【HIVE篇】HIVE的使用
一、基本的表操作
1.创建表:
create table testTable(
id int,
name string,
likes array<string>,
address map<string,string>
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';表结构的定义为:根据不同的分隔符来对文本中的数据信息进行过滤和创建表。
formated:为按不同的规则切分行字符串。
2.导入数据:
load data local inpath '/root/hivedata01.txt' into table table01;比insert的方式快很多倍。备注:其中local 如果不加表示数据在hdfs上,加了则是在linux系统本地。注意:往表里放完后会在hdfs上放一份。hdfs上放的是原始的数据信息。
备注: hive是读时模式,对写的操作不做检查。给他啥就导入啥。读的时候检查。
而像关系型数据库,是写时候模式。写的时候会检查。
测试例:
11,zhangsan,daqiu-kanshu-kandingyi,beijing:tiananmeng-shanghai:pudong-shengzheng:huaqingbei,nan,33
12,xiaoming,pingshu-xiangsheng-moshu,beijing:jingnan-hebei:zhijiazhan-henan:zhengzhou,nv,243.查询数据:
select * from tablename;
上述的操作结果
hive> select * from table02;
OK
11 zhangsan ["daqiu","kanshu","kandingyi"] {"beijing":"tiananmeng","shanghai":"pudong","shengzheng":"huaqingbei"}
12 xiaoming ["pingshu","xiangsheng","moshu"] {"beijing":"jingnan","hebei":"zhijiazhan","henan":"zhengzhou"}4.从hdfs 上查询表数据:
hdfs dfs -cat /user/hive/warehouse/table02/*
备注1:查看表的属性信息 desc tablename;
查看表描述:desc formatted tablename;
5:其他的创建表的方式:
5.1 AS
CREATE TABLE table_new AS SELECT * from table_old;会转成MapReduce执行创建新表。
5.2 LIKE
CREATE TABLE table_new LIKE table_old;like的方式不会创建MapReduce的方式执行。
5.3 FROM
from chen
insert into table result select *;
// 把from 放前的原因是:select 后面可并列接各种方式的查询把结果都给result二、表类型
2.1 内部表和外部表:
区别在于内部表在固定的路径下,外部表需要自己定义位置而且加上关键字:EXTERNAL
eg:创建外部表
create EXTERNAL table externalTable(
id int,
name string,
likes array<string>,
address map<string,string>
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LOCATION '/externalTable';备注: 内部的表可以通过drop 的方式删除,同时删除元数据。对外部表而言,元数据被删除(通过hive 中 show tables查看是否删除;)。但是实际的数据却还在(hdfs上查看)。
2.2 分区表:
内部分区表、外部分区表
内部分区表:
create table inner_part_table(
id int,
name string,
likes array<string>,
address map<string,string>
)
PARTITIONED BY (sex string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';注意:分区字段必须是新的字段,不可以在原始的字段上作为分区字段。
分区在hdfs上体现在目录的增加。
新增分区:
ALTER TABLE inner_part_table ADD PARTITION(sex='unknown');往分区表上推送数据:
load data local inpath 'hivedata01.txt' into table inner_part_table PARTITION(sex='nv');对不同个数分区字段的分区表,设置上述的partitons的个数对应起来。
删除分区:
ALTER TABLE inner_part_table DROP PARTITION (sex='unknown')在删除分区的时候注意:如果某2个目录下有同样的一个分区目录,删除此同样的目录,会是的2个目录同时被删除。
三、Hive SerDe
既: Serializer and Deserializer
SerDe 用于做序列化和反序列化。构建在数据存储和执行引擎之间,对两者实现解耦。Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写。
举例 :
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;测试数据:
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -四、Hive Beeline
解释:
Beeline 要与HiveServer2配合使用
服务端启动hiveserver2
客户的通过beeline两种方式连接到hive
1、beeline -u jdbc:hive2://node03:10000/default -n root
2、beeline
beeline> !connect jdbc:hive2://:/;auth=noSasl root 123
默认 用户名、密码不验证
首先启动hiveserver2,进入到hive的bin下 ,启动hiveserver2文件。则开始服务。
然后,在客户端,beeline -u jdbc;hive2://node03:10000 root 启动beeline客户端。
五、Hive 函数
常用函数(完整版 密码:m8gy):
1.split(string str, string pat) 将字符串转换为数组。
