python绘图与可视化--matplotlib
主要用来记录《利用python进行数据分析》一书第8章 绘图与可视化
matplotlib绘图
1. 加载模块:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
在jupyter notebook中,若不使用魔法函数“%matplotlib inline”,需要适用plt.show()使绘图显示出来。
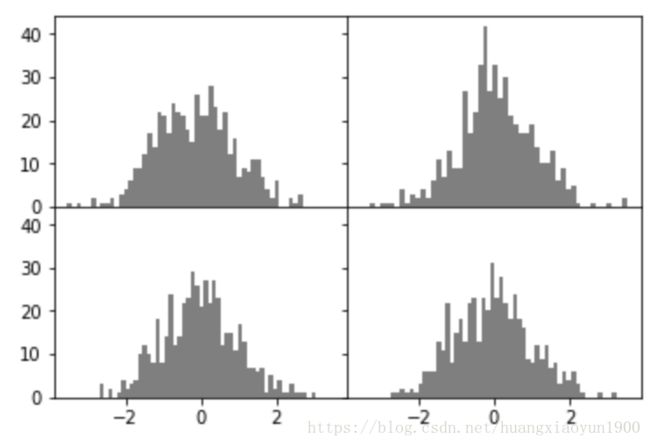
2. 绘制子图
# plt.subplots(nrows,ncols,sharex=False,sharey=False)
# 图表可分为几行几列的图形,是否共享X轴/Y轴(便于同比例尺下对比)
fig, axes = plt.subplots(2,2,sharex=True, sharey=True)
for i in range(2):
for j in range(2):
axes[i,j].hist(np.random.randn(500),bins=50,color="k",alpha=0.5)
# subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None)
# 子图的在大图中的位置,前四个为子图到大图边界的距离,wspace/hspace表示子图间列间距和行间距
plt.subplots_adjust(wspace=0,hspace=0)
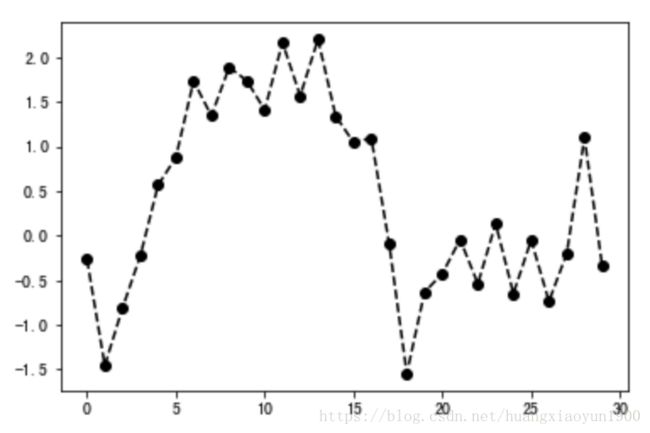
3. 颜色、标记、线型
根据x, y绘制绿色虚线'g--'
ax.plot(x, y, 'g--')
ax.plot(x, y, color='g', linestyle='--')
# 'ko--'绘制黑色带实心圆mark的虚线图
plt.plot(np.random.randn(30).cumsum(),'ko--')
# 等效的:
plt.plot(np.random.randn(30).cumsum(),color='k',linestyle='dashed',marker='o')
4. 刻度、标签、图例
set_xticks 设置x轴刻度标签位置
set_xticklabels 设置x轴刻度标签
set_title 设置标题
set_xlabel 设置x轴名称
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
