【详解】Python抓取数据脚本
利用Python写抓取数据的脚本,(也就是常说的写爬虫脚本)
要做的就是利用Python找到我们需要的数据。
第一步:访问网页
利用Python我们可以很方便的访问网页,采用urllib2这个包,这个过程会很简便。
#!/usr/bin/python # -*- coding: utf-8 -*- import urllib2 downjoyMainUrl = "http://money.downjoy.com/connectchannel/login.jsp" resp = urllib2.urlopen(downjoyMainUrl) html=resp.read().decode('utf-8').encode('gb2312') print html归纳一下:
1.urllib2.urlopen(url) 就可以访问到网页
2.resp.read()
从字面意思看,利用urllib2的urlopen函数打开链接,然后读取,直接打印就能返回网页的HTML代码了
3.decode('utf-8').encode('gb2312')
编码解码可以显示出中文网页,要访问的网页是utf-8编码,所以decode('utf-8'),然后编码encode('gb2312')就可以显示正常的中文网页了
熟悉了以后我们可以这样写,逻辑更为清晰
html=urllib2.urlopen("http://money.downjoy.com/connectchannel/login.jsp").read().decode('utf-8').encode('gb2312') print html打开、读取,仅此而已!
第二步:模拟登录
我们访问到了网页,但如果不登录,是无法到达包含了数据的网页的,必须要经过登录这一步,所以我们需要利用Python模拟登录。
我们首先需要分析登录的过程,然后才能利用代码模拟登录。
这个网页的登录比较简单,只需要输入用户名和密码就可以登录了。有的网站还需要输入密码,比较麻烦。
我们利用FireFox的F12工具来分析这个过程。

因为登录是具有加密性的操作,所以肯定是post类型的请求。
我们可以在登录过程中的这个POST请求中找到我们刚刚输入的用户名和密码。
这个网站的登录过程其实很清晰,上图中的第一条GET请求对应的URL就是到达登录页面的链接,我们已经获取了这个网页,然后第二条通过POST请求的URL登录。
我们需要明确,登录要用到cookie。
这里需要用到cookielib模块,还有urllib模块。实际上最终我们实现登录,只用到了三个模块
import urllib import urllib2 import cookielib
我们现在虽然对cookie理解不深,但知道登录是肯定需要cookie的。
而在Python中cookielib会自动帮我们处理cookie,不需要我们担心。
#处理cookie cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener)只需要这三行代码。
接下来就是输入用户名和密码
#开始模拟登录,输入用户名和密码 downjoyMainLoginUrl = "http://money.downjoy.com/connectchannel/login.html" postDict = { 'channelId' : "1039", 'password' : "61743265", } #以POST方式提交信息 postData = urllib.urlencode(postDict) req = urllib2.Request(downjoyMainLoginUrl, postData) resp = urllib2.urlopen(req) #加上.decode('utf-8').encode('gb2312')就能够解决中文乱码的问题 html = resp.read().decode('utf-8').encode('gb2312') #返回了网页 print "=========================================================" print html简单归纳一下:
指明url;
定义postDict的字典信息,把用户名密码的登录信息嵌入;
接下来的两行代码,将post请求提交到url,实现登录;
然后打开返回的请求,即登录后的网页;
经过编码解码,我们可以看到返回的HTML就是登录后的网页。
同样把这部分代码简化一下,逻辑会更为清晰:
postDict = { 'channelId' : "1039", 'password' : "61743265cm", } #以POST方式提交信息 postData = urllib.urlencode(postDict) html = urllib2.urlopen(urllib2.Request("http://money.downjoy.com/connectchannel/login.html", postData)).read().decode('utf-8').encode('gb2312') print html
设定用户名密码,提交postdata到url,返回网页
打开、读取、
模拟登录成功!
