Redis源码和java jdk源码中hashcode的不同实现
一.redis实际上是使用了siphash
这个比较简单,我说的简单是指redis代码比较少不像jdk一样调用C++代码调用栈非常深。
先看这个rehashing.c
主要就是dictKeyHash函数,需要调用dict.h头文件中定义的dictGenHashFunction
#include "redis.h"
#include "dict.h"
void _redisAssert(char *x, char *y, int l) {
printf("ASSERT: %s %s %d\n",x,y,l);
exit(1);
}
unsigned int dictKeyHash(const void *keyp) {
unsigned long key = (unsigned long)keyp;
key = dictGenHashFunction(&key,sizeof(key));
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
int dictKeyCompare(void *privdata, const void *key1, const void *key2) {
unsigned long k1 = (unsigned long)key1;
unsigned long k2 = (unsigned long)key2;
return k1 == k2;
}
dictType dictTypeTest = {
dictKeyHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictKeyCompare, /* key compare */
NULL, /* key destructor */
NULL /* val destructor */
};
dict.h
uint64_t dictGenHashFunction(const void *key, int len);
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len);
void dictEmpty(dict *d, void(callback)(void*));
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);
int dictRehashMilliseconds(dict *d, int ms);
void dictSetHashFunctionSeed(uint8_t *seed);
uint8_t *dictGetHashFunctionSeed(void);
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, dictScanBucketFunction *bucketfn, void *privdata);
uint64_t dictGetHash(dict *d, const void *key);
dictEntry **dictFindEntryRefByPtrAndHash(dict *d, const void *oldptr, uint64_t hash);
代码实现是在dict.c
注释已经说明了是实现在siphash.c
/* The default hashing function uses SipHash implementation
* in siphash.c. */
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t siphash_nocase(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key,len,dict_hash_function_seed);
}
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len) {
return siphash_nocase(buf,len,dict_hash_function_seed);
}
其实这个siphash.c是第三方实现的github上有源码,这里只应用作者的说明就行了:
/*
SipHash reference C implementation
Copyright (c) 2012-2016 Jean-Philippe Aumasson
Copyright (c) 2012-2014 Daniel J. Bernstein
Copyright (c) 2017 Salvatore Sanfilippo
To the extent possible under law, the author(s) have dedicated all copyright
and related and neighboring rights to this software to the public domain
worldwide. This software is distributed without any warranty.
You should have received a copy of the CC0 Public Domain Dedication along
with this software. If not, see
in the following ways:
1. We use SipHash 1-2. This is not believed to be as strong as the
suggested 2-4 variant, but AFAIK there are not trivial attacks
against this reduced-rounds version, and it runs at the same speed
as Murmurhash2 that we used previously, why the 2-4 variant slowed
down Redis by a 4% figure more or less.
2. Hard-code rounds in the hope the compiler can optimize it more
in this raw from. Anyway we always want the standard 2-4 variant.
3. Modify the prototype and implementation so that the function directly
returns an uint64_t value, the hash itself, instead of receiving an
output buffer. This also means that the output size is set to 8 bytes
and the 16 bytes output code handling was removed.
4. Provide a case insensitive variant to be used when hashing strings that
must be considered identical by the hash table regardless of the case.
If we don't have directly a case insensitive hash function, we need to
perform a text transformation in some temporary buffer, which is costly.
5. Remove debugging code.
6. Modified the original test.c file to be a stand-alone function testing
the function in the new form (returing an uint64_t) using just the
relevant test vector.