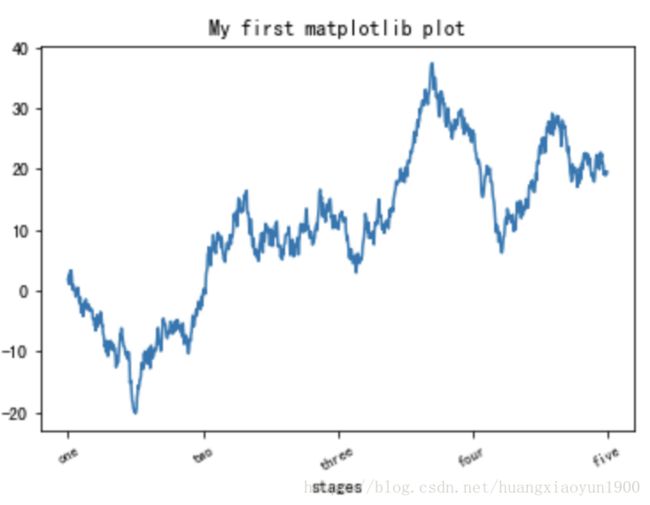
ax.plot(np.random.randn(1000).cumsum())
# 要修改X轴的刻度,使用set_xticks设置刻度标签位置和set_xticklabels设置刻度标签
ticks = ax.set_xticks([0,250,500,750,1000])
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation=30, fontsize='small')
# set_title设置标题,set_xlabel设置X轴名称
ax.set_title('My first matplotlib plot')
ax.set_xlabel('stages')
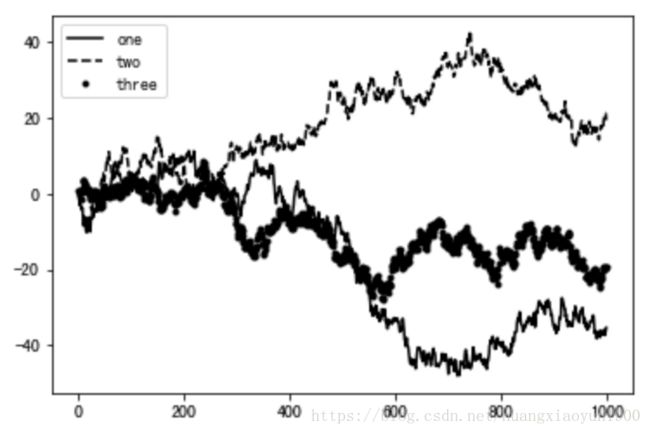
添加图例legend:
绘图时添加label, 再在plt.legend() 创建图例
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
# 绘图时,添加label
ax.plot(np.random.randn(1000).cumsum(),'k',label='one')
ax.plot(np.random.randn(1000).cumsum(),'k--',label='two')
ax.plot(np.random.randn(1000).cumsum(),'k.',label='three')
# 通过ax.legend() 或 plt.legend() 自动创建图例
ax.legend(loc='best')
5. 保存图表
保存图表 plt.savefig('foo.png') 文件类型可以由扩展名定义,可选项:dpi 分辨率(每英寸点数),bbox_inches 可以减除当前图表的空白部分(tight表示留有最小白边)
plt.savefig('figname.png', dpi=400, bbox_inches='tight')
Pandas绘图
在matplotlib中绘制一张图需要组装各种基础组件(图表、图例、标题、刻度标签以及其他注解),在pandas中只需要一两行代码就能完成。
1. 线型图
在pd.Series()和pd.DataFrame()中设置index(索引),columns(列名)等
data.plot中设置label(图例的标签),kind(可以是'line','bar','barh','kde','box'等图表形式)等等P246中的关键字参数会被传给相应的matplotlib绘图函数。