2.explode(array a) 数组一条记录中有多个参数,将参数拆分,每个参数生成一列。
六、UDF 开发
1、UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容。
2、编写UDF函数的时候需要注意一下几点:
a)自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。
b)需要实现evaluate函数,evaluate函数支持重载。
3、步骤
a)把程序打包放到目标机器上去;
b)进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询HQL语句:
SELECT add_example(8, 9) FROM scores;
SELECT add_example(scores.math, scores.art) FROM scores;
SELECT add_example(6, 7, 8, 6.8) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
六、 UDAF 自定义聚集函数
多行进一行出,如sum()、min(),用在group by时
1.必须继承
org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)
org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类Evaluator实现UDAFEvaluator接口)
2.Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数
init():类似于构造函数,用于UDAF的初始化
iterate():接收传入的参数,并进行内部的轮转,返回boolean
terminatePartial():无参数,其为iterate函数轮转结束后,返回轮转数据,类似于hadoop的Combiner
merge():接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
terminate():返回最终的聚集函数结果开发一个功能同:
Oracle的wm_concat()函数
Mysql的group_concat()
六、UDTF 用户定义表生成函数
操作作用于单个数据行,并且产生多个数据行——-一个表作为输出
七、Hive参数设置
hive当中的参数、变量,都是以命名空间开头

通过${}方式进行引用,其中system、env下的变量必须以前缀开头
注:命令行的方式设置只在当前的会话内有效
hive 参数设置三种方式如下:
1、修改配置文件 ${HIVE_HOME}/conf/hive-site.xml (持久化)
2、启动hive cli时,通过–hiveconf key=value的方式进行设置 (临时)
例:
设置表 头:hive --hiveconf hive.cli.print.header=true
3、进入cli之后,通过使用set命令设置(临时)
备:可通过hive客户端下输入:set;来查看所有的设置选项。
- set设置:
set hive.cli.print.header=true;
- set查看
set hive.cli.print.header
- hive参数初始化配置
当前用户家目录下的.hiverc文件
如: ~/.hiverc
如果没有,可直接创建该文件,将需要设置的参数写到该文件中,hive启动运行时,会加载改文件中的配置。
- hive历史操作命令集
~/.hivehistory备:
1.这里有个提示,如果想查看所有操作的历史记录,可在家目录下查看:.hivehistory 文件。便可找到所有写过的sql了。
在hive CLI控制台可以通过set对hive中的参数进行查询、设置2.如果想持久化,则在家目录下设置一个隐藏文件:.hiverc 然后把设置的内容放入。举例,set hive.cli.print.header=true;
八、Hive 动态分区
说明:
所谓的动态分区,是在导入数据的时候,分区字段的值会分别分成不同的组。比如,性别有男和女,设置了动态分区后,就会自动分成sex=nan 和 sex nv 2个分区。从hdfs上看到有这2个目录的存在。
- 开启支持动态分区
》set hive.exec.dynamic.partition=true;
默认:false
》set hive.exec.dynamic.partition.mode=nostrict;
默认:strict(至少有一个分区列是静态分区)
相关参数
》set hive.exec.max.dynamic.partitions.pernode;
每一个执行mr节点上,允许创建的动态分区的最大数量(100)
》set hive.exec.max.dynamic.partitions;
所有执行mr节点上,允许创建的所有动态分区的最大数量(1000)
》set hive.exec.max.created.files;
所有的mr job允许创建的文件的最大数量(100000)举例:
数据源:
11,zhangsan,daqiu-kanshu-kandingyi,beijing:tiananmeng-shanghai:pudong-shengzheng:huaqingbei,nan,33
12,xiaoming,pingshu-xiangsheng-moshu,beijing:jingnan-hebei:zhijiazhan-henan:zhengzhou,nv,24
13,xiaoming,pingshu-xiangsheng-moshu,beijing:jingnan-hebei:zhijiazhan-henan:zhengzhou,nan,33
12,xiaoming,pingshu-xiangsheng-moshu,beijing:jingnan-hebei:zhijiazhan-henan:zhengzhou,nv,24 create table table01(
id int,
nam string,
likes array<string>,
address map<string,string>,
sex string,
age int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'; create table table02(
id int,
nam string,
likes array<string>,
address map<string,string>
)PARTITIONED BY (SEX STRING,AGE INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'; from table01