*/
作者官网:https://131002.net/siphash/
源代码:https://github.com/veorq/SipHash
SipHash:快速短输入PRF
下载 | 攻击 | 用户 | CRYPTANALYSIS | 第三方实施
SipHash是一系列伪随机函数(也称为键控散列函数),针对短消息的速度进行了优化。
目标应用程序包括网络流量身份验证和 防止散列泛滥 DoS攻击。
SipHash 安全,快速,简单(真实):
- SipHash比以前的加密算法更简单,更快(例如基于通用哈希的MAC)
- SipHash在性能上与不安全的 非加密算法竞争(例如MurmurHash)
我们建议哈希表切换到SipHash作为哈希函数。 SipHash的用户已经包括FreeBSD,OpenDNS,Perl 5,Ruby或Rust。
原始SipHash返回64位字符串。随后根据用户的需求创建了返回128位字符串的版本。
知识产权: 我们不了解与SipHash相关的任何专利或专利申请,我们也不打算申请任何专利。SipHash 的参考代码是在CC0许可下发布的,这是一种类似公共领域的许可。
SipHash的设计者是
- Jean-Philippe Aumasson(瑞士Kudelski Security)
- Daniel J. Bernstein(美国伊利诺伊大学芝加哥分校)
联系方式:[email protected] [email protected]
下载
- 研究论文 “SipHash:快速短期投入PRF”(在DIAC研讨会和INDOCRYPT 2012上 接受发表)
- 2012年INDOCRYPT(伯恩斯坦)SipHash演讲的 幻灯片
- 在DIAC(Aumasson)展示SipHash的 幻灯片
- 参考C实现。
=============================================================
二.java的实现比较复杂
又要分字符串的hashCode()和object的hashCode()
1.字符串的hashCode()
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
*
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
*
* using {@code int} arithmetic, where {@code s[i]} is the
* ith character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
需要注意的是为什么 String hashCode 方法选择数字31作为乘子,可以看看这篇帖子,这个属于数学问题了。
原因就是
