中的一种办法,拓展的是传统成像中的光圈大小。
那么,就当前计算摄影学的发展而言,这些拓展和改变都主要集中在哪些因素上呢?MIT的Raskar教授早就给出过结论:光学系统、传感器、照明和后期处理。
高光谱图像(hyperspectral images)
参考网址
光谱分辨率在10l数量级范围内的光谱图像称为高光谱图像(Hyperspectral Image)。遥感技术经过20世纪后半叶的发展,无论在理论上、技术上和应用上均发生了重大的变化。其中,高光谱图像技术的出现和快速发展无疑是这种变化中十分突出的一个方面。通过搭载在不同空间平台上的高光谱传感器,即成像光谱仪,在电磁波谱的紫外、可见光、近红外和中红外区域,以数十至数百个连续且细分的光谱波段对目标区域同时成像。在获得地表图像信息的同时,也获得其光谱信息,第一次真正做到了光谱与图像的结合。与多光谱遥感影像相比,高光谱影像不仅在信息丰富程度方面有了极大的提高,在处理技术上,对该类光谱数据进行更为合理、有效的分析处理提供了可能。因而,高光谱图像技术所具有的影响及发展潜力,是以往技术的各个发展阶段所不可比拟的,不仅引起了遥感界的关注,同时也引起了其它领域(如医学、农学等)的极大兴趣。
高光谱遥感的发展得益于成像光谱技术的发展与成熟。成像光谱技术是集探测器技术、精密光学机械、微弱信号检测、计算机技术、信息处理技术于一体的综合性技术。其最大特点是将成像技术与光谱探测技术结合,在对目标的空间特征成像的同时,对每个空间像元经过色散形成几十个乃至几百个窄波段以进行连续的光谱覆盖。这样形成的数据可以用“三维数据块”来形象地描述,如右所示。其中x和y表示二维平面像素信息坐标轴,第三维(λ轴)是波长信息坐标轴。高光谱图像集样本的图像信息与光谱信息于一身。图像信息可以反映样本的大小、形状、缺陷等外部品质特征,由于不同成分对光谱吸收也不同,在某个特定波长下图像对某个缺陷会有较显著的反映,而光谱信息能充分反映样品内部的物理结构、化学成分的差异。这些特点决定了高光谱图像技术在农产品内外部品质的检测方面的独特优势。
高光谱影像是收集及处理整个跨电磁波谱的信息,不像是人类的眼睛,只能接触到可见光。而高光谱的接触机制、比如虾蛄的眼睛它的光谱能够接触到红外线延伸到紫外线的范围。高光谱的能力能够使虾蛄分辨出不同的珊瑚、猎物,或则猎食者,而这些正是人类所缺少的.

迁移学习
参考网址
Transfer learning is a research problem in machine learning that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem.[1] For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks. This area of research bears some relation to the long history of psychological literature on transfer of learning, although formal ties between the two fields are limited.
The earliest cited work on transfer in machine learning is attributed to Lorien Pratt, who formulated the discriminability-based transfer (DBT) algorithm in 1993.[2]
In 1997, the journal Machine Learning published a special issue devoted to transfer learning,[3] and by 1998, the field had advanced to include multi-task learning,[4] along with a more formal analysis of its theoretical foundations.[5] Learning to Learn,[6] edited by Pratt and Sebastian Thrun, is a 1998 review of the subject.
Transfer learning has also been applied in cognitive science, with the journal Connection Science publishing a special issue on reuse of neural networks through transfer in 1996.[7]
Algorithms are available for transfer learning in Markov logic networks[8] and Bayesian networks.[9] Transfer learning has also been applied to cancer subtype discovery, [10] building utilization,[11][12] general game playing,[13] text classification[14][15] and spam filtering.[16]

TOP-5 test accuracy
参考网址
Task
Task 1: Classification
For each image, algorithms will produce a list of at most 5 object categories in the descending order of confidence. The quality of a labeling will be evaluated based on the label that best matches the ground truth label for the image. The idea is to allow an algorithm to identify multiple objects in an image and not be penalized if one of the objects identified was in fact present, but not included in the ground truth. For each image, an algorithm will produce 5 labels l j , j = 1 , . . . , 5 l_j,j=1,...,5 lj,j=1,...,5. The ground truth labels for the image are g k g_k gk, k = 1 , . . . , n k=1,...,n k=1,...,n with n classes of objects labeled. The error of the algorithm for that image would be e = 1 n ⋅ ∑ k min j d ( l j , g k ) e=\frac{1}{n}⋅\sum_k{\min_jd(l_j,g_k)} e=n1⋅∑kminjd(lj,gk). d ( x , y ) = 0 d(x,y)=0 d(x,y)=0 if x = y x=y x=y and 1 otherwise. The overall error score for an algorithm is the average error over all test images. Note that for this version of the competition, n=1, that is, one ground truth label per image. Also note that for this year we no longer evaluate hierarchical cost as in ILSVRC2010 and ILSVRC2011.
Task 2: Classification with localization
In this task, an algorithm will produce 5 class labels l j l_j lj, j = 1 , . . . , 5 j=1,...,5 j=1,...,5 and 5 bounding boxes b j b_j bj, j = 1 , . . . 5 j=1,...5 j=1,...5, one for each class label. The ground truth labels for the image are g k g_k gk, k = 1 , . . . , n k=1,...,n k=1,...,n with n classes labels. For each ground truth class label gk, the ground truth bounding boxes are z k m z_{km} zkm, m = 1 , . . . M k m=1,...M_k m=1,...Mk, where M k M_k Mk is the number of instances of the kth object in the current image. The error of the algorithm for that image would be
e = 1 n ⋅ ∑ k min j min m M k max { d ( l j , g k ) , f ( b j , z k m ) } e=\frac{1}{n}⋅\sum_k\min_j\min_m^{M_k}\max\{d(l_j,g_k),f(b_j,z_{km})\} e=n1⋅k∑jminmminMkmax{d(lj,gk),f(bj,zkm)}
where f ( b j , z k ) = 0 f(b_j,z_k)=0 f(bj,zk)=0 if b j b_j bj and z m k z_{mk} zmk has over 50% overlap, and f ( b j , z m k ) = 1 f(b_j,z_{mk})=1 f(bj,zmk)=1 otherwise. In other words, the error will be the same as defined in task 1 if the localization is correct(i.e. the predicted bounding box overlaps over 50% with the ground truth bounding box, or in the case of multiple instances of the same class, with any of the ground truth bounding boxes). otherwise the error is 1(maximum).
Task 3: Fine-grained classification
This year we introduce a third task: fine-grained classification on 100+ dog categories. For each of the dog categories predict if a specified dog (indicated by their bounding box) in a test image is of a particular category. The output from your system should be a real-valued confidence that the dog is of a particular category so that a precision/recall curve can be drawn. The fine-grained classification task will be judged by the precision/recall curve. The principal quantitative measure used will be the average precision (AP) on individual categories and the mean average precision (mAP) across all categories.
WordNet hypernym-hyponym
网址1:WordNet Interface
网址2:Wikipedia(Hyponymy and hypernymy)

Vanilla CNNs
论文:Facial Landmark Detection with Tweaked Convolutional Neural Networks
实现(举例):https://github.com/ishay2b/VanillaCNN
这篇博文中提到:
Vanilla是神经网络领域的常见词汇,比如Vanilla Neural Networks、Vanilla CNN等。Vanilla本意是香草,在这里基本等同于raw。比如Vanilla Neural Networks实际上就是BP神经网络,而Vanilla CNN实际上就是最原始的CNN。
更多内容,欢迎加入星球讨论。