第三步:找到我们所需要的信息所在的网页
我们要获取目标信息,首先要到达包含了这些信息的网页,然后才能进行提取。
接下来手动查询,然后在F12控制台观察,我们是通过哪个url到达目标网页的。
然后我们发现,到达目标网页的最近一个url就是我们要找的url。
在本例中,我们获得需要的信息,还需要输入查询条件,即要设置时间区间。
而这个url是GET请求,查询条件是用?跟在url后面提交的。
http://money.downjoy.com/connectchannel/list_prompt_new_channel_stat.html?appId=&startDate=2015-10-29&endDate=2015-10-30&pcid=0
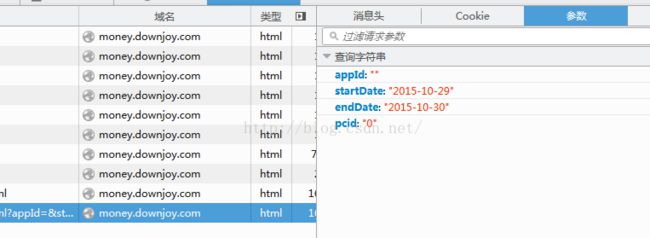
我们发现这个url提交的参数有四个。分析一下这四个参数,
appId为空,pcid为0,这两个一个为空,一个不变,所以都可以忽略。
所以最终需要我们设置的,也是我们正常访问网页时所需要输入的信息,就是时间区间。startDate和endDate。
所以最终接下来的代码这样写:
# 开始查询 downjoyGoChartUrl = "http://money.downjoy.com/connectchannel/list_prompt_new_channel_stat.html?startDate=%s&endDate=%s"%(lastDayDateStr,todayStr ) resp=urllib2.urlopen(downjoyGoChartUrl) html = resp.read().decode('utf-8').encode('gbk') print "========================================================================================================" print html指定url;
urllib2.urlopen()打开链接;
urllib2.urlopen(url).read()读取html内容;
解码编码,得到中文网页。
我们发现打印出来的网页中包含了我们需要的信息,到达目标网页成功!
第四步:提取信息
到达目标网页,这个网页中包含了很多信息,我们只需要提取我们所需要的就可以。
在网页的HTML代码中提取信息,归纳起来有两种方法:
1.正则
2.beautifulsoup
前者比较复杂,我们采用第二种,依赖Python第三方的beautifulsoup包,方便我们更简便的达到目的。
首先导入beautifulsoup包:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser", from_encoding="gbk")然后将html网页赋给一个soup对象。
这个soup对象我们打印出来发现,原来有缩进的网页格式,变成了一行一行的。
接下来我们要分析这一堆HTML元素,想办法定位到目标信息。
这一部分工作最为核心,因为前面的访问网页,模拟登录网页,都是较为死的东西。
而提取信息,是要根据不同的网页来写代码的。
不同的网页,不同的信息,代码都是不同的。提取方式也有很多种。
本例,最终提取到目标信息经历了好几种版本的提取方法,我们先贴出最终版代码:
# data表示td标签的所有内容 data = soup.find_all(name="td", attrs={}, text=re.compile("\S")) print data要提取的是表格信息,我们发现目标信息都是带td标签的,
根据soup的语法,找到所有属性为空的td标签,然后匹配所有非空的。
得到一个data数组,其中包含了所有td标签的字符串。打印data如下:
[
已经很接近了,但是我们最终需要的数据肯定是不能包含
定义一个去标签的方法
# 删除多余的tag标签 def delTag(x): arr = [] for i in range(0, x.__len__()): b = str(x[i]).replace('然后打印', '') c = b.replace(' ', '') arr.append(c) return arr
print delTag(data) 发现td标签都被去掉了。这里注意一点,要先声明方法,然后引用,要将方法放到上面。
然后如何从这些数组中提取我们要的信息呢?
