Gradle-初探代码注入Transform
简介
本文主要介绍gradle打包过程中transform阶段,这里大概说下AOP(Aspect Oriented Programming),这是一种面向切面的思想,预支对应的是OOP(Object Oriented Programming)面向对象编程,这里不展开说明。可以看下对AOP总结的思维导图
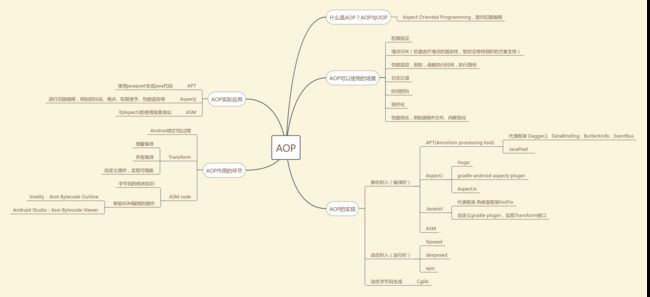
划重点
本篇文章主要介绍下面的几点:
- Transform可以做什么
- 简单了解App打包过程,以及介绍Transform
- 生成自己的MyConfig类文件,有助我们更好理解
- 介绍ASM
Transform可以做什么
最主要的目的就是:解耦,开发人员专注于需求,其他的边角料,交给Transform来处理。
- 权限判断,避免代码中相关的地方都是权限申请和处理的代码
- 无痕埋点,简单的场景可以使用,但是场景比较复杂时,就不好处理了,目前网上没有很好的解决方案
- 性能监控,trace+字节码插桩,完美监控
- 事件防抖,避免短期内多次点击按钮
- 热修复,在所有方法前插入一个预留的函数,可以将有bug的方法替换成下发的方法。
- 优化代码,例如删除项目中体积很大的R文件中的字段、优化内联函数等等
- …
还有很多功能,都值得我们去尝试。
App打包过程 & Transform
首先我们回顾一下App的打包流程,App打包都需要经理哪些流程,每一个步骤都干了什么?
apk打包过程
谷歌官网的一幅图
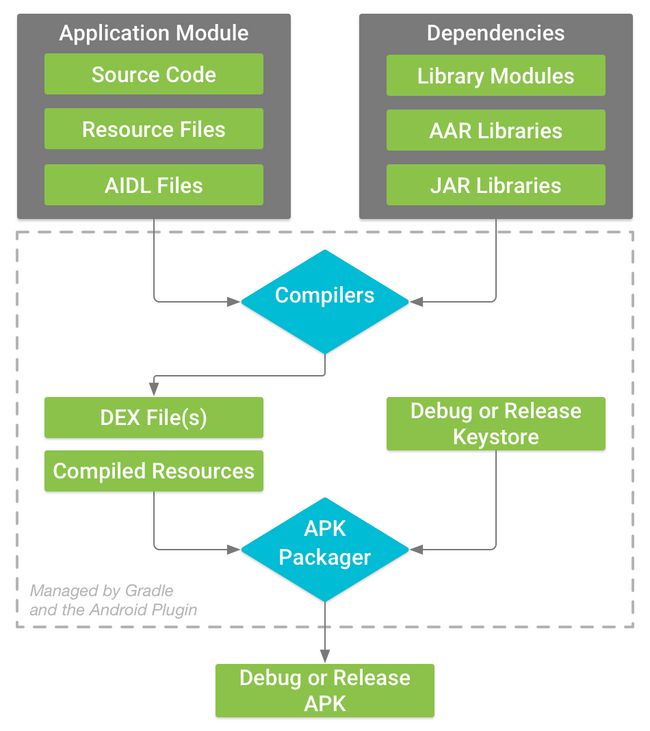
从上面的图中大概理一下流程
- 编译器将app的源码编译成DEX(Dalvik Executable)文件(其中包括运行在Android设备上的字节码),将所有其他的内容转换为已经编译的资源。
- APK打包器将DEX文件和已编译资源合并成单个APK。不过,必须先签署APK,才能将应用安装并部署到Android设备上
- APK打包器使用调试或者发布密钥库签署你的APK:
- 如果你构建的是debug版本应用,打包器会使用debug密钥库签署你的应用,Android Studio自动使用debug密钥库配置新项目
- 如果你构建的是release版本,打包器会使用release密钥库签署你的应用
- 在生成最终APK之前,打包器会使用zipalign工具对应用进行优化,减少其在设备上运行时的内存占用
然后再看一张谷歌之前的打包流程图
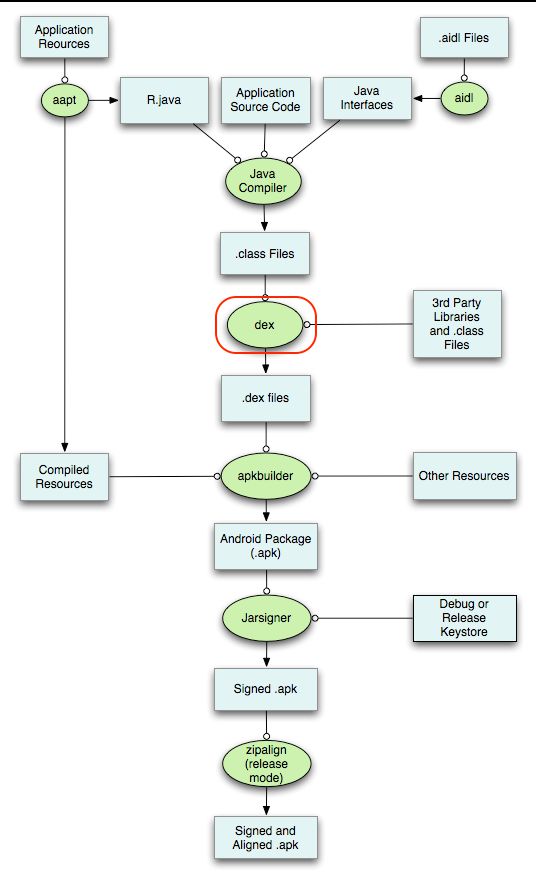
这张图相比较第一张图而言就更加详细了,从这张图中,可以看到打包流程可以分为以下七步:
- aapt-打包res资源文件,生成R.java、resources.arsc和res文件(二进制&非二进制如res/raw和pic保持原样)
- AIDL-Android借口定义语言,Android提供的IPC(Inter Process Communication,进程间通信)的一种独特实现。这个阶段处理.aidl文件,生成对应的Java接口文件。
- Java Compiler-通过Java Compiler编译R.java、Java接口文件、Java源文件,生成.class文件。
- dex-通过dex命令,将.class文件和第三方库中的.class文件处理生成class.dex。
- apkbuilder-将class.dex、resources.arsc、res文件夹(res/raw资源被原封不动的打包进APK之外,其他资源都会被编译或者处理)、OtherResouces(assets文件夹)、AndroidManifest.xml打包进apk文件。
- Jarsigner-对上面的apk进行debug或release签名
- aipalign-将签名后的pak进行对其处理
最后看一张更加详细的图片
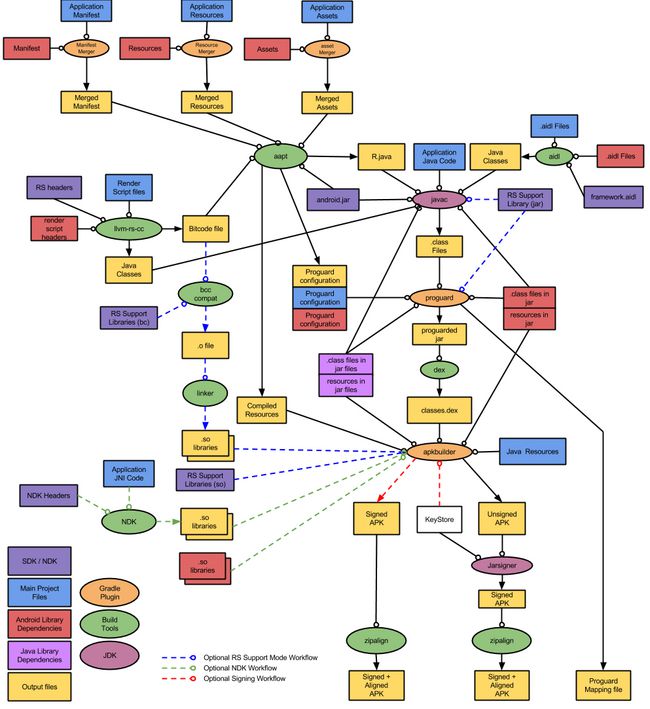
Transform
Transform阶段就是在apk打包图中红圈的位置,第二张图更加详细的表示了Transform的过程,是在.class->.dex的过程。