# 调整图片大小
matplotlib.rcParams['figure.figsize']=(9,6)
import pandas as pd
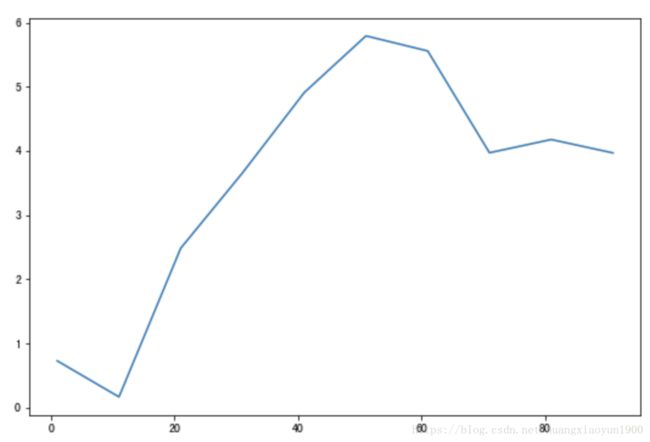
# Series.plot
s = pd.Series(np.random.randn(10).cumsum(),index=np.arange(1,100,10))
s.plot()
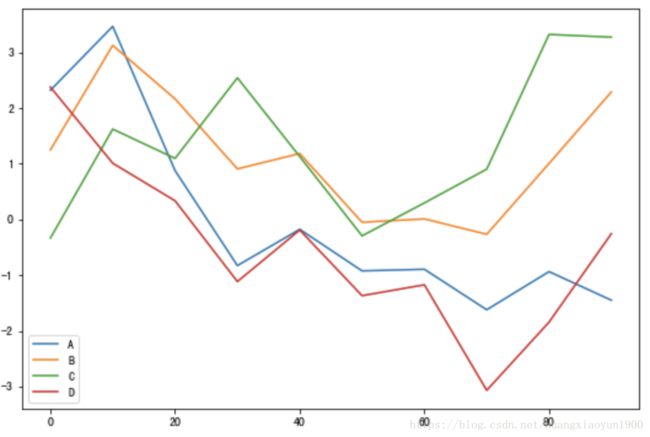
# DataFrame.plot
df = pd.DataFrame(np.random.randn(10,4).cumsum(0),
columns=['A','B','C','D'],
index=np.arange(0,100,10))
df.plot()
2. 柱状图
kind = 'bar'(垂直柱状图), kind = 'barh'(水平柱状图)
fig, axes = plt.subplots(2,1)
data=pd.Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(kind='bar',ax=axes[0],color='k',alpha=0.7)
data.plot(kind='barh',ax=axes[1],color='k',alpha=0.7)
df = pd.DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],
columns=pd.Index(['A','B','C','D'],name='Genus'))
df.plot(kind='bar')
DataFrame中列名的名字“Genus”可作为图例的名称显示出来
若在df.plot(kind='bar', stacked=True) 添加stacked=True,可绘制堆积柱状图
堆叠图:各行规格化和为1后,再比较堆叠项
tips = pd.read_csv('tips.csv')
# 作聚会时间(day)和聚会规模(size)的交叉表,pd.crosstab(index, columns),表的内容为计数
party_counts = pd.crosstab(tips['day'],tips['size'])
# 由于规模为1和6的次数都较少,故切片去掉
party_counts = party_counts.loc[:,2:5]