第一,31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。另外一些相近的质数,比如37、41、43等等,也都是不错的选择。
第二、31可以被 JVM 优化,31 * i = (i << 5) - i。
Stack Overflow 上关于这个问题的讨论,Why does Java's hashCode() in String use 31 as a multiplier?。其中排名第一的答案引用了《Effective Java》中的一段话,这里也引用一下:
选择值31是因为它是奇数素数。 如果它是偶数并且乘法溢出,则信息将丢失,因为乘以2相当于移位。
使用素数的优势不太明显,但它是传统的。
31的一个很好的特性是乘法可以用移位和减法代替以获得更好的性能:
31 * i ==(i << 5) - i`。 现代VM自动执行此类优化。
其他解释:
正如 Goodrich 和 Tamassia 指出的那样,如果你对超过 50,000 个英文单词
(由两个不同版本的 Unix 字典合并而成)进行 hash code 运算,
并使用常数 31, 33, 37, 39 和 41 作为乘子,每个常数算出的哈希值冲突数都小于7个,
所以在上面几个常数中,常数 31 被 Java 实现所选用也就不足为奇了。
这个问题到底完结。
------------------------------------
2.jdk1.8 Object的hashCode()
完整的流程:
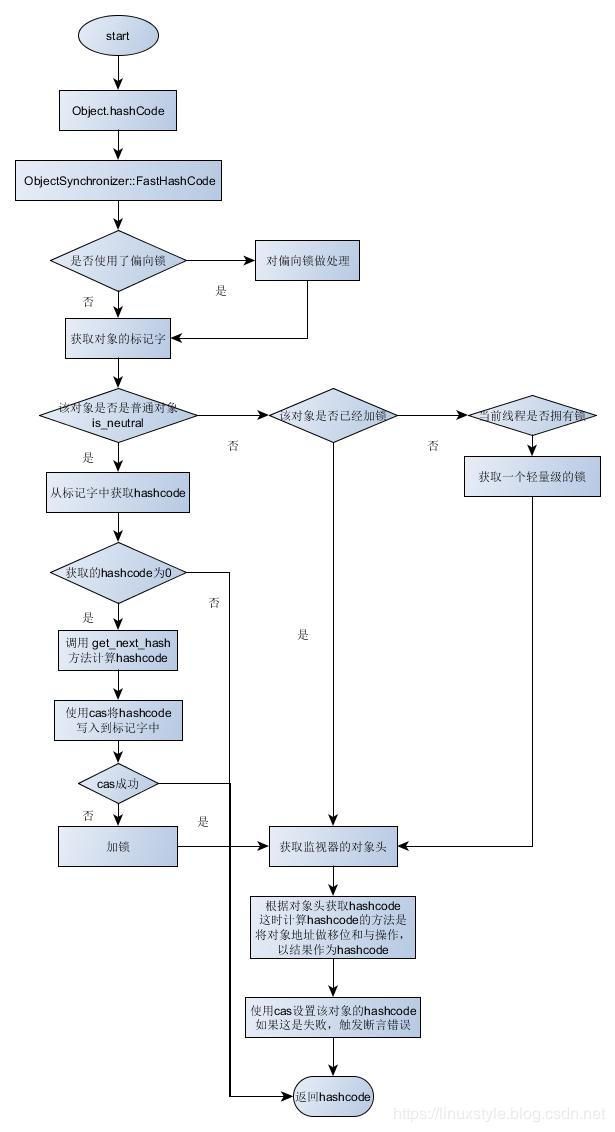
此图出自:《hotspot中java对象默认hashcode的生成方式 》
先看hashmap算key的hashCode源码
大量使用hash函数
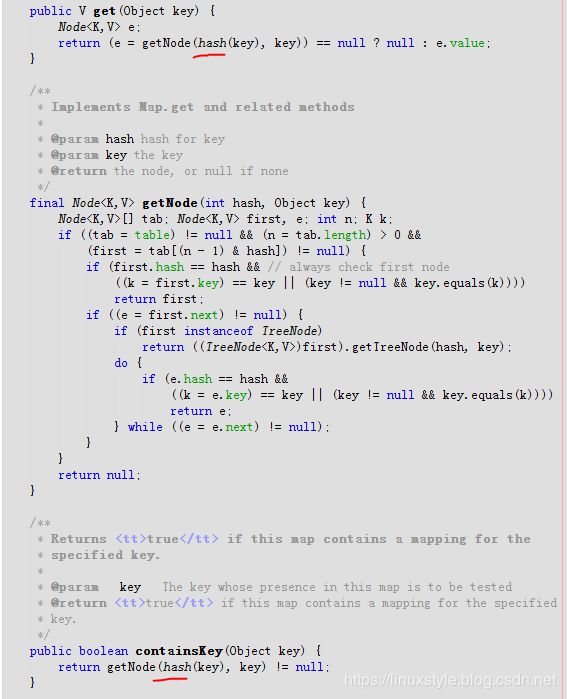
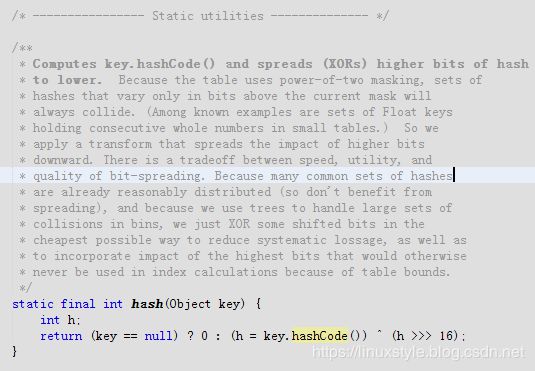
翻译如下:
/ * ----------------静态实用程序-------------- * /
计算key.hashCode()并将散列(XOR)更高的散列位降低。
因为该Table使用2次幂掩蔽,所以仅在当前掩码之上的位中变化的散列组将始终发生冲突。 (在已知的例子中是一组Float键,在小表中保存连续的整数。)
因此,我们应用一种向下传播较高位的影响的变换。
在速度,效用和比特扩展质量之间存在权衡。 因为许多常见的哈希集合已经合理分布(因此不会受益于传播),并且因为我们使用树来处理容器中的大量冲突,所以我们只是以最简易的方式对一些移位的位进行异或,以减少系统损失, 以及由于Table边界而包含最高位的影响,否则这些位将永远不会用于索引计算。
直接是native的实现了

如何在jvm源码中定位到某个Java本地方法对应的本地方法源码
比如说java.lang.Object#hashCode(),如何在jvm源码定位它?