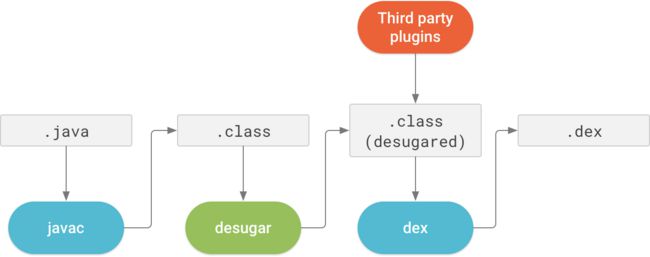
Gradle Transform是Android官方提供给开发者在项目构建阶段由class到dex转换期间修改class文件的一套api。目前经典的应用就是字节码插桩和代码注入技术。有了这个API,我们就可以根据自己的业务需求做一些定制。
先看下transform主要有哪些方法
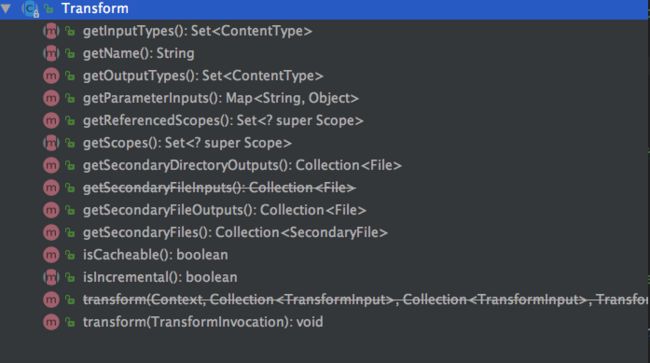
- getName():Transform的名称,但是这里并不是真正的名称,真正的名称还需要进行拼接
- getInputTypes():Transform处理文件的类型
- CLASSES 表示要处理编译后的字节码,可能是jar包也可能是目录
- RESOURCES表示处理标准的java资源
- getScopes():Transform的作用域
type Des PROJECT 只处理当前的文件 SUB_PROJECTS 只处理子项目 EXTERNAL_LIBRARIES 只处理外部的依赖库 TESTED_CODE 测试代码 PROVIDED_ONLY 只处理本地或远程以provided形式引入的依赖库 PROJECT_LOCAL_DEPS (Deprecated,使用EXTERNAL_LIBRARIES) 只处理当前项目的本地依赖,例如jar、aar SUB_PROJECTS_LOCAL_DEPS (Deprecated,使用EXTERNAL_LIBRARIES) 只处理子项目的本地依赖。 - isIncremental():是否支持增量编译,增量编译就是如果第二次编译相应的task没有改变,那么就直接跳过,节省时间,更详细的解释可以看这里
- transform():这是最主要的方法,这里对文件或jar进行处理,进行代码的插入。
- TransformInput:对输入的class文件转变成目标字节码文件,TransformInput就是这些输入文件的抽象。目前它包含DirectoryInput集合与JarInput集合。
- DirectoryInput:源码方式参与项目编译的所有目录结构及其目录下的源文件。
- JarInput:Jar包方式参与项目编译的所有本地jar或远程jar包
- TransformOutProvider:通过这个类来获取输出路径。
通过自定义Plugin创建一个类
我们都知道通过Gradle编译后,会生成一个BuildConfig的类,其中有一些项目的信息,例如APPLICATION_ID、DEBUG等信息,我们依照BuildConfig生成规则,也生成一个自己的MyConfig类,通过这个例子我们可以了解一些gradle的语法和api。
在自定义Plugin类的apply()函数中添加下面的代码
class ConfigPlugin : Plugin<Project> {
override fun apply(project: Project) {
//只在'applicatoin'中使用,否则抛出异常
if (!project.plugins.hasPlugin(AppPlugin::class.java)) {
throw GradleException("this plugin is not application")
}
//获取build.gradle中的"android"闭包
val android = project.extensions.getByType(AppExtension::class.java)
//创建自己的闭包
val config = project.extensions.create("config", ConfigExtension::class.java)
//遍历"android"闭包中的"buildTypes"闭包,一般有release和debug两种
android.applicationVariants.all {
it as ApplicationVariantImpl
println("variant name: ${it.name}")
//创建自己的config task
