机器学习实战python版Logistic回归
基于Logistic 回归和Sigmoid函数的分类
首先我们要了解Sigmoid函数是什么样的函数,再者这个Logistic回归模型和这个函数的联系。
主要内容可以参见李航的《统计学习方法》第六章有详细的讲解,我是看了里面的内容在对应着看机器学习实战中的代码学习的。
二项逻辑斯蒂回归主要还是在于确定对应特征的权重,来得到Z= W*X,从而根据模型获得输出分类的Y值。
权重的获得是通过梯度下降发来做的,梯度方向总是只想函数值上升的方向,所以我们要找到最佳的拟合系数,就是特征值的权重,我们就需要沿梯度方向不断逼近。
梯度下降法可以参见最优化学习方法。
在这里还是主要是看懂代码。。。。。
训练算法
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))#套函数
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #convert to NumPy matrix
labelMat = mat(classLabels).transpose() #convert to NumPy matrix转置变列向量
m,n = shape(dataMatrix)维度
alpha = 0.001步长
maxCycles = 500循环次数
weights = ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #矩阵相乘 带入函数获得分类100*3 * 3*1
error = (labelMat - h) #vector subtraction误差
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult不断调整
return weights
分析数据
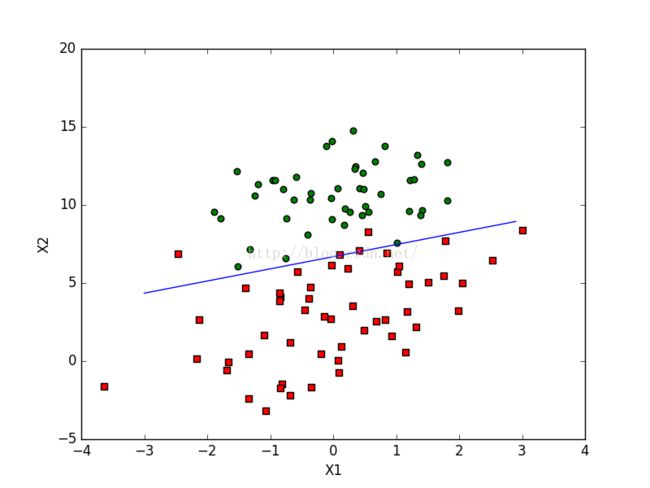
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()x2 =( - w0*1 -w1*x1)/w2;所以代码才会这样写。我们知道偏执变量对应的特征都设为了1.
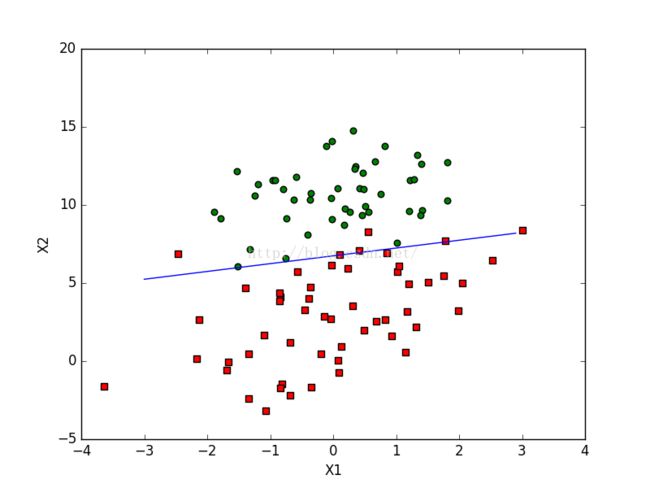
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
这两个函数只是在细节上优化算法,降低运算次数,尽量提高准确度。