分布式系统监控平台-Overwatch架构设计(已开源)
作者介绍:张玄,毕业于南京大学软件学院。初中开始自学编程,高中参与上海计算机竞赛,荣获第一名。2016年毕业后就职于达达-京东到家基础架构团队,从事基础组件、系统监控等开发工作。
1. 背景Overwatch是达达-京东到家自主研发并开源的分布式系统监控平台,目前广泛用于内部系统的监控,快速定位线上故障源头,并经受住了618单日订单量400万单的考验。
https://github.com/imdada/overwatch
新达达的服务端是一个庞大的、分布式的、微服务化的系统,每时每刻系统之间都有着海量的RPC请求(指广义上的RPC,包括REST接口调用、JDBC等,下同)。在搭建系统的初期,我们仅仅对各个系统的访问日志进行了监控。这样的监控可以让我们发现某个系统是否出现了系统错误(表现如响应了HTTP 500状态码),但是在大多数情况下,我们无法快速定位到出现问题的系统,因为存在如下情况:
-
该系统响应失败是因为调用其他系统失败,报出错误的系统本身并没有问题。
-
调用其他系统失败是由于网络问题,请求并没有到达目标系统,所以在目标系统的日志中看不到任何异常。
-
被调用的系统响应超时,导致调用方主动断开连接,在被调用方的日志中只能看到连接意外中止的异常信息。
-
调用其他系统存在一条很长的调用链,无法快速追踪到源头。
正是由于新达达后台大量的微服务系统以及系统之间复杂的调用依赖关系,加上较复杂的网络环境,导致出现问题后排查十分困难。经常出现几个系统同时开始报警,然后我们开始在多个系统中开始排查问题,最后发现是由于某台数据库机器的网络出现了问题。同时我们也要去确认是否所有的系统都是由于这个问题而引发的报警,浪费了大量的人力。
2. RPC监控 - 数据采集
基于上述情况,我们开始研发Overwatch监控系统,希望能够解决如下问题:
-
实时监控系统中所有的RPC,及时发现所有的RPC调用失败情况。
-
能够在多个系统同时异常时快速定位到异常的根源。
为了能够发现RPC调用失败的所有情况(包括业务问题、系统问题、网络问题),我们讨论如下两种监控方案:
1、从服务提供方监控