val buildConfigTask = project.tasks.create("DemoBuildConfig${it.name.capitalize()}")
//在task最后去创建java文件
buildConfigTask.doLast { task ->
createJavaConfig(it, config)
}
// 找到系统的buildConfig Task
val generateBuildConfigTask = project.tasks.getByName(it.variantData.scope.taskContainer.generateBuildConfigTask?.name)
//自己的Config Task 依赖于系统的Config Task
generateBuildConfigTask.let {
buildConfigTask.dependsOn(it)
it.finalizedBy(buildConfigTask)
}
}
}
fun createJavaConfig(variant: ApplicationVariantImpl, config: ConfigExtension) {
val FileName = "MyConfig"
val constantStr = StringBuilder()
constantStr.append("\n").append("package ")
.append(config.packageName).append("; \n\n")
.append("public class $FileName {").append("\n")
config.constantMap.forEach {
constantStr.append("public static final String ${it.key} = \"${it.value}\";\n")
}
constantStr.append("} \n")
println("content: ${constantStr}")
val outputDir = variant.variantData.scope.buildConfigSourceOutputDir
val javaFile = File(outputDir, config.packageName.replace(".", "/") + "/$FileName.java")
println("javaFilePath: ${javaFile.absolutePath}")
javaFile.writeText(constantStr.toString(), Charsets.UTF_8)
}
}
就可以生成MyConfig类,这个类简单定义了一些我们可以在build.gradle中定义的变量,可以分为下面的几个步骤
- 判断是否为application的module(仅在application中进行操作)
- 遍历buildTypes也就是release和debug
- 在对应的buildTypes中创建task
- 设置自定义的task依赖于BUildConfig的Task
- 新建自定义的MyConfig.java文件
Transform的优化:增量与并发
增量
我们想一个问题,遍历一遍项目中所有源文件和jar,时间都是很长的,如果我们每次改一行编译都需要经过这个过程,是很浪费时间。这个时候需要实现增量编译,什么意思呢?增量,顾名思义,就是在已有的基础上,对增加的进行编译,这样在编译过一次的基础上,以后就会大大的缩短时间。
想要开启增量编译,我们需要重写Transform的这个接口,返回true,上面代码中的注释也说明了。
@Override
boolean isIncremental() {
return true
}
这里需要注意一点:不是每次的编译都是可以怎量编译的,毕竟一次clean build完全没有增量的基础,所以,我们需要检查当前的编译是否增量编译。
需要做区分:
- 不是增量编译,则清空output目录,然后按照前面的方式,逐个class/jar处理
- 增量编译,则要检查每个文件的Status,Status分为四种,并且对四种文件的操作不尽相同
