python之数据可视化
各种图形简介
线性图:plt.plot(x,y,*argv)
条形图:plt.bar(x,y)x和y的长度应相等
水平条形图:plt.barh(x,y)x轴成垂直,y轴水平而已
条形图高度表示某项目内的数据个数,由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列
直方图:plt.hist(x),数据集种各数据出现的频数/频率图
2d直方图:plt.hist2d(x,y)
直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率,宽度则表示各组的组距,其高度与宽度均有意义
饼状图:plt.pie(a,labels=list('abcde'),autopct='%.2f%%'),
散点图:plt.scatter(x,y,*argv)
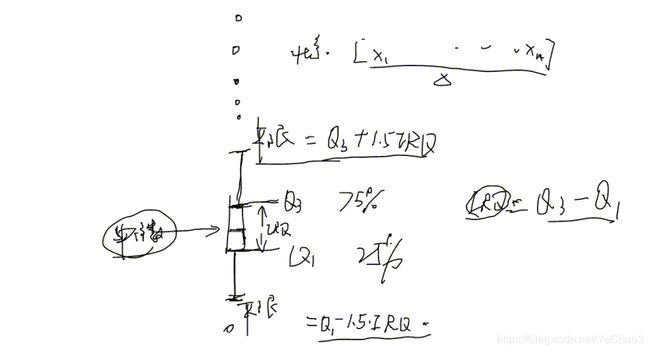
箱形图:plt.boxplot(x)
词云图:wordcloud.WordCloud(*argv)
根据词频和背景图产生的图
直方图/分布:sns.distplot()

制图实例
In [79]: import numpy as np
In [80]: import pandas as pd
In [81]: import matplotlib.pyplot as plt
In [82]: import wordcloud
In [83]: import seaborn
plt.rcParams['font.serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
names = ['mpg','cylinders','displacement','horsepower','weight','acceleration','model_year','origin','car_name']
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data", sep='\s+', names=names)
In [154]: df['maker'] = df.car_name.apply(lambda x: x.split()[0]).str.title()
...: df['origin'] = df.origin.map({1: 'America', 2: 'Europe', 3: 'Asia'})
...: df=df.applymap(lambda x: np.nan if x == '?' else x).dropna()
...: df['horsepower'] = df.horsepower.astype(float)
1.云词
names = ['mpg','cylinders','displacement','horsepower','weight','acceleration','model_year','origin','car_name']
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data", sep='\s+', names=names)
word_dict=dict(df['car_name'])
background=plt.imread('data/back.jpg')
wc = wordcloud.WordCloud(
background_color='white',#背景颜色
font_path='data/simhei.ttf',#字体
mask=background,#背景图
max_words=1000,#最大的字数
max_font_size=100,#最大的字体
colormap='hsv',#色谱
random_state=100#随机种子
)
wc.generate_from_frequencies(word_dict)#根据词频生成wordcloud
plt.imshow(wc)#将wordcloud投影到plt上
plt.axis('off')#去除坐标
plt.savefig('image/DesriptionWordCloud.png', dpi=400, bbox_inches='tight')
2.线性图
In [100]: plt.plot(df.displacement.index,df.displacement.values)
Out[100]: []
In [101]: plt.show()
3.条形图
In [104]: plt.bar(df.displacement.index[:10],df.displacement.values[:10])
Out[104]:
In [105]: plt.show()
4.水平条形图
In [106]: plt.barh(df.displacement.index[:10],df.displacement.values[:10])
Out[106]:
In [107]: plt.show()
5.直方图
In [116]: a=pd.Series([1,2,3,1,2,3,3,4,2,1])
In [117]: plt.hist(a)
Out[117]:
(array([3., 0., 0., 3., 0., 0., 3., 0., 0., 1.]),
array([1. , 1.3, 1.6, 1.9, 2.2, 2.5, 2.8, 3.1, 3.4, 3.7, 4. ]),
)
In [118]: plt.show()
6.饼状图
In [124]: data=[0.2,0.1,0.33,0.27,0.1]
In [125]: plt.pie(data,autopct='%.2f%%',labels=list('abcde'))
Out[125]:
([,
,
,
,
],
[Text(0.889919,0.646564,'a'),
Text(-2.57474e-08,1.1,'b'),
Text(-1.07351,0.239957,'c'),
Text(0.103519,-1.09512,'d'),
Text(1.04616,-0.339919,'e')],
[Text(0.48541,0.352671,'20.00%'),
Text(-1.4044e-08,0.6,'10.00%'),
Text(-0.58555,0.130886,'33.00%'),
Text(0.0564651,-0.597337,'27.00%'),
Text(0.570634,-0.18541,'10.00%')])
In [126]: plt.show()
7.散点图
In [130]: plt.scatter(df.displacement.index,df.displacement.values,color='red')
Out[130]:
In [131]: plt.show()
8.箱形图
In [147]: plt.boxplot(df.iloc[[1,2,3],[1,6]])
Out[147]:
{'whiskers': [,
,
,
,
,
],
'caps': [,
,
,
,
,
],
'boxes': [,
,
],
'medians': [,
,
],
'fliers': [,
,
],
'means': []}
In [148]: plt.show()
8.直方分布图
#方法一
In [150]: sns.distplot(df.displacement.values)
/home/zelin/anaconda3/lib/python3.7/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
Out[150]:
#方法二
In [166]: g = sns.FacetGrid(df, col="origin")
...: g.map(sns.distplot, "mpg")
...:
...:
/home/zelin/anaconda3/lib/python3.7/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
Out[166]:
In [151]: plt.show()
9.关系图
#根据两个维度绘制关系图,即DataFrame的两列
In [155]: sns.factorplot(data=df,x='model_year',y='mpg')
#根据三各维度绘制关系图
sns.factorplot(data=df,x='model_year',y='mpg',col='origin')
#从折线图切成柱状图
sns.factorplot(data=df, x="model_year", y="mpg", col="origin",kind='bar')
10.绘图同时还做回归
In [168]: g = sns.FacetGrid(df, col="origin")
...: g.map(sns.regplot, "horsepower", "mpg")
...: plt.xlim(0, 250)#x轴刻度最大值
...: plt.ylim(0, 60)#y轴刻度最大值
...:
...:
/home/zelin/anaconda3/lib/python3.7/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
Out[168]: (0, 60)
11.等高线图
In [170]: df['tons'] = (df.weight/2000).astype(int)
...: g = sns.FacetGrid(df, col="origin", row="tons")
...: g.map(sns.kdeplot, "horsepower", "mpg")
...: plt.xlim(0, 250)
...: plt.ylim(0, 60)
12.按照两个维度展开画图
g = sns.FacetGrid(df, col="origin", row="tons")
g.map(plt.hist, "mpg", bins=np.linspace(0, 50, 11))
13.多个维度两两组合绘图
g = sns.pairplot(df[["mpg", "horsepower", "weight", "origin"]], hue="origin", diag_kind="hist")
for ax in g.axes.flat:
plt.setp(ax.get_xticklabels(), rotation=45)
14.组合绘图时做回归
g = sns.PairGrid(df[["mpg", "horsepower", "weight", "origin"]], hue="origin")
g.map_upper(sns.regplot)
g.map_lower(sns.residplot)
g.map_diag(plt.hist)
for ax in g.axes.flat:
plt.setp(ax.get_xticklabels(), rotation=45)
g.add_legend()
g.set(alpha=0.5)
15.联合绘图(等高图)
sns.jointplot("mpg", "horsepower", data=df, kind='kde')
16.联合绘图加回归(散点图)
sns.jointplot("horsepower", "mpg", data=df, kind="reg")