微服务学习记录--入门
微服务前面零散地进行了一些框架和概念层面的学习,现在是开始相对完整地开始课程学习,极客时间上买的课程,听和学的过程做一些摘要和笔记。
一、服务描述
服务调用首先要解决的问题就是服务如何对外描述。比如服务名、调用这个服务需要提供哪些信息、返回的结果是什么格式的、如何解析等问题。常用的服务描述方式包括 RESTful API、XML 配置以及 IDL 文件三种。
服务描述方式 使用场景 缺点
RESTFUL API 跨语言平台,组织内外皆可 使用了HTP作为通信协议,相比TCP协议,性能较差
XML配置 Java平台,一般用作组织内部 不支持跨语言平台
IDL文件 跨语言平台,组织内外皆可 修改或者除PB字段不能向前兼容
二、注册中心
有了服务的接口描述,下一步要解决的问题就是服务的发布和订阅,就是说你提供了一个服务,如何让外部想调用你的服务的人知道。这个时候就需要一个类似注册中心的角色,服务提供者将自己提供的服务以及地址登记到注册中心,服务消费者则从注册中心查询所需要调用的服务的地址,然后发起请求。
注册中心的工作流程:
- 服务提供者在启动时,根据服务发布文件中配置的发布信息向注册中心注册自己的服务。
- 服务消费者在启动时,根据消费者配置文件中配置的服务信息向注册中心订阅自己所需要的服务。
- 注册中心返回服务提供者地址列表给服务消费者。
- 当服务提供者发生变化,比如有节点新增或者销毁,注册中心将变更通知给服务消费者。
三、服务框架(通信框架)
- 客户端和服务端的网络连接(服务通信协议):就是说服务提供者和服务消费者之间以什么样的协议进行网络通信,是采用四层 TCP、UDP 协议,还是采用七层 HTTP 协议,还是采用其他协议。常用的有HTTP连接或SOCKET连接。
- 数据传输方式:就是说服务提供者和服务消费者之间的数据传输采用哪种方式,是同步还是异步,是在单连接上传输,还是多路复用。例如Http协议,或私有的Dubbo协议。
- 数据压缩格式:通常数据传输都会对数据进行压缩,来减少网络传输的数据量,从而减少带宽消耗和网络传输时间,比如常见的 JSON 序列化、Java 对象序列化以及 Protobuf 序列化等。
四、监控微服务
1)监控的对象
监控的对象可以分为四个层次,从上到下可以归纳为:
- 用户端监控:通常指业务直接对用户提供的功能的监控。
- 接口监控:通常指业务提供的功能所依赖的具体RPC接口的监控。
- 资源的监控:通常指某个接口依赖的资源的监控。比如对redis的监控就是属于资源监控。
- 基础监控:通常指对服务器本身的健康状况的监控。cpu,I/O读写,带宽等。
2)监控指标:
- 请求量。请求量分为两个维度,一个是实时请求量QPS( Queries Per Second),一个是统计请求量PV(Page View)。
- 响应时间。大多数情况下,可以用一段时间内所有调用的平均时耗来反映请求的响应时间。
- 错误率。一段时间内调用的失败次数占调用的总次数的比率来衡量。
3)监控维度:
- 全局维度。从整体角度监控对象的请求量、平均耗时以及错误率,全局维度的监控一般是为了让你对监控的对象的调用情况有个整体的了解。
- 分机房维度。一般是为了业务的高可用性,服务通常部署在不止一个机房,需分机房分别监控。
- 单机维度。不同机器的同一监控对象的各种指标也会有差异。
- 时间维度。不同时间段业务分布
- 核心维度。核心业务和非核心业务两者分开监控。
4)监控系统原理:
我们对服务调用进行监控,首先要能收集到每一次调用的详细信息,包括调用的响应时间,调用是否成功,调用的发起者和接受者分别是谁,这个过程叫做数据收集。采集到数据后,要把数据通过一定的方式传输给数据处理中心进行处理,这个过程叫做数据传输。数据传输过来后,数据处理中心再按照服务的维度进行聚合,计算出不同服务的请求量,响应时间以及错误率等信息并存储起来,这个过程叫做数据处理。最后再通过接口或者Dashboard的形式对外展示服务的调用情况,这个过程叫做数据展示。
可见,监控系统主要包括四个环节:数据采集,数据传输,数据处理和数据展示。
a.数据采集
- 服务主动上报,这种处理方式通过在业务代码或者服务框架里加入数据收集代码逻辑,在每一次服务调用完成后,主动上报服务的调用信息。