# 规格化,使各行的和为1
party_pcts = party_counts.div(party_counts.sum(1).astype(float),axis=0)
party_pcts.plot(kind='bar',stacked=True)
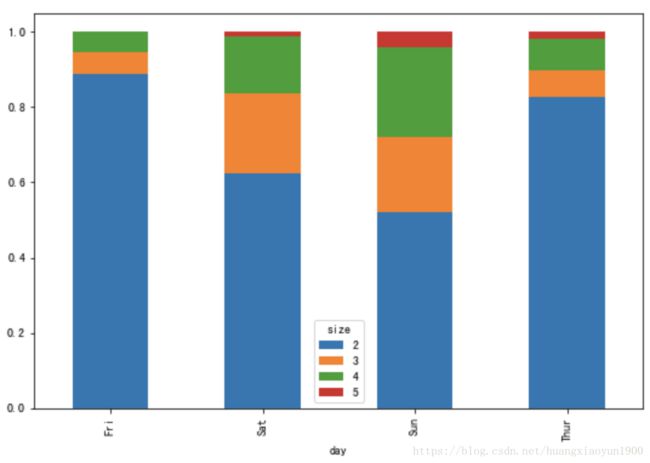
在同一比例下对比不同时间聚会规模的占比,可以明显看得出在周末大规模聚会增多。
3. 直方图histogram和密度图
# 沿用上表-tips.csv
# 由df的某两列运算得到新一列,小费百分比=小费/账单
tips['tip_pct']=tips['tip']/tips['total_bill']
# 绘制直方图
tips['tip_pct'].hist(bins=50)
# 绘制密度图 plot(kind='kde')
tips['tip_pct'].plot(kind='kde')
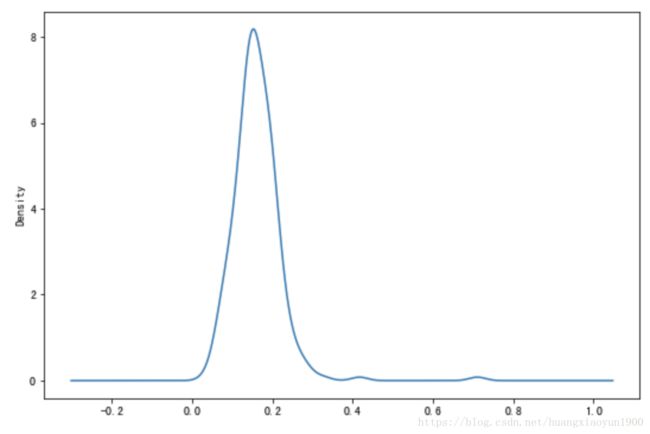
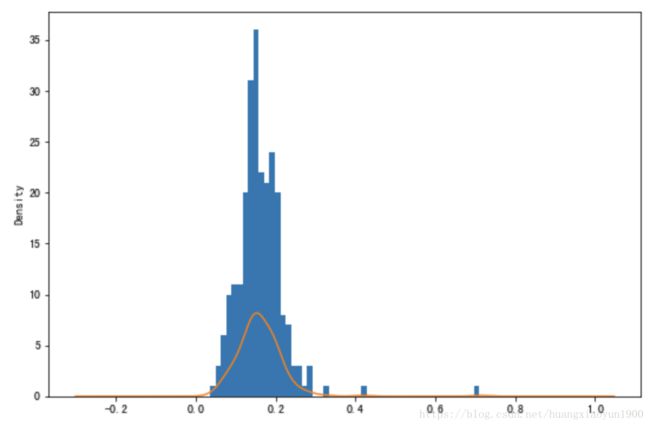
直方图和密度图常常被画在一起:
a. 用pandas API
tips['tip_pct'].hist(bins=50)
tips['tip_pct'].plot(kind='kde')
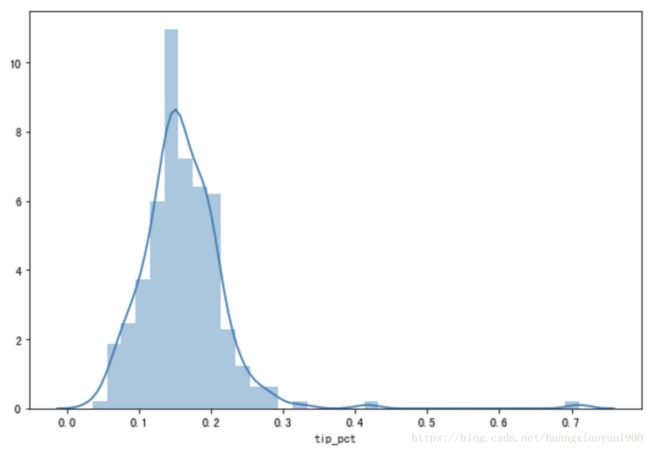
b. 可以用seaborn中的sns.distplot()
import seaborn as sns
sns.distplot(tips['tip_pct'])
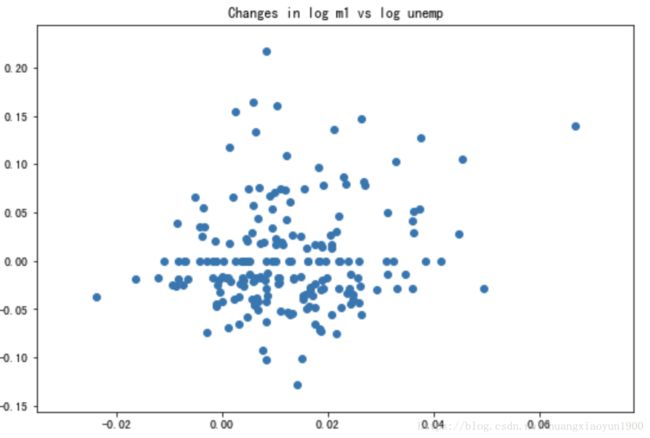
4. 散布图 scatter plot(观察两个一维数据之间的关系)
使用matplotlib和pandas API 作散布图
# 使用matplotlib.pyplot 可直接绘制两列散点图
plt.scatter(trans_data['m1'],trans_data['unemp'])
plt.title('Changes in log %s vs log %s' % ('m1','unemp'))
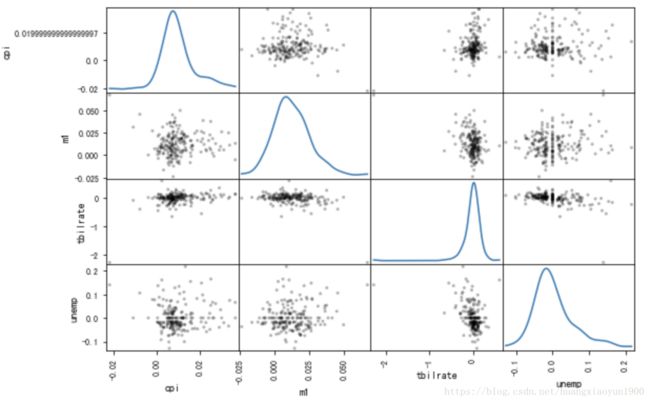
# 使用pandas API 可根据DataFrame创建散布图矩阵,还支持在对角线上放置各变量的直方图或密度图
pd.scatter_matrix(trans_data, diagonal='kde',color='k',alpha=0.3)