最终我们采取的方法是按数提取,即每一个我们需要的数据在数组中的下标都是有规律的,比如都是4的倍数,都是4的倍数+1之类的。
所以
#抓取数据的数组 gameName=[None]*(data.__len__()/4) date=[None]*(data.__len__()/4) account=[None]*(data.__len__()/4) times=[None]*(data.__len__()/4) for i in range(gameName.__len__()): gameName[i]=data[i*4+1].decode('utf-8').encode('gbk') for i in range(date.__len__()): date[i]=data[i*4+2].decode('utf-8').encode('gbk') for i in range(account.__len__()): account[i]=data[i*4+3].decode('utf-8').encode('gbk') for i in range(times.__len__()): times[i]=data[(i+1)*4].decode('utf-8').encode('gbk')新建4个数组,循环遍历,将对应数据写入!
注意:Python中新建指定大小的数组,这样定义:
gameName=[None]*(8)表示新建一个长度为8的数组。
声明,这里的编码解码是为了后续写入文件不乱码!
到这里,我们将需要的数据提取出来并按类型放入了4个不同的数组中,
目的达成!
第五步:写入csv文件中
我们运行爬虫脚本,必然要将数据输出到某地。这里我们把数据写入一个csv文件中,因为Python对excel的支持并不好,所以使用csv。
导入csv包,定义写入csv的方法。
import csv
def writeCsv(x): with open('tttest.csv', 'ab+') as csvfile: writer = csv.writer(csvfile, dialect='excel') writer.writerow(x)这部分代码也比较死。注意几点即可:
1.
with open('tttest.csv', 'ab+') as csvfile:其中的两个字符串,前者是文件名,后者是模式:
a+表示追加,b表示文件模式,
a+还可以改为w,表示写入模式,这样每次写入都会替换原来的内容,坏处就是不能遍历写入内容。
所以我们这里采用追加模式
2.
写入一行用writerow,写入多行用writerows
写入内容之前,我们要打印表头
# 打印表头 def writeHeader(): writeCsv(["账号".decode('utf-8').encode('gbk'), "用户名".decode('utf-8').encode('gbk'), "密码".decode('utf-8').encode('gbk'), "应用名称".decode('utf-8').encode('gbk'), "日期".decode('utf-8').encode('gbk'), "充值金额".decode('utf-8').encode('gbk'), "用户付费次数".decode('utf-8').encode('gbk')])然后写入内容:
writeCsv(gameName) writeCsv(date) writeCsv(account) writeCsv(times)成功写入。
第六步:实现按列写入
这里我们成功将数据提取并写入到了csv文件中,写入方式是按行写入。
csv的写入方式只有两种,writerow和writerows都是行写入的方式。
如果我们要按列写入应该怎么做呢?
基本思想是,将数组拆开,赋给新的数组,通过按行写入的方式,达到按列写入的效果。
归根结底,还是按行写入,但是实现了按列写入一样的效果。
具体实现代码如下:
# 实现按列写入 rowNum = gameName.__len__() columnNum = 4 chartData = [None]*rowNum for i in range(0, len(chartData)): chartData[i] = [None]*columnNum for i in range(0, gameName.__len__()): chartData[i] = [gameName[i], date[i], account[i], times[i]] writeCsv(chartData[i])
我们首先新建一个n行4列的数组。
再通过遍历,将每个现有数组每个下标相同的元素按顺序写入一个新的二维数组中。
然后把这个新数组按行写入,就达到了按列写入的效果。
经过测试,的确可行。
第七步:从excel文件读取用户名密码,实现遍历登录
我们现有一张excel表,里面都是用户名和密码,我们可以通过读取文件,提取用户名密码,然后实现遍历登录。
这样可以自动抓取很多数据。
如何读取excel文件中的数据?
