java性能调优
最近生产上项目总是在运行2天左右就会内存撑满,导致服务down调。需要人为的频繁重启。分析了一下原因:
1.应用层面:
首先检查代码,是否存在编码不标准导致内存溢出:如IO流的关闭,是否重复申请大对象等。
(1)代码可读性差,无基本编程规范;
(2)对象生成过多或生成大对象,内存泄露等;
(3)IO 流操作过多,或者忘记关闭;
(4)数据库操作过多,事务过长;
(5)同步使用的场景错误;
(6)循环迭代耗时操作等。
经粗略检查,显示的编码似乎并没有问题
2.数据库层面:
数据库层面应该不会导致内存撑满的现象。当然数据库在优化服务性能上也是非常重要的一点,如优化sql,事物,索引等。
通常来说,对于数据库层的调优我们基本上会从以下几个方面出发:
(1)在 SQL 语句层面进行优化:慢 SQL 分析、索引分析和调优、事务拆分等;
(2)在数据库配置层面进行优化:比如字段设计、调整缓存大小、磁盘 I/O 等数据库参数优化、数据碎片整理等;
(3)从数据库结构层面进行优化:考虑数据库的垂直拆分和水平拆分等;
(4)选择合适的数据库引擎或者类型适应不同场景,比如考虑引入 NoSQL 等。
3.框架层面:
这个层面的优化一般比较难,涉及到的架构的问题,应该在框架搭建时就应该考虑到性能问题。比如:
引入一些新的计算或者存储框架,利用新特性解决原有集群计算性能瓶颈等;或者引入分布式策略,在计算和存储进行水平化,包括提前计算预处理等,利用典型的空间换时间的做法等;都可以在一定程度上降低系统负载;
3.JVM层面:
所谓的JVM 调优一般就是利用JVM 提供的一些工具分析内存的占用及垃圾回收GC情况,常用的工具如jps,jstat,jmap,jconsole.
所以我们利用这几个工具对生产上的问题现场进行了保存:
jstat -gc 5157 250 10 //对java进程5157 查询GC 情况,没250秒一次,输出10次。
jmap 5157 //某个java进程(使用pid)内存内的所有‘对象’的情况(如:产生哪些对象,及其数量)
jmap -histo 5157|more
jmap -dump:format.b.file=/home/dump.bin 5157 //输出dump文件,即进程的内存内的所有对象情况。
jhat -port 999 /home/dump.bin //将dump文件加载到内存;
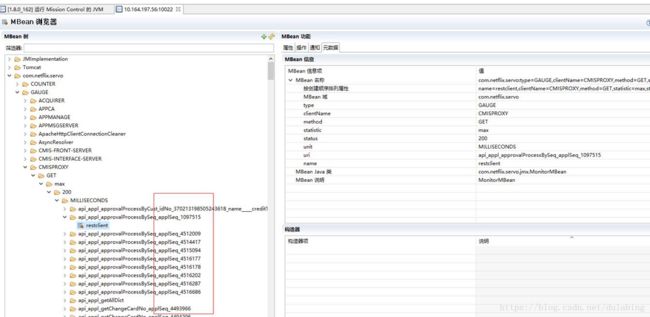
然后在浏览器内输入:服务器地址:9999 可查看到内存内的对象情况。结果发现:
我们这两天进行了分析,发现了一个spring cloud的问题,针对spring cloud的metric数据统计,我们对restTemplate使用方式违反了spring cloud内部的使用约定(也算是spring cloud的一个bug),导致统计异常,堆占用不断增加,具体可见下文:
https://github.com/spring-cloud/spring-cloud-netflix/issues/947
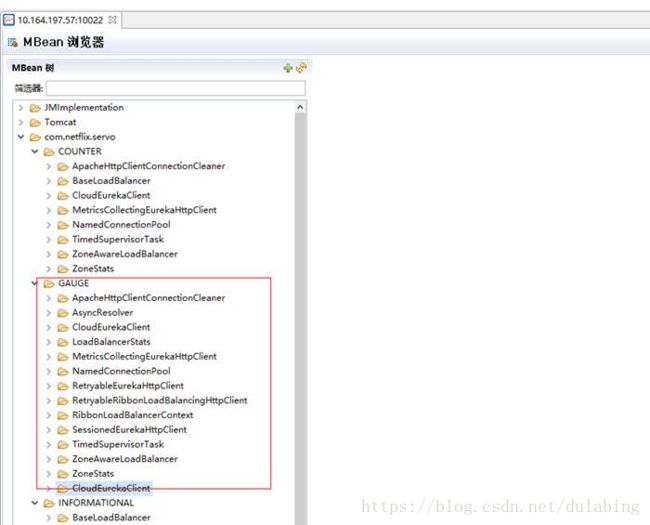
针对这个问题,我们目前无法修改我们的使用方式,只能禁用spring cloud的servo metric统计功能,配置如下:
spring:
autoconfigure.exclude: org.springframework.cloud.netflix.metrics.servo.ServoMetricsAutoConfiguration
metrics.servo.enabled: false
cloud.netflix.metrics.enabled: false
将以上三个配置添加到各自的配置文件中,实现对servo统计的禁用。
具体效果对比如下:
这个层面的优化一般比较难,涉及到的架构的问题,应该在框架搭建时就应该考虑到性能问题。比如:
标准的restTemplate使用方式可参考下面的文章:
http://blog.csdn.net/u012702547/article/details/77917939