- 代理收集,这种处理方式通过服务调用后把调用的详细信息记录到本地日志文件后,然后再通过代理去解析本地日志文件,然后再上报服务的调用信息。
b.数据传输
最常用的方式:
- UDP传输,这种处理方式是数据处理单元提供服务器的请求地址,数据采集后通过UDP协议与服务器建立连接,然后把数据发送出去。
- Kafka传输,这种处理方式是数据采集后发送到指定的Topic,然后数据处理单元再订阅对应的Topic,就可以从Kafka消息队列中读取到对应的数据。
数据的格式:
- 二进制协议:最常用的就是PB对象,它的优点是高压缩比和高性能,可以减少传输带宽并且序列化和反序列化效率特别高。
- 文本协议,最常用的就是json字符串,它的优点是可读性好,但相比于PB对象,传输占用带宽高,并且解析性能也要差一些。
c.数据处理
数据处理是对采集的数据进行聚合并存储。数据聚合通常有两个维度:
- 接口维度聚合,这个维度是把实时收到的数据按照接口名维度实时聚合在一起,这样就可以得到每个接口的实时请求量,平均耗时等。
- 机器维度聚合,这个维度是 把实时收到的数据按照调用的节点维度聚合在一起,这样就可以从单机维度去查看每个接口的实时请求量,平均耗时等信息。
聚合后的数据需要持久化到数据库中存储,所选用的数据库一般分为两种:
- 索引数据库,比如Elasticsearch,以到排索引的数据结构存储,需要查询的时候,根据索引来查询。
- 时序数据库,比如OpenTSDB,以时序序列数据的方式存储,查询的时候按照时序如1min,5min等维度来查询。
d.数据展示
曲线图,饼状图,格子图等
五、如何追踪微服务调用
1)服务追踪的作用
第一,优化系统瓶颈。
第二,优化链路调用。
第三,生成网络拓扑。
第四,透明传输数据。
2)服务追踪系统原理
它的核心理念就是调用链:通过一个全局唯一的 ID 将分布在各个服务节点上的同一次请求串联起来,从而还原原有的调用关系,可以追踪系统问题、分析调用数据并统计各种系统指标。

traceId 是用于串联某一次请求在系统中经过的所有路径,spanId 是用于区分系统不同服务之间调用的先后关系,而 annotation 是用于业务自定义一些自己感兴趣的数据,在上传 traceId 和 spanId 这些基本信息之外,添加一些自己感兴趣的信息。
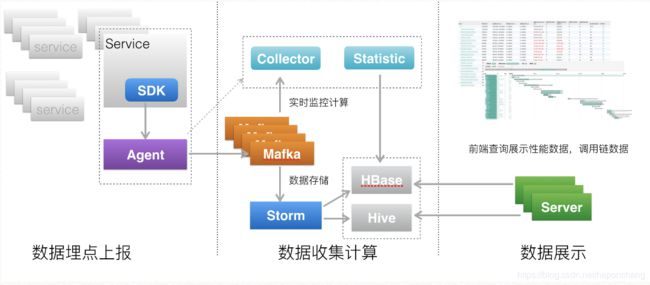
服务追踪系统架构图,可以分为三层。
- 数据采集层,负责数据埋点并上报。
- 数据处理层,负责数据的存储与计算。
- 数据展示层,负责数据的图形化展示。
六、微服务治理(维护和管理)
单体应用改造为微服务架构后,服务调用由本地调用变成远程调用,服务消费者 A 需要通过注册中心去查询服务提供者 B 的地址,然后发起调用,一次服务调用,服务提供者、注册中心、网络这三者都可能会有问题,此时服务消费者应该如何处理才能确保调用成功呢?这就是服务治理要解决的问题。
1)节点管理
两种节点管理手段。1. 注册中心主动摘除机制 2. 服务消费者摘除机制(将存活探测机制用在服务消费者这一端更合理,如果服务消费者调用服务提供者节点失败,就将这个节点从内存中保存的可用服务提供者节点列表中移除。)
2)负载均衡
常用的负载均衡算法主要包括以下几种。1. 随机算法;2 轮询算法 3. 最少活跃调用算法 4. 一致性 Hash 算法
如果后端服务节点的配置没有差异,同等调用量下性能也没有差异的话,选择随机或者轮询算法比较合适;如果后端服务节点存在比较明显的配置和性能差异,选择最少活跃调用算法比较合适。
3)服务路由
需要制定路由规则主要有两个原因:1. 业务存在灰度发布的需求 2. 多机房就近访问的需求
一般有两种配置方式。1. 静态配置 服务消费者本地存放服务调用的路由规则,在服务调用期间,路由规则不会发生改变,
2. 动态配置 这种方式下,路由规则是存在注册中心的,服务消费者定期去请求注册中心来保持同步
4)服务容错
服务调用并不总是一定成功的,对于服务调用失败的情况,需要有手段自动恢复,来保证调用成功。
常用的手段主要有以下几种。
FailOver 失败自动切换。失败后自动选择服务列表中下一个继续。一般适合服务调用是读请求的场景