对服务提供方应用容器的访问日志(如Tomcat的access.log)进行监控,将所有应用的这些日志文件通过公司现有的日志收集-分析系统进行统一收集分析。这样的方案可以快速实施且无需修改现有代码,开发量也较少。
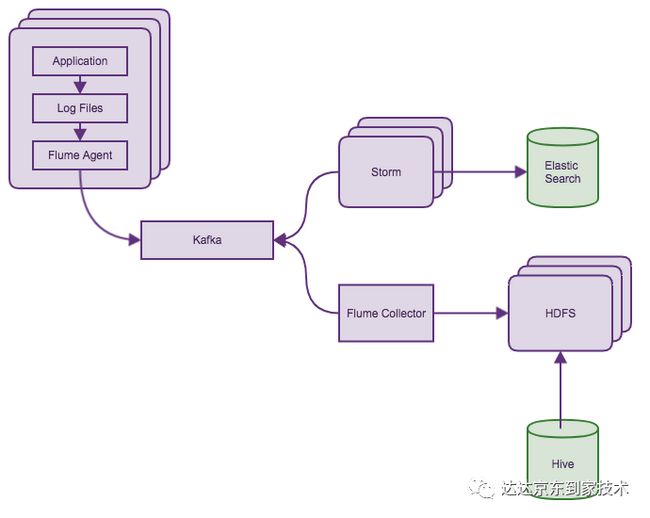
然而这样做的问题也很明显:
-
无法监控到网络问题,因为请求会由于网络原因没有到达服务提供方(Connect Timeout)
-
请求响应超时(Read Timeout),这样的请求不会展现在访问日志中(一些版本的Tomcat存在该问题,包括我们正在使用的版本)
-
无法监控到异常的响应请求,即虽然返回了HTTP 200状态码,但是实际上是请求失败(如返回JSON字符串{“status”: “failed”})
我们不能从服务提供方进行“主观”的监控。服务是给服务消费方使用的,服务提供方所认为的“正确”是不够“客观”的,只有服务消费方认为请求成功,才是“客观”的请求成功。
2、从服务消费方监控
从服务消费方可以实现上述的“客观”的监控。
| 从服务提供方监控 | 从服务消费方监控 | |
|---|---|---|
| 不需修改代码 | Yes | No |
| 感知错误响应 | Yes | Yes |
| 感知网络错误 | No | Yes |
| 感知响应超时 | Maybe | Yes |
| 感知不正确返回值 | No | Yes |
| 实时 | Maybe | Yes |
但是我们需要自己实现信息的收集以及聚合,同时我们需要一个在服务进程中的Agent去收集RPC信息。我们采用了Kafka进行数据的收集,Storm进行数据的聚合,最后将数据交给Overwatch服务进程进行存储和展现。这样我们可以做到一个延迟在秒级的实时监控系统。
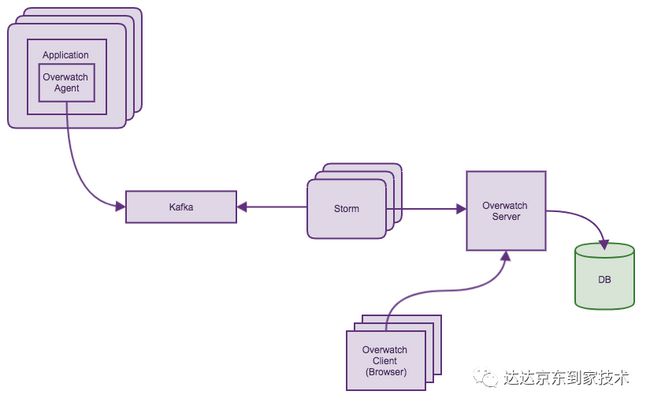
3. RPC监控 - 数据展现
至此,我们还需要解决一个问题:如何能够在多个系统同时异常时,快速定位到异常的根源。传统的监控多以柱状图、折线图的形式展现信息。
这样的信息展现显然不能满足我们的需求,Overwatch在信息的展现方式上需要作出改变,我们采用了有向图的方式展现监控数据。有向图展现RPC监控数据有如下优点:
-
可以在一张图表中完整展现所有系统的状态。
-
由于RPC是有向的(从消费方向提供方),使用有向图可以完美表达出该信息。
-
图可以表达系统之间的依赖关系,当多个系统同时异常时,可以通过观察图中的依赖关系来找到异常的根源。
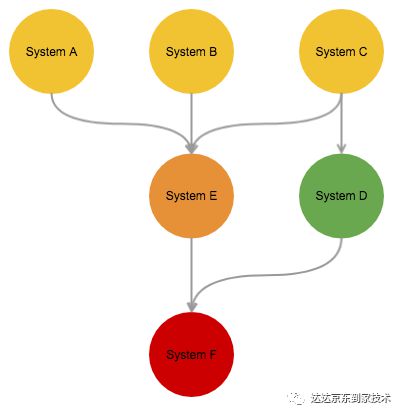
使用有向图也存在一些问题:传统图表可以展现“监控统计值-时间”这样的二维关系,而在有向图中展现这些数据并没有那么简单,我们在之后的章节讨论中会讨论展现的方法。
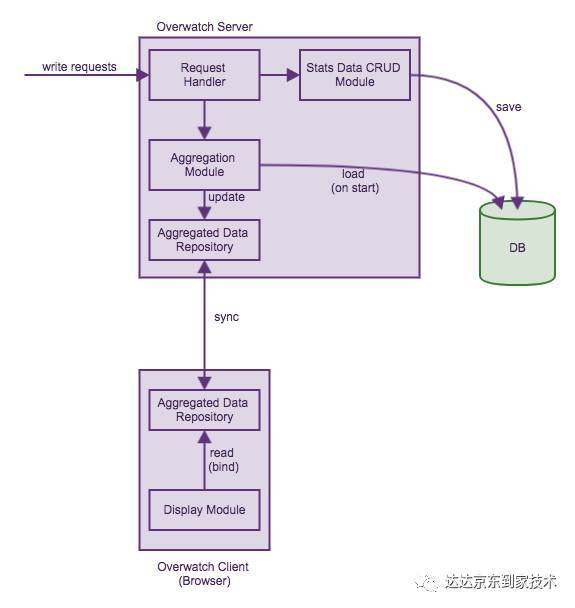
在Overwatch中,我们会展现系统最近一分钟、最近5分钟平均、最近15分钟平均的统计值(类似于Linux中的uptime所展示的信息)。要展现这些数据,Overwatch必须取最近15分钟的所有监控数据,并进行相应的聚合计算,这是开销特别大的操作,显然不可能对于每次用户的查看监控请求都进行一次这样的操作。对于这部分的实现,我们采用了CQRS的模式。
CQRS(Command Query Responsibility Segregation)是指对于数据的修改、更新操作(Command)和读取(Query)操作分别使用不同的Model。这对于普通的CRUD业务需求来说只会增加系统复杂度,但是在Overwatch这样复杂查询、简单写入的场景下,是一种非常合适的模式。
由于Overwatch的服务端由NodeJS实现,所以可以完美实现一个事件驱动的、从服务器到浏览器的CQRS架构。架构设计如下:
4. 可视化有向图设计
上文提到了有向图的问题,即难以展现一个时间轴。显示器都是二维的,传统的柱状图用一维表示统计值,另一维表示时间,二者形成的坐标点和二维显示器上的点对应。而有向图需要展现一个“方向”,节点需要在一个平面内展现,所以显示器上的两个维度已经被用完了。为了展示时间维度的信息,我们采用了显示器的第三个维度——颜色。
