大规模行人重识别检索:向量索引与faiss库
参考资料:
Faiss入门及应用经验记录 - 知乎 (zhihu.com)
向量索引 – 闪念基因 – 个人技术分享 (flashgene.com)
大规模行人重识别检索时,使用暴力检索存在检索时间长内存占用大的问题,解决的方法有主成分分析,哈希,树,图,倒排(IVF),乘积量化(PQ),倒排乘积量化(IVFPQ)等。
1.主成分分析(PCA)
一种特征降维方法,计算协方差矩阵,取协方差矩阵最大的k个特征对应的特征向量矩阵为投影矩阵。
2.哈希
局部敏感哈希(LSH),与其他哈希方法不同,局部敏感哈希希望在原特征空间接近的特征,在哈希空间也接近。
3.树
KD树,从方差最大的维度开始进行划分,在子空间内继续进行划分,直至达到划分要求,查询时根据查询向量,得到叶结点空间,只在叶结点空间内进行查询。
4.倒排(IVF)
将全部待查询向量进行聚类,聚成K类,查询时首先计算查询向量和类中心向量的距离,只在距离最近的类空间内进行查询。
5.乘积量化(PQ)
将特征维度进行切分分为c块,在每个块内进行聚类,聚成k类,得到一个k*c的码本,根据码本对每个特征进行编码即一个c维向量,每维的范围为1-k。利用编码后的向量进行检索。

5.倒排乘积量化(IVFPQ)
先倒排,再在子空间内根据残差向量(特征向量-类中心向量)进行乘积量化。

FAISS
以行人重识别检索为例子来介绍如何使用faiss进行检索,首先是暴力的方法
import faiss
import numpy as np
##读取数据,均为numpy array,维度分别为(q_num,dim),(q_num),(g_num,dim),(g_num)
query,query_lable,gallery,gallery_lable = read_data()
measure = faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(query.shape[1], param, measure)
#index.train(gallery) #暴力方法无需训练
index.add(gallery)
D, I = index.search(query, 100) #查找前100
mAP = calculate_map(query_lable,gallery_lable,D) #计算指标如果使用其他方法只需要改变param,并且在add前进行训练即可,各种方法可以进行组合。
#主成分分析
param = 'PCA32,Flat'
#倒排
param = 'IVF100,Flat'
#乘积量化
param = 'PQ16'
#倒排乘积量化
param = 'IVF100,PQ16'
#哈希
param = 'LSH'
#HNSW
param = 'HNSW64'实验
使用行人重识别特征,其中查询特征19967个,待查询特征274035个,共18000个ID,特征维度为2048,选择mAP为查询评价指标。
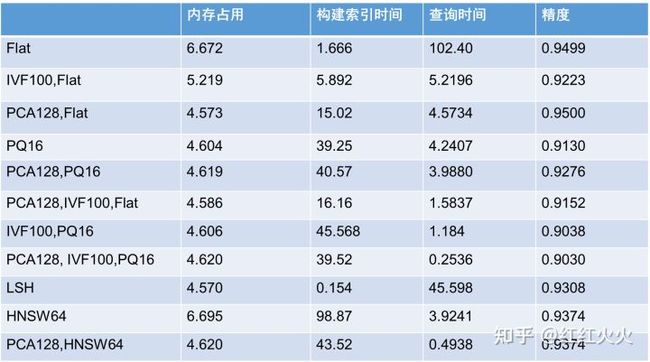
使用PCA后精度基本持平,说明原特征存在一些冗余维度;使用IVF的效果略差于PQ;结合PCA,IVF,PQ查询速度相比暴力查询下降了97.55%,精度仅下降了5.5%;基于HNSW的查询精度高,速度快。