- NOTCHANGED:当前文件不需要处理,甚至复制操作都不用
- ADDED、CHANGED:正常处理,输出给下一个任务
- REMOVED:移除outputProvider获取路径对应的文件
@Override
public void transform(TransformInvocation transformInvocation){
Collection<TransformInput> inputs = transformInvocation.getInputs();
TransformOutputProvider outputProvider = transformInvocation.getOutputProvider();
boolean isIncremental = transformInvocation.isIncremental();
//如果非增量,则清空旧的输出内容
if(!isIncremental) {
outputProvider.deleteAll();
}
for(TransformInput input : inputs) {
for(JarInput jarInput : input.getJarInputs()) {
Status status = jarInput.getStatus();
File dest = outputProvider.getContentLocation(
jarInput.getName(),
jarInput.getContentTypes(),
jarInput.getScopes(),
Format.JAR);
if(isIncremental && !emptyRun) {
switch(status) {
case NOTCHANGED:
break;
case ADDED:
case CHANGED:
transformJar(jarInput.getFile(), dest, status);
break;
case REMOVED:
if (dest.exists()) {
FileUtils.forceDelete(dest);
}
break;
}
} else {
transformJar(jarInput.getFile(), dest, status);
}
}
for(DirectoryInput directoryInput : input.getDirectoryInputs()) {
File dest = outputProvider.getContentLocation(directoryInput.getName(),
directoryInput.getContentTypes(), directoryInput.getScopes(),
Format.DIRECTORY);
FileUtils.forceMkdir(dest);
if(isIncremental && !emptyRun) {
String srcDirPath = directoryInput.getFile().getAbsolutePath();
String destDirPath = dest.getAbsolutePath();
Map<File, Status> fileStatusMap = directoryInput.getChangedFiles();
for (Map.Entry<File, Status> changedFile : fileStatusMap.entrySet()) {
Status status = changedFile.getValue();
File inputFile = changedFile.getKey();
String destFilePath = inputFile.getAbsolutePath().replace(srcDirPath, destDirPath);
File destFile = new File(destFilePath);
switch (status) {
case NOTCHANGED:
break;
case REMOVED:
if(destFile.exists()) {
