首次尝试Flink的一些感受
最近打算研究研究 Flink,根据官方文档写个 Hello,World。入门还是比较容易的,不需要复杂的安装环境、配置。这篇文章简单介绍 Flink 的使用感受以及入门。
感受
搭建环境方便:Flink 可以在 Windows 下运行与开发。对于喜欢 Windows 下开发的人,可以免去搭建虚拟机的成本。并且不依赖其他框架,本地环境搭建简单。这点很关键,许多人学习框架都放弃在了环境搭建上。减少搭建环境的成本,可以避免初学者浪费过多精力。Hadoop 的搭建框架就非常麻烦,并且早期 Hadoop 只能运行在 Linux 下。
文档详细:Flink 官网的文档介绍非常详细,开发过程中会涉及的哪些步骤,以及每个步骤的操作路径,Flink 官网都有详细介绍。包括将 Flink 源码导入 IDEA,这解决了想阅读源码的人的一大痛点。
中文文档:Flink 官网已经有中文版的页面,虽然目前中文页面比较少,应该正在翻译中。说明 Flink 社区比较重视国内开发者。
不依赖 Hadoop:这对于一个全新的框架是件好事,这样可以没有历史包袱。并且对于学习该框架的人可以独立部署、开发,而不需要有其他框架的背景。
关注度在上升:在微信中搜索 Flink 发现大部分文章都是 18、19年写的,说明 Flink 关注度在逐渐上升。一些大厂也都开始使用 Flink 构建实时数据仓库,如:阿里巴巴。可以看出 Flink 致力于为开发者提供一种方便、易用的编程框架。同时,社区非常注重文档的详细程序以及开发者使用的便利性。
下面的内容是搭建 Flink 环境,并运行 WordCount。
本地运行
Flink 可以运行在 Linux、Mac OS X 和 Windows 环境。我喜欢在 Windows 下开发,所以在 Windows 运行 Flink。Flink 的最新版本(1.8.0)需要 JDK 的版本为 1.8 以上。本地启动 Flink 非常容易,下载 Flink 二进制包,需要选择 Scala 的版本,如果不用 Scala 开发 Flink 应用程序选哪个版本无所谓。我下载的是flink-1.8.0-bin-scala_2.11.tgz。启动步骤如下:
cdflink-1.8.0#解压后的目录cdbinstart-cluster.bat#启动本地Flink
启动后会发现弹出了两个 Java 程序的窗口。一个是 JobManager,另一个是 TaskManater。通过http://localhost:8081 访问 Flink 的 web 页面,该站点用于查看运行环境和资源、提交和监控 Flink 作业。
WordCount
通过简单的 WordCount 感受一下 Flink 应用程序的编写过程。Flink 已经提供生成 Maven 工程的模板
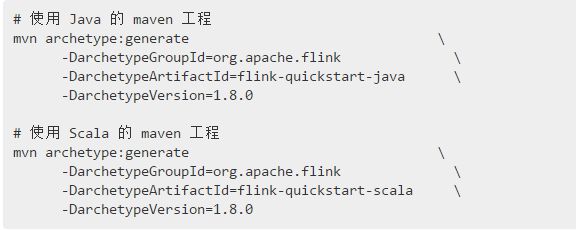
如果不想通过命令行的方式生成 maven 工程,可以通过如下设置在 IDEA 中创建 Flink 应用的模板工程,以 Java 为例
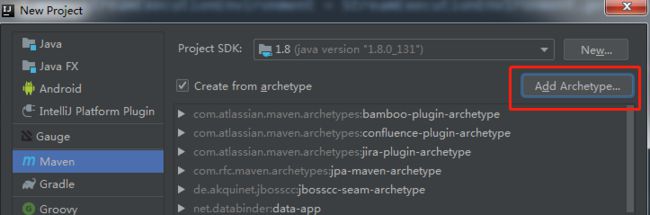
在如上的页面点击 “Add Archetype...”,然后再弹出的对话框填写如下内容

选择我们添加的 archetype 便可继续创建 maven 工程。除了 maven 工程还可以创建 Gradle 和 Sbt 工程。
为了快速运行 Flink 应用,我们可以直接将官网 WordCount 例子的代码拷贝自己的项目。Java 代码如下
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class FirstCase {
public static void main(String[] args) throws Exception {
// the port to connect to
final int port = 9000;
// get the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data by connecting to the socket
DataStreamString text = env.socketTextStream(192.168.29.132, port, \n);
// parse the data, group it, window it, and aggregate the counts
DataStreamWordWithCount windowCounts = text
.flatMap(new FlatMapFunctionString, WordWithCount() {
@Override
public void flatMap(String value, CollectorWordWithCount out) { for (String word : value.split(\\s)) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy(word)
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunctionWordWithCount() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count);