从 jdk/src/share/native/java/lang/Object.c 文件里, 你可以找到
{"hashCode", "()I", (void *)&JVM_IHashCode},
{"wait", "(J)V", (void *)&JVM_MonitorWait},
{"notify", "()V", (void *)&JVM_MonitorNotify},
{"notifyAll", "()V", (void *)&JVM_MonitorNotifyAll},
{"clone", "()Ljava/lang/Object;", (void *)&JVM_Clone},
大致调用链是:
jvm.cpp中定义了JVM_IHashCode()函数, 他又调用ObjectSynchronizer::FastHashCode;
FastHashCode在 synchronizer.cpp, FastHashCode调用get_next_hash()。
真正的计算hashcode的代码在 synchronizer.cpp的get_next_hash()。
jvm.cpp
// java.lang.Object ///////////////////////////////////////////////
JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
JVMWrapper("JVM_IHashCode");
// as implemented in the classic virtual machine; return 0 if object is NULL
return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
JVM_END
synchronizer.cpp
intptr_t ObjectSynchronizer::FastHashCode (Thread * Self, oop obj) {
if (UseBiasedLocking) {
// NOTE: many places throughout the JVM do not expect a safepoint
// to be taken here, in particular most operations on perm gen
// objects. However, we only ever bias Java instances and all of
// the call sites of identity_hash that might revoke biases have
// been checked to make sure they can handle a safepoint. The
// added check of the bias pattern is to avoid useless calls to
// thread-local storage.
if (obj->mark()->has_bias_pattern()) {
// Box and unbox the raw reference just in case we cause a STW safepoint.
Handle hobj (Self, obj) ;
// Relaxing assertion for bug 6320749.
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(),
"biases should not be seen by VM thread here");
BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());
obj = hobj() ;
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
}
// hashCode() is a heap mutator ...
// Relaxing assertion for bug 6320749.
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(), "invariant") ;
assert (Universe::verify_in_progress() ||
Self->is_Java_thread() , "invariant") ;
assert (Universe::verify_in_progress() ||
((JavaThread *)Self)->thread_state() != _thread_blocked, "invariant") ;
ObjectMonitor* monitor = NULL;
markOop temp, test;
intptr_t hash;
markOop mark = ReadStableMark (obj);
// object should remain ineligible for biased locking
assert (!mark->has_bias_pattern(), "invariant") ;
if (mark->is_neutral()) {
hash = mark->hash(); // this is a normal header
if (hash) { // if it has hash, just return it
return hash;
}
hash = get_next_hash(Self, obj); // allocate a new hash code
temp = mark->copy_set_hash(hash); // merge the hash code into header
// use (machine word version) atomic operation to install the hash
test = (markOop) Atomic::cmpxchg_ptr(temp, obj->mark_addr(), mark);
if (test == mark) {
return hash;
}
// If atomic operation failed, we must inflate the header
// into heavy weight monitor. We could add more code here
// for fast path, but it does not worth the complexity.
} else if (mark->has_monitor()) {
monitor = mark->monitor();
temp = monitor->header();
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash();
if (hash) {
return hash;
}
// Skip to the following code to reduce code size
} else if (Self->is_lock_owned((address)mark->locker())) {
temp = mark->displaced_mark_helper(); // this is a lightweight monitor owned
assert (temp->is_neutral(), "invariant") ;
hash = temp->hash(); // by current thread, check if the displaced
if (hash) { // header contains hash code
return hash;
}
// WARNING:
// The displaced header is strictly immutable.
// It can NOT be changed in ANY cases. So we have
// to inflate the header into heavyweight monitor
// even the current thread owns the lock. The reason
// is the BasicLock (stack slot) will be asynchronously
// read by other threads during the inflate() function.
// Any change to stack may not propagate to other threads
// correctly.