FileUtils.forceDelete(destFile);
}
break;
case ADDED:
case CHANGED:
FileUtils.touch(destFile);
transformSingleFile(inputFile, destFile, srcDirPath);
break;
}
}
} else {
transformDir(directoryInput.getFile(), dest);
}
}
}
}
这样做真的有用吗?让我们用数据说话,首先准备好测试数据,一个demo,对所有的源文件和第三方依赖库进行扫描,使用增量和非增量的模式进行三次编译,然后取平均值。
两种方式计算自定义transform:
./gradlew assembleDebug --profile命令,在根目录的build/reports目录下会生成一个文件,可以查找每一个transform所花费的时间。- 在自定义的transformTask之前记录时间,在执行完后记录所花费的时间,贴一下简单的代码
Task doubleCheckTask = project.tasks["transformClassesWithDoubleCheckTransformFor${variant.name.capitalize()}"]
doubleCheckTask.configure {
def startTime
doFirst {
startTime = System.nanoTime()
}
doLast {
println()
println " --> COST: ${TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startTime)} ms"
println()
}
}
这里我们使用的是第二种方式,我们在每次只改动一行代码的情况下,然后让我们看结论
| 试验次数 | 非增量 | 增量 |
|---|---|---|
| 1 | 1309ms | 151ms |
| 2 | 1093ms | 183ms |
| 3 | 1153ms | 130ms |
可以发现,增量的速度比全量的速度快了将近10倍多,这是增量的文件比较少的情况,但是总的来说增量编译还是会大幅度增加编译的速度。
并发编译
并发编译并不复杂,只需要将上面处理单个jar/class的逻辑,并发处理,最后阻塞等待所有任务结束即可。看下伪代码:
WaitableExecutor waitableExecutor = WaitableExecutor.useGlobalSharedThreadPool();
//异步并发处理jar/class
waitableExecutor.execute(() -> {
//jar织入字节码
return null;
});
waitableExecutor.execute(() -> {
//file织入字节码
return null;
});
//等待所有任务结束
waitableExecutor.waitForTasksWithQuickFail(true);
与增量编译一样,做一些实验对比,用数据说话。
| 试验次数 | 正常编译 | 并发编译 |
|---|---|---|
| 1 | 1309ms | 856ms |
| 2 | 1093ms | 702ms |
| 3 | 1153ms | 790ms |
使用ASM织入代码
从前面几个章节中,了解了自定义Plugin、Transform、Transform的优化,最后一步,就是对目标类进行改造,也就是对class文件进行代码织入
ASM简介
ASM官网中这样介绍ASM
