神经网络 和 NLP —— 结构化输出预测
不少内容在读 paper 时,已经深入了解过,这里就简单带过了,感兴趣的建议精读原书和参考文献吧。
很多 NLP 任务设计结构化输出,即输出并非类标签或者类标签的概率,而是诸如序列、树、图等结构化的对象。经典任务有序列标注(pos)、序列分割(chunking、NER)、句法分析、MT 等。本文将介绍 NN 在结构化输出任务上的应用。
结构化预测最直接的解决思路就是,基于搜索。
基于搜索的结构化预测,可以形式化为对所有可能的有效结构的搜索问题:

线性模型
利用线性或者对数线性模型进行结构化预测时,即上述打分函数建模为
![]()
其中, ϕ \phi ϕ 是特征抽取函数。通常,为了便于优化求解,会将 y 的结构分解为多 part,打分函数变形为:
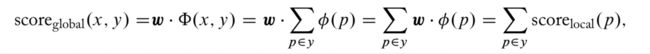
非线性模型
简单的将上述线性函数变为 NN 即可

经典损失函数
最普通的目标自然是让 gold 结构 y 的打分比所有其他结构 y’ 更高就是了:

当然,上面的 max 需要一个专门的搜索算法,后面再说。
上面 loss 缺少了 margin,通常训练会选取 margin-based hinge loss:
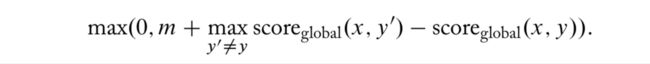
可是,由于不得不对每个 part 逐一评估(计算梯度),即总共 |parts(x,y)| 次,训练和推理都很慢。
cost augmented training (also called loss augmented inference)
再审视下前述 loss,max 项意在寻找一个当前模型打出最高分的错误结构 y’,loss 反映的是 gold 结构 y 与这个错误结构之间的得分差异。当模型训练充分后,就会导致这个充分好的错误结构的得分与 gold 结构的得分非常接近。而全局打分函数是由多个 local part 打分函数求和得到的,这就可能导致多个不同的 local part 的打分项会相互抵消(这些 local part 是分别计算 score 并加和后计算 loss 再 bp 的),从而使得相关参数得不到更新。如果 y 和 y’ 结构相似,那么大部分 local part 将相互重叠并抵消,导致整体非常小的更新。
cost augmented training 的想法就是改变前述 max 项,以便找到被模型打分高但相对错误(有不少错误的 part)的错误结构 y’ 们:
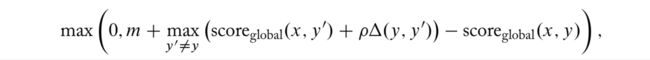
其中,函数 δ \delta δ 计算 y’ 中不正确 part 的数量。
概率目标函数
话说回来,上面的 loss 还是有问题,只顾上让正确的打分比错误的高,但错误的最高分之下的那些错误结构的得分之间的序列关系、分值差异都没有涉及。
这里要提的 CRF 就能处理这个问题了,其构建的打分函数如下:

当然,这时候 loss 通常用对数损失。
近似搜索
上面找到最优结构的过程,无论处理 max 还是分母的 sum,复杂度都是指数级的。为了效率可以采用近似搜索。
一种方法是借助于 beam search,实现近似搜索。当 beam size 为1,显然是贪心策略,为 parts size,那还是原来大小,可以考虑使用动态规划,比如 viterbi。
一种方法是采用 reranking 结构,即先利用 base model 选出 k-best 结构,然后再用复杂 model 来选出 top1。
贪心策略
除了上面介绍的基于搜索的结构化预测方法,如果将结构化预测问题分解为一系列的局部预测问题,并训练一个分类器依次对每个局部问题进行决策。
由于不进行搜索,贪心方法不受限于特征的类型,反而可以使用更丰富的条件结构,也能取得不错的结果。
conditional generation
特地来看下 conditional generation 应用中的 RNN 生成器,也可以看做结构化预测,即生成满足下述目标的序列:

但是由于 RNN 结构不满足马尔科夫性,这个 score 函数没法分解为多个local part,即没法使用标准的动态规划方法实现精确搜索,只能使用近似搜索。
常用的近似方法是贪心预测,每一步都选择打分最高项,虽然高效但显然非最优。改成 beam-search 相对会好不少。
在 conditional generator 训练过程中,teach-force 方式会使用概率目标去尽量分配更高概率给 gold 观测序列,即对于 gold 序列 t 1 : n t_{1:n} t1:n,在 stage i 时,模型会被训练以分配一个高概率给 gold event t ^ i = t i \hat{t}_i=t_i t^i=ti,基于 gold history t 1 : i − 1 t_{1:i-1} t1:i−1。
这个过程存在两个问题,一是生成器在实际中是基于 predicted history t ^ 1 : i − 1 \hat{t}_{1:i-1} t^1:i−1 被分配概率的,二是模型分配概率给所有可能的 event 容易导致 label bias 问题从而影响 beam search 质量,实际上这是一种局部的正则化模型。这两个问题一直在被讨论,但尚无好的方法。
第一个问题可以使用一些训练方法缓解,比如 SEARN、DAGGER、exploration-training with dynamic oracles等。
第二个问题可以通过抛弃局部正则化目标转向全局、序列层面等更适合 beam decoding 的目标来解决,比如 beam approximations of the structured hinge loss、CRF loss等。
例子 —— NER
最基础的,可以采用独立分类框架,即把 NER 看做一个 word-in-context classification problem,假设每个词的标注决策可以独立于其他词进行。
对于句子 s = w 1 , w 2 , . . . , w n s=w_1,w_2,...,w_n s=w1,w2,...,wn,设计特征函数 KaTeX parse error: Expected 'EOF', got '\fsi' at position 1: \̲f̲s̲i̲(i,s) 表征词 w_i 的特征向量,然后对于所有 tag 有预测分数向量:
![]()
然后:
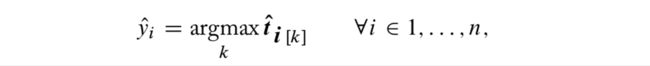
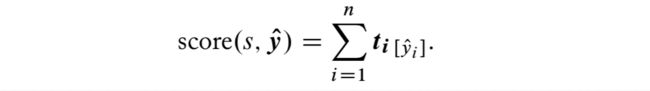
但显然独立预测结构有很大的问题,相邻的预测实际上是会相互影响的,并非独立的。一种方法是引入 tag-tag factors: compatibility scores for pairs of neigh- boring tags. 即对 K 中 tag 构建一个打分矩阵,对每两个 tag 组合给一个 compatibility score,然后在上述 score函数中加入 tagging factors:

当然可以将这种 tagging factors 的引入,看做对问题添加了一阶马尔科夫假设,从而也可以做分解。
进一步可以将上述马尔科夫独立假设放宽到 tag y i y_i yi conditioned on 所有之前的 tag y 1 : i − 1 y_{1:i-1} y1:i−1,这可以通过添加一个model 所有 tag history 的 RNN 到原模型中实现:

不过引入 RNN 也带来了老问题,没法分解然后使用动态规划,只能求助于 beam search 了。