}
// Inflate the monitor to set hash code
monitor = ObjectSynchronizer::inflate(Self, obj);
// Load displaced header and check it has hash code
mark = monitor->header();
assert (mark->is_neutral(), "invariant") ;
hash = mark->hash();
if (hash == 0) {
hash = get_next_hash(Self, obj);
temp = mark->copy_set_hash(hash); // merge hash code into header
assert (temp->is_neutral(), "invariant") ;
test = (markOop) Atomic::cmpxchg_ptr(temp, monitor, mark);
if (test != mark) {
// The only update to the header in the monitor (outside GC)
// is install the hash code. If someone add new usage of
// displaced header, please update this code
hash = test->hash();
assert (test->is_neutral(), "invariant") ;
assert (hash != 0, "Trivial unexpected object/monitor header usage.");
}
}
// We finally get the hash
return hash;
}
// hashCode() generation :
//
// Possibilities:
// * MD5Digest of {obj,stwRandom}
// * CRC32 of {obj,stwRandom} or any linear-feedback shift register function.
// * A DES- or AES-style SBox[] mechanism
// * One of the Phi-based schemes, such as:
// 2654435761 = 2^32 * Phi (golden ratio)
// HashCodeValue = ((uintptr_t(obj) >> 3) * 2654435761) ^ GVars.stwRandom ;
// * A variation of Marsaglia's shift-xor RNG scheme.
// * (obj ^ stwRandom) is appealing, but can result
// in undesirable regularity in the hashCode values of adjacent objects
// (objects allocated back-to-back, in particular). This could potentially
// result in hashtable collisions and reduced hashtable efficiency.
// There are simple ways to "diffuse" the middle address bits over the
// generated hashCode values:
//
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// This form uses an unguarded global Park-Miller RNG,
// so it's possible for two threads to race and generate the same RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random() ;
} else
if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addrBits = cast_from_oop(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) {
value = 1 ; // for sensitivity testing
} else
if (hashCode == 3) {
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) {
value = cast_from_oop(obj) ;
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
翻译下:
hashCode()生成:
可能性:
* {obj,stwRandom}的MD5Digest
* {obj,stwRandom}的CRC32或任何线性反馈移位寄存器功能。
* DES或AES风格的SBox []机制
*基于Phi的方案之一,例如:
2654435761 = 2^32 * Phi (golden ratio)
HashCodeValue =((uintptr_t(obj)>> 3)* 2654435761)^ GVars.stwRandom;
* Marsaglia的shift-xor RNG方案的变体。
*(obj ^ stwRandom)很有吸引力,但可能导致相邻对象(特别是背靠背分配的对象)的hashCode值出现不合需要的规律性。 这可能会导致哈希表冲突并降低哈希表效率。
有一些简单的方法可以在生成的hashCode值上“扩散”中间地址位。
该函数提供了基于某个hashCode 变量值的六种方法。怎么生成最终值取决于hashCode这个变量值。
0 - 使用Park-Miller伪随机数生成器(跟地址无关)
1 - 使用地址与一个随机数做异或(地址是输入因素的一部分)
2 - 总是返回常量1作为所有对象的identity hash code(跟地址无关)
3 - 使用全局的递增数列(跟地址无关)
4 - 使用对象地址的“当前”地址来作为它的identity hash code(就是当前地址)
5 - 使用线程局部状态来实现Marsaglia's xor-shift随机数生成(跟地址无关)
Xorshift随机数生成器是George Marsaglia发现的一类伪随机数生成器:
VM到底用的是哪种方法?