ASM is an all purpose Java bytecode manipulation and analysis framework. It can be used to modify existing classes or to dynamically generate classes, directly in binary form. ASM provides some common bytecode transformations and analysis algorithms from which custom complex transformations and code analysis tools can be built. ASM offers similar functionality as other Java bytecode frameworks, but is focused on performance. Because it was designed and implemented to be as small and as fast as possible, it is well suited for use in dynamic systems (but can of course be used in a static way too, e.g. in compilers).
ASM是用来对Java字节码进行修改和分析的框架。ASM可以用来修改已经存在的类或者动态生成类,它是直接对二进制文件进行操作的。ASM提供了一些常见的字节码转换和分析算法,从这些转换和分析算法中构建定制复杂的转换和代码分析工具。因为它被设计的和实现的非常的小和尽可能得快,所以它非常和用来动态系统(但是也可以用在静态的方式,例如在编译时)
常用字节码框架
常用的字节码框架就三个Aspectj、Javassist、ASM,三个都有什么区别呢?
织入代码的时期
一图胜千言,直接看图
效率和学习成本
- AspectJ:是一个代码生成工具,使用它定义的语法生成规则来编写,基本上要扫描所有的文件,当然AspectJx已经实现的非常的好。最主要的是有个坑,在抖音目前的多module的工程上,是有很多坑的,例如,和后面的Transform过程有一些冲突,导致代码一直织入失败,而且编译的时长也大大增加。
- Javasist:直接操作修改编译后的字节码,而且可以自定义Transform,编译时长可以做很大空间的优化,就是织入代码的效率不如ASM。
有关javassits的使用可以看这篇文章
根据网上的信息,大神得出的数据结果,这里盗用一下,基本上有3倍的差别,文件越多,ASM和Javasist的效率相差就越大。
ASM的用法
ASM框架中的核心类有以下几个:
- ClassReader:用来解析编译过的class字节码文件
- ClassWriter:用来重新构建编译后的类,比如修改类名、属性以及方法,甚至可以生成新的类的字节码文件
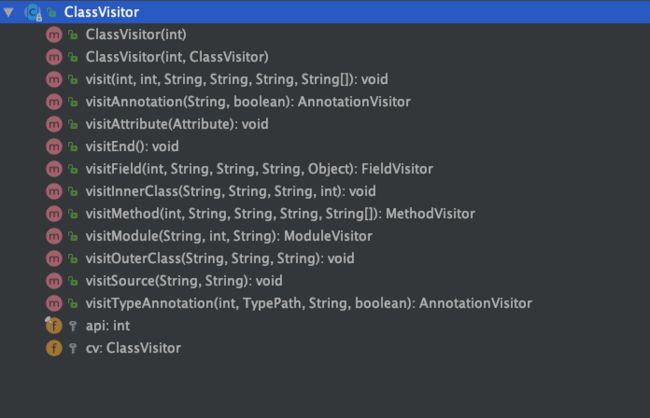
- ClassVisitor:主要负责“拜访”类成员信息。其中包括标记在类上的注解、类的构造方法、类的字段、类的方法、静态代码块。
- AdviceAdapter:实现了MethodVisitor接口,主要负责“拜访”方法的信息,用来具体的方法字节码操作。
ClassVisitor的全部方法如下,按一定的次序来遍历类中的成员
让我们简单写个demo,这段代码很简单,通过Visitor API读取一个class的内容,保存到另一个文件中去
static void copy(File inputFile, File outputFile) {
def weavedBytes = inputFile.bytes
ClassReader classReader = new ClassReader(bytes)
ClassWriter classWriter = new ClassWriter(classReader,
ClassWriter.COMPUTE_FRAMES | ClassWriter.COMPUTE_MAXS)
DoubleClickCheckModifyClassAdapter classAdapter = new DoubleClickCheckModifyClassAdapter(classWriter)
try {
classReader.accept(classAdapter, ClassReader.EXPAND_FRAMES)
weavedBytes = classWriter.toByteArray()
} catch (Exception e) {