insert overwrite table table02 partition(sex, age) select id,name,likes,address,sex,age distribute by sex,age;结果:table02为:
psn21.id psn21.name psn21.likes psn21.address psn21.sex psn21.age
11 zhangsan ["daqiu","kanshu","kandingyi"] {"beijing":"tiananmeng","shanghai":"pudong","shengzheng":"huaqingbei"} nan 33
12 xiaoming ["pingshu","xiangsheng","moshu"] {"beijing":"jingnan","hebei":"zhijiazhan","henan":"zhengzhou"} nv 24
13 xiaoming ["pingshu","xiangsheng","moshu"] {"beijing":"jingnan","hebei":"zhijiazhan","henan":"zhengzhou"} nan 33
12 xiaoming ["pingshu","xiangsheng","moshu"] {"beijing":"jingnan","hebei":"zhijiazhan","henan":"zhengzhou"} nv 24运行后通过MapReduce处理,最后在hdfs上查看最后的结果。
九、分桶
分区是目录,而分桶是文件。
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。
对于hive中每一个表、分区都可以进一步进行分桶。
由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
适用场景:
数据抽样( sampling )、map-join
开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数。(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和reduce task个数一致。往分桶表中加载数据
insert into table bucket_table select columns from tbl;
insert overwrite table bucket_table select columns from tbl;举例:
数据源:
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88普通表,用来存测试数据源:
CREATE TABLE test_table( id INT, name STRING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';创建分桶表:(设置4个分桶)
CREATE TABLE psnbucket( id INT, name STRING, age INT) CLUSTERED BY (age) INTO 4 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';加载数据:
insert into table psnbucket select id, name, age from test_table;通过mapreduce的方式执行完,检测hdfs上是否有4个分桶文件。
十、Lateral View
Lateral View用于和UDTF函数(explode、split)结合来使用。
首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。
主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题
语法:
LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)举例:
统计爱好和地址。
select count(distinct(myColl)),count(distinct(myCol2)) from inner_part_table lateral view explode(likes) myTable1 as myColl lateral view explode(address) myTable2 as myCol2,myCol3;如果直接用explode函数去合并求出2个字段的和,explode语法不允许,需要把它们执行的结果作为虚拟表来操作。
十、hive View视图
和关系型数据库中的普通视图一样,hive也支持视图
特点:
1.不支持物化视图(物化视图:直接插入数据)
2.只能查询,不能做加载数据操作
3.视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询
4.view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,view当中定义的优先级更高
5.view支持迭代视图
十一、Hive 索引
目的:优化查询以及检索性能
创建索引:
create index t1_index on table psn2(name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table t1_index_table;
as:指定索引器;
in table:指定索引表,若不指定默认生成在default__psn2_t1_index__表中
create index t1_index on table psn2(name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;举例:
1.创建
create index cxx_index on table cxx(id) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table cxx_cxx_table;2.构建
ALTER INDEX cxx_index ON cxx REBUILD;备:
如果不构建,生成的是个空的索引表。
如果要删除分区 使用
DROP INDEX IF EXISTS cxx_index ON cxx;十二、Hive运行方式
- 1.命令行方式cli:控制台模式
- 2.脚本运行方式(实际生产环境中用最多)
- 3.JDBC方式:hiveserver2