JDK 8 和 JDK 9 默认值:

JDK 8 以前默认值:是传0
虽然方式不一样,但有个共同点:java生成的hashCode和对象内存地址没什么关系。
HotSpot提供了一个VM参数来让用户选择identity hash code的生成方式:
#-XX:hashCode
参考:https://zhuanlan.zhihu.com/p/28270828
public static void main(String[] args) {
int[] arr0 = new int[3];
int[] arr1 = new int[3];
//arr0.hashCode(); // 触发arr0计算identity hash code
//arr1.hashCode(); // 触发arr1计算identity hash code
System.out.println(arr0);
System.out.println(arr1);
}
实验:
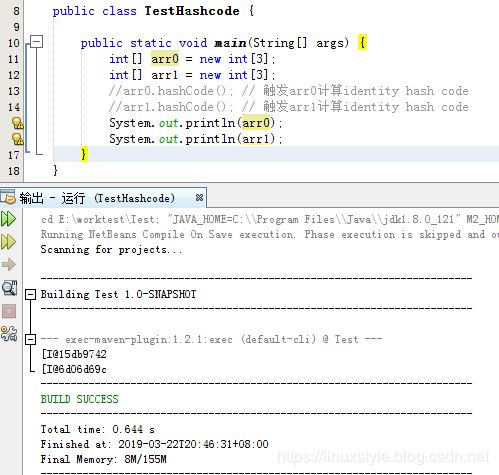
交互arr0和1
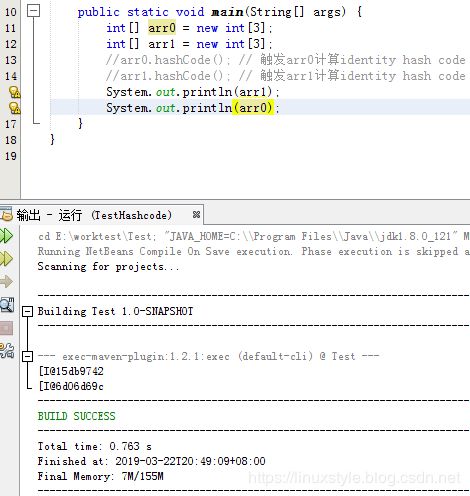
两次输出一样的地址,加上hashCode()就和顺序有关了:
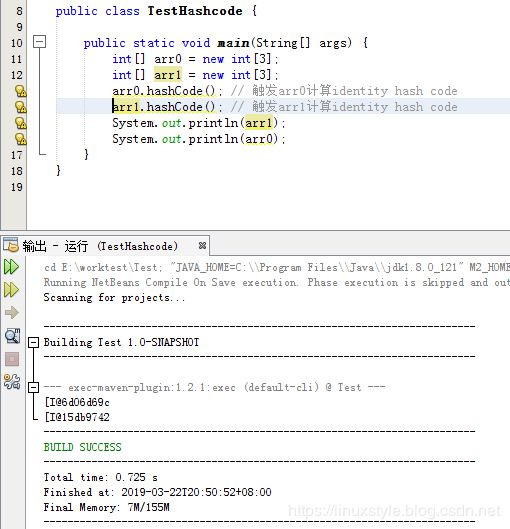
原因是:
对象的hashcode并不是在创建对象时就计算好的,而是在第一次使用的时候,也就是首次调用hashCode方法时进行计算,并存储在对象的标记字中的。
在VM里,Java对象会在首次真正使用到它的identity hash code(例如通过Object.hashCode() / System.identityHashCode())时调用VM里的函数来计算出值,然后会保存在对象里,后面对同一对象查询其identity hash code时总是会返回最初记录的值。
不是在对象创建时计算的。
这组实现代码在HotSpot VM里自从JDK6的早期开发版开始就没变过,只是hashCode选项的默认值变了而已。
上面的程序在执行到这个 hashCode() 调用时,VM看到对象之前还没计算 identity hash code,才去计算并记录它。
这样的话,先 println(arr1) 就会使得 arr0 所引用的数组对象先被计算 identity hash code,在VM上就是从伪随机数列中取出某一项,然后再 println(arr2) 就会计算并记录 arr2 所引用的数组对象的 hash code,也就是取出那个伪随机数列的下一项。反之亦然。
所以无论先 println(arr1) 还是先 println(arr2) ,看到的都是 VM用来实现 identity hash code 的伪随机数列的某个位置的相邻两项,自然怎么交换都会看到一样的结果。
而如果不调用hash code自然就会触发identity hash code,所以交换顺序就没用...