println "Exception occurred when visit code \n " + e.printStackTrace()
}
outputFile.withOutputStream{
it.write(weavedBytes)
}
}
首先,我们通过ClassReader读取某个class文件,然后定义一个ClassWriter,这个ClassWriter其实就是一个ClassVisitor的实现,负责将ClassReader传递过来的数据写到一个字节流中,而真正触发这个逻辑就是通过ClassWriter的accept方式。
上面代码DoubleClickCheckModifyClassAdapter类,也是一个Visitor,也就是我们自定义需要实现的功能。
最后,我们通过ClassWriter的toByteArray(),将从ClassReader传递到ClassWriter的字节码导出,写入新的文件即可。这样我们就完成了字节码的操作,是不是感觉也不难。
ASM code
从上面的例子中,可以看出来,只有DoubleClickCheckModifyClassAdapter需要自己定义,其他的都由上面的模板来写就行,来看下这个类是怎么实现的。
public class DoubleClickCheckModifyClassAdapter extends ClassVisitor implements Opcodes {
public DoubleClickCheckModifyClassAdapter(ClassVisitor cv) {
super(Opcodes.ASM5, cv);
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor methodVisitor = cv.visitMethod(access, name, desc, signature, exceptions);
if ((ASMUtils.isPublic(access) && !ASMUtils.isStatic(access)) &&
name.equals("onClick") &&
desc.equals("(Landroid/view/View;)V")) {
methodVisitor = new View$OnClickMethodVisitor(methodVisitor);
}
return methodVisitor;
}
}
可以从上面的visitMethod方法中看到,我们只对View的onClick函数进行代码织入,然后再看下View$OnClickMethodVisitor的实现
public class View$OnClickMethodVisitor extends MethodVisitor {
private boolean weaved;
public View$OnClickMethodVisitor(MethodVisitor mv) {
super(Opcodes.ASM5, mv);
}
@Override
public void visitCode() {
super.visitCode();
if (weaved) return;
AnnotationVisitor annotationVisitor =
mv.visitAnnotation("L" + DoubleCheckConfig.checkClassAnnotation + ";", false);
annotationVisitor.visitEnd();
mv.visitMethodInsn(Opcodes.INVOKESTATIC, DoubleCheckConfig.checkClassPath, "isClickable", "()Z", false);
Label l1 = new Label();
mv.visitJumpInsn(Opcodes.IFNE, l1);
mv.visitInsn(Opcodes.RETURN);
mv.visitLabel(l1);
}
@Override