- 4.web GUI接口 (hwi、hue等) [hwi:hive 自带的工具 hue:企业级工具]
1.Hive在CLI模式中
与hdfs交互
执行执行dfs命令
例:dfs –ls /
与Linux交互
!开头
例: !pwd
说明:客户端下操作hdfs 使用:dfs XXXXXXXX 比如:dfs -ls /
执行的速度会比linux下直接操作hdfs快。它省去了连接的时间。
如果想在hive客户端下直接操作linux的命令,前需要加:! 结果需要:”;”
Hive脚本运行方式:
hive -e "Hql"
hive -e "">aaa //输出重定向到某个文件里
hive -S -e "">aaa // 静默输出,屏蔽了部分信息
hive -f file
hive -i /home/my/hive-init.sql //较-f 打印信息少,并进入hive客户端
hive> source file (在hive cli中运行)Hive Web GUI接口
web界面安装:
- 下载源码包apache-hive-*-src.tar.gz - 将hwi war包放在$HIVE_HOME/lib/ - 制作方法:将hwi/web/*里面所有的文件打成war包 1.cd apache-hive-1.2.1-src/hwi/web
2.jar -cvf hive-hwi.war *
3.复制tools.jar(在jdk的lib目录下)到$HIVE_HOME/lib下
4.修改hive-site.xml
5.启动hwi服务(端口号9999)
hive --service hwi
6.浏览器通过以下链接来访问
http://node3:9999/hwi/十三、Hive 权限管理
限制:
1、启用当前认证方式之后,dfs, add, delete, compile, and reset等命令被禁用。
2、通过set命令设置hive configuration的方式被限制某些用户使用。
(可通过修改配置文件hive-site.xml中hive.security.authorization.sqlstd.confwhitelist进行配置)
3、添加、删除函数以及宏的操作,仅为具有admin的用户开放。
4、用户自定义函数(开放支持永久的自定义函数),可通过具有admin角色的用户创建,其他用户都可以使用。
5、Transform功能被禁用。配置:
Hive - SQL Standards Based Authorization in HiveServer2
在hive服务端修改配置文件hive-site.xml添加以下配置内容:
hive.security.authorization.enabled
true
hive.server2.enable.doAs
false
hive.users.in.admin.role
root
hive.security.authorization.manager
org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory
hive.security.authenticator.manager
org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator
服务端启动hiveserver2;客户端通过beeline进行连接常用操作:
Hive权限管理
角色的添加、删除、查看、设置:
CREATE ROLE role_name; -- 创建角色
DROP ROLE role_name; -- 删除角色
SET ROLE (role_name|ALL|NONE); -- 设置角色
SHOW CURRENT ROLES; -- 查看当前具有的角色
SHOW ROLES; -- 查看所有存在的角色Hive权限管理:
- 角色的授予、移除、查看
将角色授予某个用户、角色:
GRANT role_name [, role_name] ...
TO principal_specification [, principal_specification] ...
[ WITH ADMIN OPTION ];
principal_specification
: USER user
| ROLE role- 移除某个用户、角色的角色:
REVOKE [ADMIN OPTION FOR] role_name [, role_name] ...
FROM principal_specification [, principal_specification] ... ;
principal_specification
: USER user
| ROLE role- 查看授予某个用户、角色的角色列表
SHOW ROLE GRANT (USER|ROLE) principal_name;- 查看属于某种角色的用户、角色列表
SHOW PRINCIPALS role_name;- 权限的授予:
SELECT privilege – gives read access to an object. INSERT privilege – gives ability to add data to an object (table). UPDATE privilege – gives ability to run update queries on an object (table). DELETE privilege – gives ability to delete data in an object (table). ALL PRIVILEGES – gives all privileges (gets translated into all the above privileges).- 权限的授予、移除、查看
将权限授予某个用户、角色:
GRANT
priv_type [, priv_type ] ...
ON table_or_view_name
TO principal_specification [, principal_specification] ...
[WITH GRANT OPTION];- 移除某个用户、角色的权限:
REVOKE [GRANT OPTION FOR]
priv_type [, priv_type ] ...
ON table_or_view_name
FROM principal_specification [, principal_specification] ... ;- 查看某个用户、角色的权限:
SHOW GRANT [principal_name] ON (ALL| ([TABLE] table_or_view_name)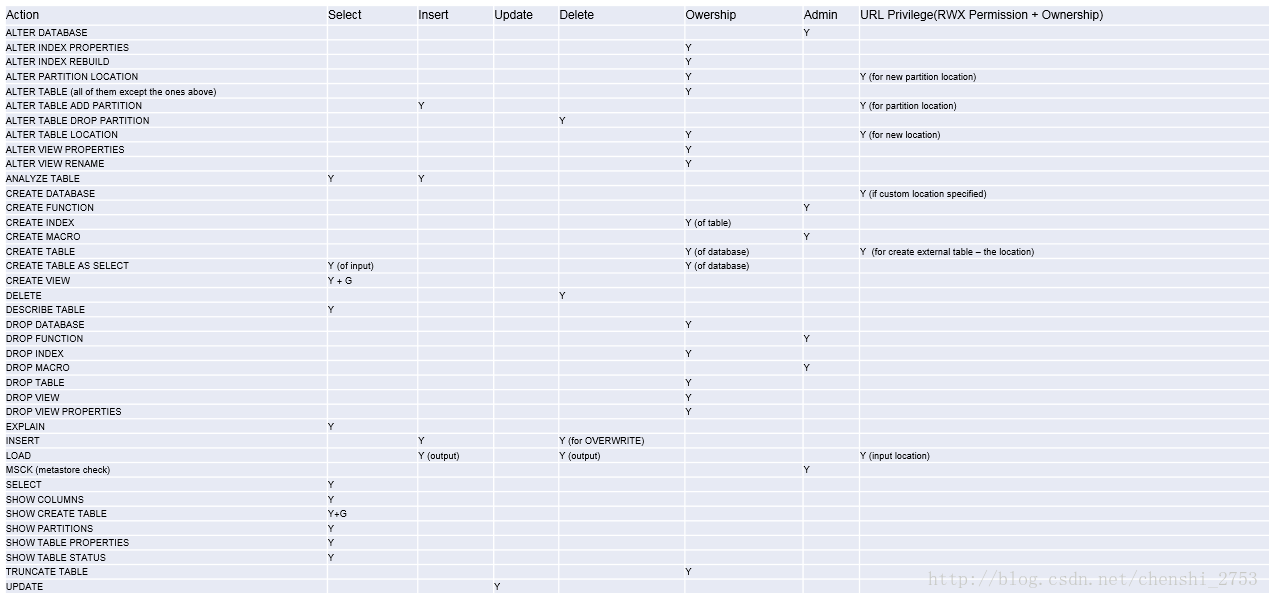
Y: Privilege required.