FailBack 失败通知。就是服务消费者调用失败或者超时后,不再重试,而是根据失败的详细信息,来决定后续的执行策略。比如对于非幂等的调用场景,如果调用失败后,不能简单地重试,而是应该查询服务端的状态,看调用到底是否实际生效,如果已经生效了就不能再重试了;如果没有生效可以再发起一次调用。
FailCache 失败缓存。就是服务消费者调用失败或者超时后,不立即发起重试,而是隔一段时间后再次尝试发起调用。比如后端服务可能一段时间内都有问题,如果立即发起重试,可能会加剧问题,反而不利于后端服务的恢复。如果隔一段时间待后端节点恢复后,再次发起调用效果会更好。
FailFast 快速失败。就是服务消费者调用一次失败后,不再重试。实际在业务执行时,一般非核心业务的调用,会采用快速失败策略,调用失败后一般就记录下失败日志就返回了。
服务容错不同策略的使用场景是不同的,一般情况下对于幂等的调用(我理解为读操作),可以选择 FailOver 或者 FailCache,非幂等的调用(我理解为写操作)可以选择 FailBack 或者 FailFast。
七、小结和实例:Dubbo框架里的微服务组件
微服务的架构主要包括服务描述、服务发现、服务调用、服务监控、服务追踪以及服务治理这几个基本组件。
1)服务发布与引用:服务发布与引用的三种常用方式:RESTful API、XML 配置以及 IDL 文件,其中 Dubbo 框架主要是使用 XML 配置方式。
其中“dubbo:service”开头的配置项声明了服务提供者要发布的接口,“dubbo:protocol”开头的配置项声明了服务提供者要发布的接口的协议以及端口号。
其中“dubbo:reference”开头的配置项声明了服务消费者要引用的服务
2)服务注册与发现:
“dubbo://registry”开头的配置项声明了注册中心的地址
服务消费者发现服务的过程,其中“dubbo://registry”开头的配置项声明了注册中心的地址
3)服务调用
基于扩展点自适应机制,客户端和服务端之间的调用会通过 Netty 4 框架来建立连接,并且服务端采用 NIO 方式来处理客户端的请求。
Dubbo 的数据传输采用协议:Dubbo 不仅支持私有的 Dubbo 协议,还支持其他协议比如 Hessian、RMI、HTTP、Web Service、Thrift 等。
至于数据序列化和反序列方面,Dubbo 同样也支持多种序列化格式,比如 Dubbo、Hession 2.0、JSON、Java、Kryo 以及 FST 等,可以通过在 XML 配置中添加下面的配置项。
4)服务监控
服务监控主要包括四个流程:数据采集、数据传输、数据处理和数据展示,其中服务框架的作用是进行埋点数据采集,然后上报给监控系统。
在 Dubbo 框架中,无论是服务提供者还是服务消费者,在执行服务调用的时候,都会经过 Filter 调用链拦截,来完成一些特定功能,比如监控数据埋点就是通过在 Filter 调用链上装备了 MonitoFilter 来实现的。
5)服务治理
服务治理手段包括节点管理、负载均衡、服务路由、服务容错等,下面这张图给出了 Dubbo 框架服务治理的具体实现。
微服务架构各个组件是如何串联起来组成一个完整的微服务框架的,以 Dubbo 框架下一次服务调用的过程为例,先来看下客户端发起调用的过程。
首先根据接口定义,通过 Proxy 层封装好的透明化接口代理,发起调用。
然后在通过 Registry 层封装好的服务发现功能,获取所有可用的服务提供者节点列表。
再根据 Cluster 层的负载均衡算法从可用的服务节点列表中选取一个节点发起服务调用,如果调用失败,根据 Cluster 层提供的服务容错手段进行处理。
同时通过 Filter 层拦截调用,实现客户端的监控统计。
最后在 Protocol 层,封装成 Dubbo RPC 请求,发给服务端节点。
这样的话,客户端的请求就从一个本地调用转化成一个远程 RPC 调用,经过服务调用框架的处理,通过网络传输到达服务端。其中服务调用框架包括通信协框架 Transporter、通信协议 Codec、序列化 Serialization 三层处理。
服务端从网络中接收到请求后的处理过程是这样的:
首先在 Protocol 层,把网络上的请求解析成 Dubbo RPC 请求。
然后通过 Filter 拦截调用,实现服务端的监控统计。
最后通过 Proxy 层的处理,把 Dubbo RPC 请求转化为接口的具体实现,执行调用。