public AnnotationVisitor visitAnnotation(String desc, boolean visible) {
/*Lcom/smartdengg/clickdebounce/Debounced;*/
weaved = desc.equals("L" + DoubleCheckConfig.checkClassAnnotation + ";");
return super.visitAnnotation(desc, visible);
}
}
最主要的实现就是visitCode函数,这里面,我们实现了代码的织入。
我们设想一下,如果要对某个class进行修改,那需要对字节码具体做什么修改呢?最直观的方法就是,先编译生成目标class,然后看它的字节码和原来class的字节码有什么区别,但是这样还不够,其实我们最终并不是读取字节码,而是使用ASM来修改。
问题来了,我不懂ASM,对字节码更是很陌生,怎么办?难道我要从新学习一下字节码,才能进行开发吗?答案当然不是,如果我们只是对字节码做一些简单的操作,完全可以使用工具来帮我们完成
这里安利一个非常好用的工具,Intellij IDEA有个插件Asm Bytecode Outline,可以查看一个class文件的bytecode和ASM code,同样,Android Studio同样也有一个类似的插件ASM Bytecode Viewer实现了同样的功能。
如何编写ASM代码
这是我们源代码
public class A {
static void toast(Context context) {
Toast.makeText(context,"test",Toast.LENGTH_LONG).show();
}
}
我们想通过字节码插装后变为
public class A {
static void toast(Context context) {
Log.i("tag","test");
Toast.makeText(context,"test",Toast.LENGTH_LONG).show();
}
}
也就是在toast函数的第一行插入Log代码。
- 我们将要插入的代码先写入源代码中,在文件中右击鼠标.
- 点击ASM Bytecode Viewer
- 打开右侧的ASM预览界面,就能看到对应的ASM代码

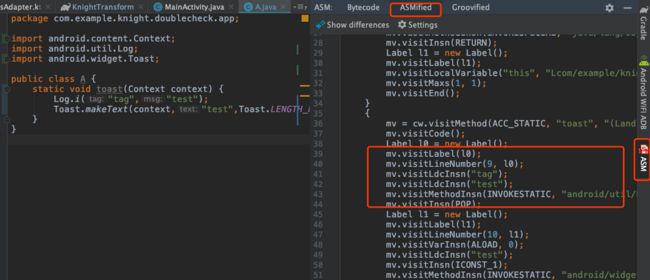
到此为止,貌似使用对比ASM code的方式,来实现字节码修改也不难,但是,这种方式只是可以实现一些修改字节码的基础场景,还有很多场景是需要对字节码有一些基础只是才能做到,而且,要阅读懂ASM code,也是需要一定字节码的知识。所以,如果要开发字节码工程,还是需要学习一番字节码的。
实际应用
Theory without practice is empty,practice without theory is blind
我们既然已经了解了ASM的原理,那么我们应用于实践,我们不能为了学技术而学技术,技术最终是要服务于业务的,我们更加应该从业务的角度出发,来思考问题和提升自己(题外话)。
有一个场景,在可点击的地方,经常出现连击,但是结果并不是我们想要的,例如,跳转到个人页面,我们快速点击两次,就会发现出现了两个个人页面,需要back两次才能回到之前的页面,这个肯定是不符合预期的,几乎在所有的点击地方,都应该做防抖动的操作(抖动,就是快速或者不小心在短时间内多次点击,我也不知道为什么叫抖动,网上都这样写),现在有几个思路:
- Kotlin中实现view的扩展函数,这样就可以统一的地方做防抖动操作,但是如果大家不是理解这个点,有可能还会调用之前的点击事件,那么还有可能出现这个问题。
- Java中封装一个工具类,要求每个开发人员在在OnClick中添加这个函数,但是这个很容易被遗忘,可操作性不大。
- 使用AOP(AspectJ和ASM),在编译期间,将所有的Onclick函数中做判断,而且ASM兼容Java和Kotlin。这里选择ASM,上一章节已经说明原因
从以上几点中,可以得出使用ASM是目前最好的方案。
参考文章
ASM 操作字节码初探
一起玩转Android项目中的字节码
一文读懂 AOP | 你想要的最全面 AOP 方法探讨