Y + G: Privilege “WITH GRANT OPTION” required.
十四、Hive 优化
核心思想:
把Hive SQL 当做Mapreduce程序去优化
以下SQL不会转为Mapreduce来执行
1.select仅查询本表字段
2.where仅对本表字段做条件过滤
Explain 显示执行计划
EXPLAIN [EXTENDED] query
Hive运行方式:
本地模式
集群模式
本地模式
开启本地模式:
set hive.exec.mode.local.auto=true;注意:
hive.exec.mode.local.auto.inputbytes.max默认值为128M
表示加载文件的最大值,若大于该配置仍会以集群方式来运行!
并行计算:
通过设置以下参数开启并行模式:
set hive.exec.parallel=true;
注意:hive.exec.parallel.thread.number
(一次SQL计算中允许并行执行的job个数的最大值)
严格模式
通过设置以下参数开启严格模式:
set hive.mapred.mode=strict;
(默认为:nonstrict非严格模式)
查询限制:
1、对于分区表,必须添加where对于分区字段的条件过滤;
2、order by语句必须包含limit输出限制;
3、限制执行笛卡尔积的查询。
Hive排序
Order By - 对于查询结果做全排序,只允许有一个reduce处理
(当数据量较大时,应慎用。严格模式下,必须结合limit来使用)Sort By - 对于单个reduce的数据进行排序
Distribute By - 分区排序,经常和Sort By结合使用
Cluster By - 相当于 Sort By + Distribute By
(Cluster By不能通过asc、desc的方式指定排序规则;
可通过 distribute by column sort by column asc|desc 的方式)
Hive Join
Join计算时,将小表(驱动表)放在join的左边
Map Join:在Map端完成Join
两种实现方式:- 1、SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)
语法:
SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;- 2、开启自动的MapJoin
自动的mapjoin
通过修改以下配置启用自动的mapjoin:
set hive.auto.convert.join = true;(该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join)
相关配置参数:
- hive.mapjoin.smalltable.filesize;
(大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行) - hive.ignore.mapjoin.hint;
(默认值:true;是否忽略mapjoin hint 即mapjoin标记) - hive.auto.convert.join.noconditionaltask;
(默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin) - hive.auto.convert.join.noconditionaltask.size;
(将多个mapjoin转化为一个mapjoin时,其表的最大值)
Map-Side聚合
通过设置以下参数开启在Map端的聚合
set hive.map.aggr=true;相关配置参数:
- hive.groupby.mapaggr.checkinterval:
map端group by执行聚合时处理的多少行数据(默认:100000) - hive.map.aggr.hash.min.reduction:
进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合) - hive.map.aggr.hash.percentmemory:
map端聚合使用的内存的最大值 - hive.map.aggr.hash.force.flush.memory.threshold:
map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush - hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false
控制Hive中Map以及Reduce的数量
Map数量相关的参数
mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值
mapred.min.split.size.per.node
一个节点上split的最小值
mapred.min.split.size.per.rack
一个机架上split的最小值Reduce数量相关的参数
mapred.reduce.tasks
强制指定reduce任务的数量
hive.exec.reducers.bytes.per.reducer
每个reduce任务处理的数据量
hive.exec.reducers.max
每个任务最大的reduce数
Hive - JVM重用
适用场景:
1、小文件个数过多
2、task个数过多
通过 set mapred.job.reuse.jvm.num.tasks=n; 来设置
(n为task插槽个数)
缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源!