TensorFlow精进之路(十六):使用slim模型库对图片分类
1、概述
TF-slim是tensorflow的一个轻量级库,它将很多常见tensorflow函数进行封装,使的模型的构建、训练、测试都更加简洁,特别适用于构建结构复杂的深度神经网络。github地址为:https://github.com/tensorflow/models/tree/master/research/slim
2、下载models模块
到https://github.com/tensorflow/models上将models模块下载下载,当然也可以用git下载,命令为
git clone https://github.com/tensorflow/models.git
下载完以后,cd models/research/slim/,slim目录下就是我们要用到的模块。
3、验证slim库
在使用slim库之前,先测试本地tensorflow版本是否集成slim模块。先来验证tf.contrib.slim模块是否有效,执行以下命令:
python -c "import tensorflow.contrib.slim as slim;
eval = slim.evaluation.evaluate_once"
没有错误即slim可以工作。
再验证刚下载的模块是否正确,执行以下命令,
cd models/research/slim/
python -c "from nets import cifarnet;mynet = cifarnet.cifarnet"
没有错误即可。
4、目录结构
slim目录下的文件如下图所示,
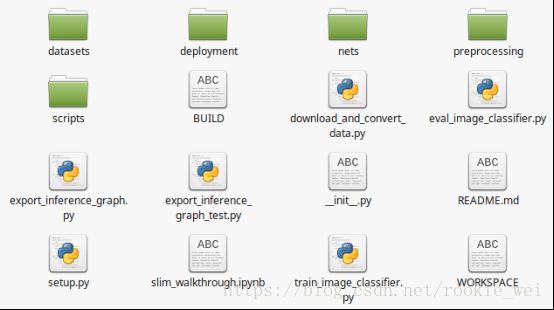
其主要文件夹和文件用途如下表所示

5、下载数据集
slim集成的数据集如下:
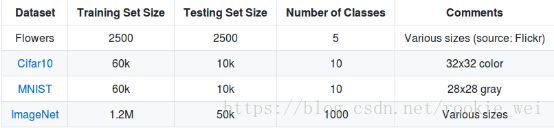
下面就以Flowers数据集为例,用slim下载并训练该数据集。Flowers数据集共有2500张训练图片和2500张测试图片,共5个分类,分别是菊(daisy)、蒲公英(dandelion)、玫瑰(roses)、向日葵(sunflowers)、郁金香(tulips)。
首先下载并转换数据集,执行以下命令,
python download_and_convert_data.py \
--dataset_name=flowers --dataset_dir=images_data/flowers
下载完以后,目录内容如下,

可以看到,数据集被转成tfrecord格式了。tfrecord格式是tensorflow推荐的数据集格式,将原始文件转成tensorflow格式,在运行中通过多线程读取,可以减小主线程训练负担,让训练更高效。
也可以从这个网址下载原图数据集:
http://download.tensorflow.org/example_images/flower_photos.tgz
下载后解压,目录结构如下所示,

每个子文件夹下是对应品种的图片,如daisy,

6、读取tfrecord中的数据
slim的用法可以查看slim目录下的README.md文件,上面的验证slim、下载数据集的命令其实就是从这个文档看到的。
6.1、创建slim数据集描述符
#encoding:utf-8
from datasets import flowers
import tensorflow as tf
import pylab
slim = tf.contrib.slim
#flowers数据集目录
DATA_DIR = 'images_data/flowers/'
#指定获取“validation”下的数据
dataset = flowers.get_split('validation', DATA_DIR)
# Creates a TF-Slim DataProvider which reads the dataset in the background
# during both training and testing.
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])
6.2、在session下读取数据并显示
#在session下读取数据,并用pylab显示图片
with tf.Session() as sess:
#初始化变量
sess.run(tf.global_variables_initializer())
#启动队列
tf.train.start_queue_runners()
image_batch,label_batch = sess.run([image, label])
#显示图片
pylab.imshow(image_batch)
pylab.show()
6.3、显示结果
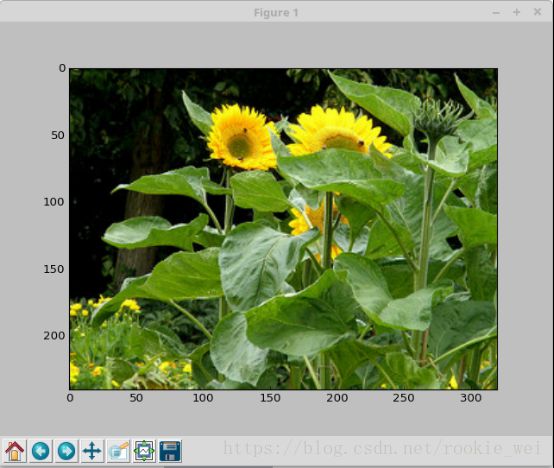
