hadoop ha 高可用搭建
该ha搭建是在hadoop全分布式基础上搭建,关于hadoop全分布式搭建可以参考另一篇hadoop3分布式环境基础搭建。
目录
一、高可用简介
二、配置hadoop
三、zookeeper安装及配置
四、namenode节点信息同步
五、zookeeper格式化、ha启动及测试
一、高可用简介
多个namenode,增加namenode增加可用性。
ha角色分配如下
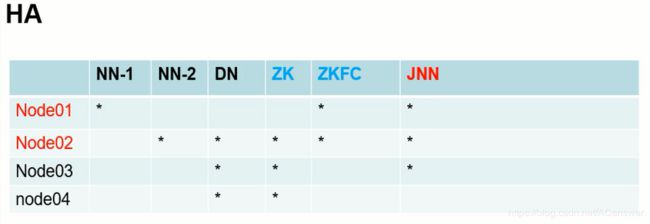
NN:namenode; DN:datanode;
ZK:zookeeper; ZKFC:ZookeeperFailoverController;
JNN:journalnode;
二、配置hadoop
说明:使用时请将#开头的注释删除,因为有的配置文件的注释不为#!
注意:ha高可用搭建是在全分布式基础上搭建的,基本相似,本节只列举了配置中不同的地方。关于全分布式搭建请看这里hadoop3分布式环境基础搭建。
配置hadoop环境变量
vi /myapp/hadoop-3.1.2/etc/hadoop/hadoop-env.sh
在最后一行添加如下内容(JAVA_HOME根据实际JAVA安装路径决定):
export JAVA_HOME=/export/servers/jdk # JAVA_HOME路径,可用echo $JAVA_HOME获得
export HDFS_NAMENODE_USER=root # 为hadoop配置三个角色的用户
export HDFS_DATENODE_USER=root
# export HDFS_SECONDARYNAMEDODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
配置副本放置策略
vi /myapp/hadoop-3.1.2/etc/hadoop/hdfs-site.xml
hdfs-site.xml中configuration标签内容修改如下:
dfs.replication
2
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:9870
dfs.namenode.http-address.mycluster.nn2
node02:9870
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/myapp/hadoop-3.1.2/ha_temp/journalnode
dfs.ha.automatic-failover.enabled
true
配置主节点
vi /myapp/hadoop-3.1.2/etc/hadoop/core-site.xml
core-site.xml中configuration标签内容修改如下:
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/myapp/hadoop-3.1.2/ha_temp
ha.zookeeper.quorum
node02:2181,node03:2181,node04:2181
将配置分发到其他节点
scp core-site.xml hdfs-site.xml hadoop-env.sh root@node02:/myapp/hadoop-3.1.2/etc/hadoop/
scp core-site.xml hdfs-site.xml hadoop-env.sh root@node03:/myapp/hadoop-3.1.2/etc/hadoop/
scp core-site.xml hdfs-site.xml hadoop-env.sh root@node04:/myapp/hadoop-3.1.2/etc/hadoop/
配置从节点
参考全分布式。
三、zookeeper安装及配置
zookeeper要安装到node02、node03、node04上。
采取策略:现在node02上安装配置好,然后分发到node03、node04上去。
解压
tar -xzvf zookeeper-3.4.6.tar.gz -C /myapp/
配置zookeeper环境变量(node02、node03、node04都要做这步)
vi /etc/profile,在末尾添加:
#set zookeeper env
export ZOOKEEPER_HOME=/myapp/zookeeper-3.4.6
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
重新加载环境变量
source /etc/profile
配置zookeeper
1)修改zoo.cfg
将conf目录中zoo_sample.cfg重命名为zoo.cfg,不做这一步可能无法正常启动,命令如下:
mv /myapp/zookeeper-3.4.6/conf/zoo_sample.cfg /myapp/zookeeper-3.4.6/conf/zoo_.cfg
用 vi zoo.cfg 命令修改zoo.cfg文件
将dataDir改为如下,dataDir为zookeeper的临时目录,默认放在系统临时目录/tmp下,容易丢失
dataDir=/myapp/zookeeper-3.4.6/temp
添加如下内容到zoo.cfg末尾,即将zookeeper集群中的所有节点配置,对应关系很重要,配置后不要修改
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
2)将zoo.cfg分发到node03、node04
在hadoop安装目录的上级目录执行下面命令
scp -r zookeeper-3.4.6 root@node03:/myapp/
scp -r zookeeper-3.4.6 root@node04:/myapp/
3)对zookeeper的每台机器配置编号(node02、node03、node04)
创建zookeeper的临时目录,即zoo.cfg中dataDir指定的那个目录
mkdir -p /myapp/zookeeper-3.4.6/temp
在临时目录中创建编号文件,并对应zoo.cfg中配置的编号写入文件
echo 1 > /myapp/zookeeper-3.4.6/temp/myid # node02中
echo 2 > /myapp/zookeeper-3.4.6/temp/myid # node03中
echo 3 > /myapp/zookeeper-3.4.6/temp/myid # node04中
运行zookeeper(node02、node03、node04)
用下面命令启动
zkServer.sh start
查看状态
zkServer.sh status
显示中若为Mode: leader则该节点为主节点,若为Mode: follower则该节点为从节点。
启动zookeeper客户端
zkCli.sh
停止zookeeper
zkServer.sh stop
注意:zookeeper集群只有启动过半节点状态才为启动成功,例如3台集群启动2台以上,5台集群启动3台以上。
四、namenode节点信息同步
node01和node02为namenode,所以这两个节点的信息应该一致。
启动journalnode(node01、node02、node03,由第一节架构图可知)
hdfs --daemon start journalnode
格式化namenode(node01)
hdfs namenode -format
启动namenode(node01上的)
hdfs --daemon start namenode
在node02上输入以下命令将node01的信息同步到node02
hdfs namenode -bootstrapStandby
同步成功后会在/myapp/hadoop-3.1.2/etc/ha_temp/dfs/name/current中有文件。
五、zookeeper格式化、ha启动及测试
格式化zookeeper(node01中)
hdfs zkfc -formatZK
格式化成功后使用“zkCli.sh”进入zookeeper,再使用“ls /”可以看到生成了/hadoop-ha/mycluster目录,里面存放有namenode。
启动ha(node01中)
注意:启动ha之前要先启动zookeeper。
start-dfs.sh
启动后,用jps查看每台机器运行的进程,与第一节图中的一致。
测试
在windows浏览器中输入“192.168.182.140:9870”可以看到node01为activate状态,在浏览器中输入“192.168.182.141:9870”可以看到node02为standby状态。
在node01上用以下命令关闭namenode
hdfs --daemon stop namenode
在浏览器中刷新node02,可以看到状态从standby变为activate,实现了namenode自动切换。