}
});
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1);
env.execute(Socket Window WordCount);
} // Data type for words with count
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + : + count;
}
}
}
虽然不太熟悉 Flink 编程模型,但从上面代码中基本上能推测出每一步的含义。由于我们入门 Flink ,刚开始没必要太纠结代码本身。先将 Demo 运行起来,在慢慢深入学习。现在统计程序已经有了,但是还缺少数据源。官网的例子使用的是 netcat ,我在 Windows 下安装了该工具,但是觉得用起来不方便。在 Linux 虚拟机上装了一个,这样用法跟官网一致的。我的虚拟机系统为 Centos 7 64位,安装命令如下
yum install nmap-ncat.x86_64
启动 netcat 用于发数据
nc -l 9000
接下来便是启动 Flink 应用程序连接数据源并进行统计。 启动之前需要将以下代码中 ip 和 端口换成自己的
DataStreamString text = env.socketTextStream(192.168.29.132, port, \n);
启动 Flink 应用程序有两种方式,一种是直接直接在 IDEA 中直接运行 Java 程序;另一种是通过 maven 打一个 jar 包,提交到 Flink 集群运行。第二种方式的命令如下
$FLINK_HOME\bin\flink run $APP_HOME\flink-ex-1.0-SNAPSHOT.jar
FLINK_HOME 为 flink 二进制包的目录
APP_HOME 为上面创建的 maven 工程的目录
启动 Flink 应用后,我们可以在 netcat 中输入文本,并观察 Flink 的统计结果
$ nc -l 9000a a
我们只发送了一行,内容为“a a”。如果在 IDEA 中启动程序可以直接在 IDEA 控制台看到输出结果,如果通过 flink run 方式启动,需要在 TaskManager 的窗口中查看输出。输出内容如下
a : 2a : 2a : 2a : 2a : 2
为什么输出了 5 次。来看一下我们的应用程序中有这样一句
.timeWindow(Time.seconds(5), Time.seconds(1))
它代表 Flink 应用程序每次处理的数据窗口为 5s,处理完后,整个窗口向前滑动 1s 。也就是每次处理的数据为“最近 5s”的数据。因为最近 5s 数据源中只有“a a”这一条记录,因此输出 5 次。
以上便是 Java 版的 WordCount。当然我们也可以用 Scala 编写,且 Scala 的写法更简洁,代码量更少。
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object SocketWindowWordCount {
def main(args: Array[String]) : Unit = {
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// get input data by connecting to the socket
val text = env.socketTextStream(192.168.29.132, 9000, '\n')
// parse the data, group it, window it, and aggregate the counts
val windowCounts = text
.flatMap { w = w.split(\\s) }
.map { w = WordWithCount(w, 1) }
.keyBy(word)
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum(count)
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1)
env.execute(Socket Window WordCount)
}
// Data type for words with count
case class WordWithCount(word: String, count: Long)
}
基本上是 Java 一半的代码量。个人感觉 Scala 做大数据统计代码还是挺合适的,虽然 Scala 门槛比较高。Scala 程序的运行方式跟 Java 一样。编写过程中如果出现以下错误,需要看看是不是 import 语句没写对
Error:(29, 16) could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[String]
.flatMap { w = w.split(\\s) }
解决方法
import org.apache.flink.streaming.api.scala._
总结
以上便是 Flink 的简单入门,后续继续关注 Flink 框架。