7、训练模型
训练的方法和命令可以参考scripts目录下的脚本,如果是linux等支持shell脚本的系统,可以直接运行这些脚本,这些脚本提供了下载、训练、预训练、微调、测试的命令。slim提供了从头训练、预训练模型、微调模型来训练数据集,下面分别讲解。
7.1、从头训练
这里用flowers数据集来训练Inception_v3结构的神经网络模型,可以参考train_image_classifier.py文件和scripts/finetune_inception_v3_on_flowers.sh文件。执行如下命令:
mkdir -p saver/inv3_flowers
然后执行,
python train_image_classifier.py \
--train_dir=saver/inv3_flowers \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--max_number_of_steps=500 \
--batch_size=32 \
--learning_rate=0.0001 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004
很不幸,GPU发生了内存溢出错误,错误如下,
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info
我看了一下显卡,未运行时的情况如下图所示,内存占用了221M(11%),
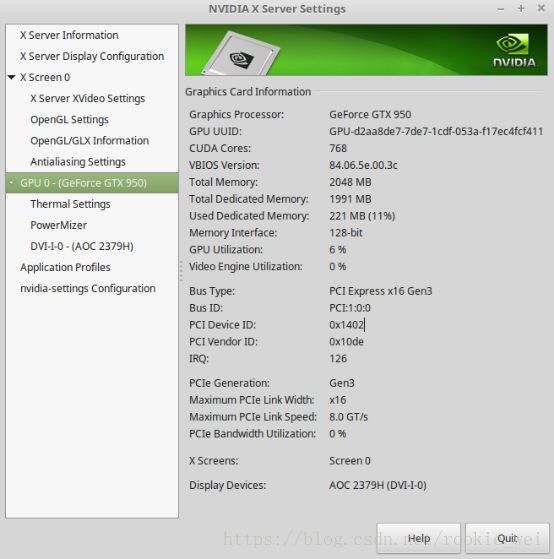
运行以后,内存一下子就占了93%,如下图所示,
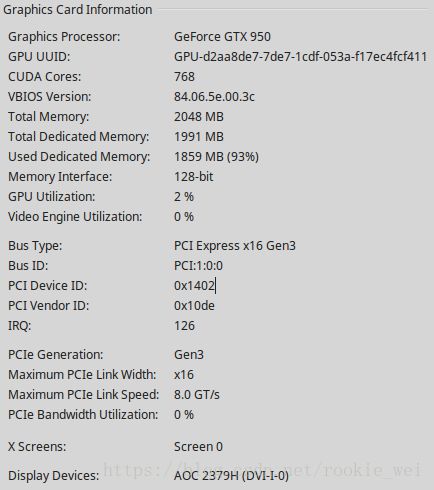
解决方法:
方法一:最简单的一个方法就是不用GPU训练,只用CPU来训练,修改
train_image_classifier.py文件,在
import tensorflow as tf
上添加
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1"
即可。但是用CPU训练深度神经网络,你会有想砸了电脑的冲动,所以这个方法对于有GPU的电脑来说,还是找其他方法吧。
方法二:GPU内存溢出,很容易想到的一个原因是,是否我们每次传入的数据太大了?所以试着修改batch的大小,查看命令参数,--batch_size=应该就是设置batch的大小了,我们将--batch_size=设置小一点试试,执行下面命令:
python train_image_classifier.py \
--train_dir=saver/inv3_flowers \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--max_number_of_steps=500 \
--batch_size=5 \
--learning_rate=0.0001 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004
ok,没有错误了,而且速度快很多。用CPU训练,我洗澡回来都还在训练,用GPU,一下子就训练完了。
训练结果:
INFO:tensorflow:global step 440: loss = 3.0995 (0.346 sec/step)
INFO:tensorflow:Saving checkpoint to path saver/inv3_flowers/model.ckpt
INFO:tensorflow:global_step/sec: 2.94988
INFO:tensorflow:Recording summary at step 447.
INFO:tensorflow:global step 450: loss = 2.9969 (0.330 sec/step)
INFO:tensorflow:global step 460: loss = 3.0126 (0.340 sec/step)
INFO:tensorflow:global step 470: loss = 3.1229 (0.337 sec/step)
INFO:tensorflow:global step 480: loss = 2.9468 (0.354 sec/step)
INFO:tensorflow:global step 490: loss = 2.4962 (0.342 sec/step)
INFO:tensorflow:global step 500: loss = 2.8909 (0.303 sec/step)
INFO:tensorflow:Stopping Training.
INFO:tensorflow:Finished training! Saving model to disk.