我们使用三个同心圆表示一个节点,每个圆的颜色根据该系统所有RPC调用的成功率从蓝(100%)到黄(<99.9%)到红(<99%)。最内侧的圆表示最近一分钟的成功率;中间的圆表示最近5分钟的成功率;最外侧的圆表示最近15分钟的成功率。通过这三个同心圆,我们就可以直观了解到该系统当前的状态以及最近15分钟的变化。

除此之外我们使用节点的大小表示节点最近一分钟的访问量,用边的颜色表示两个系统之间的RPC调用的成功率。
当多个系统同时异常时,通过系统间的依赖关系,我们可以迅速找到异常的根源,也可以评估异常的影响范围。
5. Overwatch系统截图
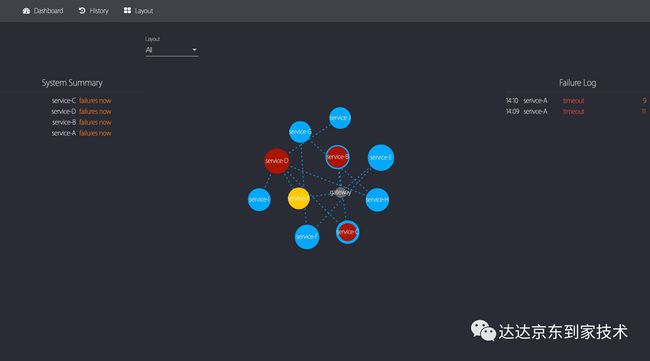
有向图、实时错误日志、系统总览
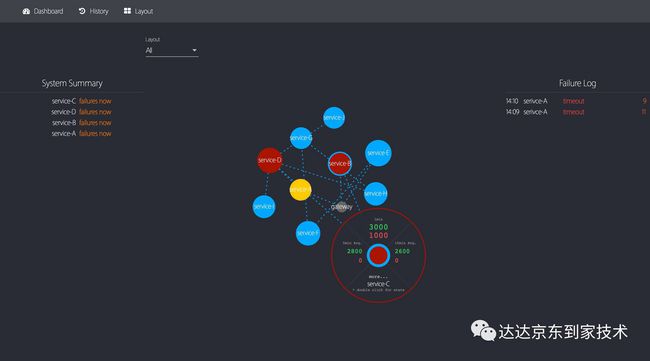
节点信息,包括5分钟、10分钟、15分钟统计
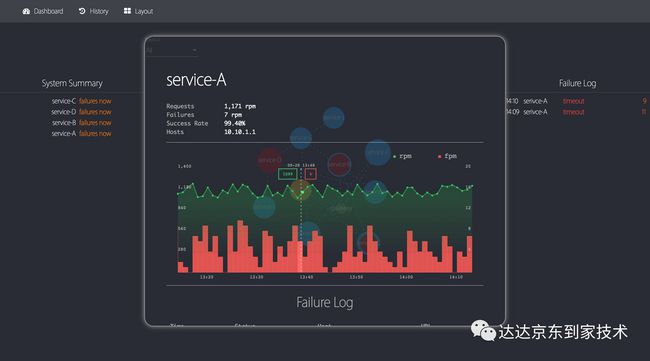
单系统信息快速展示,包括最近一小时统计图表以及错误日志
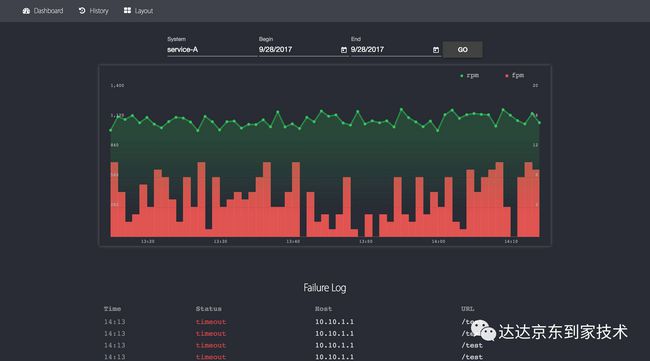
单系统历史信息查询
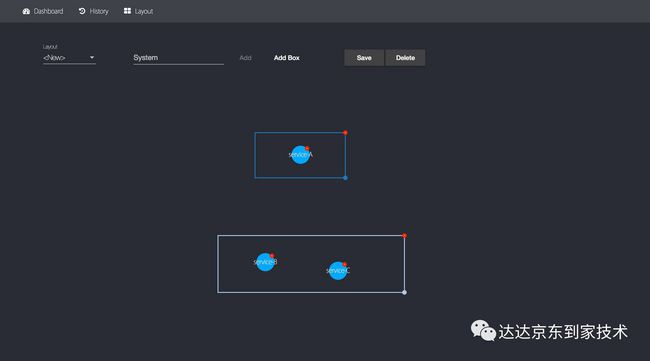
有向图布局设置
6. 总结
Overwatch分布式系统监控平台可以对所有后台系统间的RPC通信进行实时的监控。图形化的展现使得工程师不用去解读大量的、复杂的数据报表。仅通过一张有向图,工程师便可以快速理解并掌握当前系统的整体状况,帮助工程师快速定位并修复系统异常。同时,我们也在不断优化加强Overwatch的功能,Overwatch有着极大的扩展的潜力,通过对客户端收集程序的加强,我们还可以实现以下功能:
-
对于数据源、中间件的监控(如MySQL、Redis、消息队列),在有向图中加入基础组件,全面监控所有系统间的依赖以及调用情况。
-
支持更多RPC协议 (如Thrift、gRPC)
-
更多的metric,实现精确到API的监控和展现
D3: Data-Driven Documents:https://github.com/d3/d3
Martin Fowler on CQRS:https://martinfowler.com/bliki/CQRS.html