这篇帖子也写得很好可以看看,作者对jvm是有一些深入的研究的:《How does the default hashCode() work?》
--------------
《Java Challengers #4: Comparing Java objects with equals() and hashcode()》
《Java Challengers #2: String comparisons How String methods, keywords, and operators process comparisons in the String pool》
先看源码
Object.java的equals:
public boolean equals(Object obj) {
return (this == obj);
}
String.java中的equals:
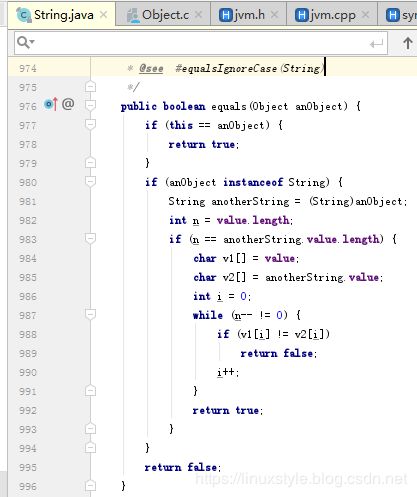
使用String类的Equals方法
该equals()方法用于验证两个Java类的状态是否相同。因为equals()来自Object类,所以每个Java类都继承它。但equals()必须重写该方法才能使其正常工作。当然,String覆盖equals()。
关于字符串要记住什么
Strings是不可变的,所以String不能改变状态。- 为了节省内存,JVM将
Strings 保留在常量池中。String创建new时,JVM会检查其值并将其指向现有对象。如果常量池中没有该值,则JVM会创建一个新值String。 - 使用
==运算符比较对象引用。使用该equals()方法比较的值String。相同的规则将应用于所有对象。 - 使用
new运算符时,即使存在具有相同值的值,String也会在String池中创建新的运算符String。
-------------------------
下面都是Object的equals
equals()和hashcode()的常见错误
- 忘记
hashcode()与equals()方法一起覆盖,反之亦然。 - 不覆盖
equals()和hashcode()使用哈希集合时HashSet。 - 返回方法中的常量值,
hashcode()而不是返回每个对象的唯一代码。 - 使用
==和equals互换。的==比较Object参考,而equals()比较对象值。
关于equals()和hashcode()要记住什么
- 在POJO中始终覆盖
equals()和hashcode()方法是一种很好的做法。 - 使用有效算法生成唯一的哈希码。
- 覆盖
equals()方法时,也始终覆盖该hashcode()方法。 - 该
equals()方法应该比较整个对象的状态:来自字段的值。 - 该
hashcode()方法可以是POJO的ID。 - 当比较两个对象的哈希码的结果为假时,该
equals()方法也应该为假。 - 如果
equals()和hashcode()使用哈希集合时没有被重载,集合会有重复的元素。
使用equals()和hashcode()的准则
您应该只equals()为具有相同唯一哈希码ID的对象执行方法。当哈希码ID 不同时,不应执行equals()。
表1.哈希码比较
如果hashcode()比较...... |
然后 … |
|---|---|
| 返回true | 执行 equals() |
| 返回false | 不要执行 equals() |
出于性能原因,该原则主要用于Set或Hash收集。
对象比较规则
当hashcode()比较返回false,该equals()方法也必须返回false。如果哈希码不同,则对象肯定不相等。
表2.与hashcode()的对象比较
| 当哈希码比较返回时...... | 该equals()方法应该返回... |
|---|---|
| 真正 | 对或错 |
| 假 | 假 |
当equals()方法返回true,这意味着该对象相等的所有的值和属性。在这种情况下,哈希码比较也必须为真。
表3.与equals()的对象比较
当equals()方法返回时...... |
该hashcode()方法应该返回... |
|---|---|
| 真正 | 真正 |
| 假 | 对或错 |
总结:
==永远是比较地址;
new出来的两个对象地址自然也是不相等的;
equals默认比较地址也就是和==等效,如果是字符串是比较内容而不是地址。
如果重写了equals需要同步重写 hashCode()