7.2、预训练模型
预训练就是在别人训练好的模型的基础上进行二次训练,以得到自己需要的模型,一般是只训练别人训练好的模型的最后一层,其他层参数保持不变,这样做的好处是训练速度快,但性能往往不如从头训练。打开以下github网页,
https://github.com/tensorflow/models/tree/master/research/slim
可以看到提供了以下训练好的模型
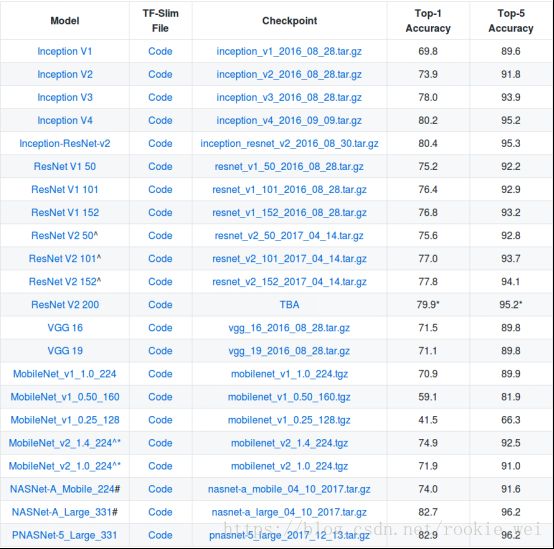
我们下载inception_v3_2016_08_28.tar.gz模型,新建文件夹checkpoint,将下载的文件解压到该文件夹下。在从头训练命令中加入--checkpoint_path=模型路径,即可,先创建保存模型的路径,在执行训练,命令如下,
mkdir -p saver/inv3_checkpoint_flowers
python train_image_classifier.py \
--train_dir=saver/inv3_checkpoint_flowers \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--checkpoint_path=checkpoint/inception_v3.ckpt \
--max_number_of_steps=500 \
--batch_size=5 \
--learning_rate=0.0001 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004
很不幸,又出问题了,错误如下,
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [5] rhs shape= [1001]
[[Node: save/Assign_8 = Assign[T=DT_FLOAT, _class=["loc:@InceptionV3/AuxLogits/Conv2d_2b_1x1/biases"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](InceptionV3/AuxLogits/Conv2d_2b_1x1/biases, save/RestoreV2_8)]]
这是由于我们训练使用的样本的输入和输出尺寸跟下载下来的模型的尺寸不匹配导致的,我们训练的Flowers数据集输出分类数是5,而下载下来的模型用的是ImageNet,输出分类数是1000。但是我们还是想在别人训练好的模型上训练自己的数据怎么办?下面讲的微调的方法就可以解决这个问题。
7.3、微调(Fine-tuning)
所谓微调,就是将原来模型中最后一层去掉,换成我们自己数据集对应的分类层,这个例子中就是将1000个分类换成5个分类。查看README.md文档看看怎么做。从文档中可知,需要用到--checkpoint_exclude_scopes和--trainable_scopes两个参数,--checkpoint_exclude_scopes参数指定载入预训练模型时,哪一层的权重不被载入,--trainable_scopes参数指定哪一层的参数进行训练。
执行以下命令,
python train_image_classifier.py \
--train_dir=saver/inv3_checkpoint_flowers \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--checkpoint_path=checkpoint/inception_v3.ckpt \
--max_number_of_steps=500 \
--batch_size=5 \
--learning_rate=0.0001 \
--learning_rate_decay_type=fixed \
--save_interval_secs=60 \
--save_summaries_secs=60 \
--log_every_n_steps=10 \
--optimizer=rmsprop \
--weight_decay=0.00004 \
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \
--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits
运行结果如下:
INFO:tensorflow:global step 460: loss = 2.3725 (0.123 sec/step)
INFO:tensorflow:global step 470: loss = 2.3369 (0.125 sec/step)
INFO:tensorflow:global step 480: loss = 2.3063 (0.126 sec/step)
INFO:tensorflow:global step 490: loss = 1.9169 (0.123 sec/step)
INFO:tensorflow:global step 500: loss = 1.8042 (0.125 sec/step)
INFO:tensorflow:Stopping Training.
INFO:tensorflow:Finished training! Saving model to disk.
8、评估模型
8.1、评估从头训练模型
执行以下代码开始测试,
python eval_image_classifier.py \
--checkpoint_path=saver/inv3_flowers/ \
--eval_dir=saver/inv3_flowers/ \
--dataset_name=flowers \
--dataset_split_name=validation \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--batch_size=5
运行结果如下:
INFO:tensorflow:Evaluation [7/70]
INFO:tensorflow:Evaluation [14/70]
INFO:tensorflow:Evaluation [21/70]
INFO:tensorflow:Evaluation [28/70]
INFO:tensorflow:Evaluation [35/70]
INFO:tensorflow:Evaluation [42/70]
INFO:tensorflow:Evaluation [49/70]
INFO:tensorflow:Evaluation [56/70]
INFO:tensorflow:Evaluation [63/70]
INFO:tensorflow:Evaluation [70/70]
eval/Recall_5[1]
eval/Accuracy[0.225714281]
INFO:tensorflow:Finished evaluation at 2018-06-10-02:20:49
因为我们训练的时候--max_number_of_steps参数只设置为500,即只训练500步,所以模型得到的准确率比较低,复杂的神经网络依靠大量的训练才行,所以只训练500步的模型肯定不行的。随着训练的次数增多,模型预测的准确率也会提高,这里只是写笔记我就先不进行大量训练,等晚上或者上班时间再留着电脑自己训练吧。
8.2、评估微调模型
执行以下代码开始测试,
python eval_image_classifier.py \
--checkpoint_path=saver/inv3_checkpoint_flowers/ \
--eval_dir=saver/inv3_checkpoint_flowers/ \
--dataset_name=flowers \
--dataset_split_name=validation \
--dataset_dir=images_data/flowers/ \
--model_name=inception_v3 \
--batch_size=5