具体代码实现如下:
导入xlrd包
import xlrd 读取对应文件
# 提取用户名和密码 xlsfile = r'read.xlsx' book = xlrd.open_workbook(xlsfile) sheet = book.sheet_by_index(0) nrows = sheet.nrows # 遍历登录 for i in range(1, nrows): id=int(math.floor(sheet.cell_value(i, 0))) username=sheet.cell_value(i, 1) password=sheet.cell_value(i, 2) print id # 开始登录 downjoyMainLoginUrl = "http://money.downjoy.com/connectchannel/login.html" postDict = { 'channelId' :id, 'password' : password, }先读取文件,然后遍历取出对应值,然后遍历登录!
这样就可以实现遍历抓取信息了。
需要注意一点:我们要遍历登录时,每次都需要退出操作,因为如果不退出,原来的数据会继续写到下一个没有数据的用户。
# 退出登录 downjoyMainLogoutUrl ="http://money.downjoy.com/connectchannel/logout.html" resp=urllib2.urlopen(downjoyMainLogoutUrl)
至此,我们成功拿到了所有我们需要的数据并写入了csv文件。
第八步:发送邮件
利用Python我们可以方便的发送邮件。我们这里发送两种:
1. 发送给单人,包含邮件正文、附件
2. 发送给多人,即群发,包含邮件正文、附件
这里贴出代码,算是比较死的东西,以作参考。
# 发送邮件 def sendEmail(): # 创建一个带附件的实例 msg = MIMEMultipart() # 构造附件1 att1 = MIMEText(open('downjoyBackendData_'+lastDayDateStr+'.csv', 'rb').read(), 'base64', 'gb2312') att1["Content-Type"] = 'application/octet-stream' # fileName以数据加日期命名 fileName="数据".decode('utf-8').encode('gbk')+todayStr+".csv" att1["Content-Disposition"] = 'attachment; filename=%s'%fileName msg.attach(att1) # 写入邮件正文 text="数据见附件,如有问题,请联系我" # 邮件正文乱码,所以在这里指定编码 part1 = MIMEText(text, 'plain', _charset='utf-8') msg.attach(part1) # 加邮件头 strTo = ['[email protected]', '[email protected]'] msg['to'] = ','.join(strTo) msg["from"] = '[email protected]' msg['subject'] = '每日数据_'.decode('utf-8')+todayStr # 发送邮件 try: server = smtplib.SMTP() # QQ邮箱测试时 # server.connect('smtp.qq.com') # 数据中心测试时 server.connect('smtp.qq.com') # 用户名,密码 server.login('[email protected]', 'pwd') server.sendmail(msg['from'], strTo, msg.as_string()) server.quit() print '发送成功'.decode("utf-8") except Exception, e: print str(e)以上为群发邮件,群发地址放在strTo中
# 发送邮件 def sendEmail(): # 创建一个带附件的实例 msg = MIMEMultipart() # 构造附件1 att1 = MIMEText(open('BackendData.csv', 'rb').read(), 'base64', 'gb2312') att1["Content-Type"] = 'application/octet-stream' # fileName以数据加日期命名 fileName="数据".decode('utf-8').encode('gbk')+todayStr+".csv" att1["Content-Disposition"] = 'attachment; filename=%s'%fileName msg.attach(att1) # 写入邮件正文 text="数据见附件,如有问题,请联系我" # 邮件正文乱码,所以在这里指定编码 part1 = MIMEText(text, 'plain', _charset='utf-8') msg.attach(part1) # 加邮件头 msg['to'] = '[email protected]' msg["from"] = '[email protected]' msg['subject'] = '每日数据_'.decode('utf-8')+todayStr # 发送邮件 try: server = smtplib.SMTP() # QQ邮箱测试时 # server.connect('smtp.qq.com') # 数据中心测试时 server.connect('mail.chuan-mei.com') # 用户名,密码 server.login('[email protected]', 'pwd') server.sendmail(msg['from'], msg['to'], msg.as_string()) server.quit() print '发送成功'.decode("utf-8") except Exception, e: print str(e)以上为发送数据给单人,发送地址放在msg['to']中
发送给多人和单人的代码有两处不同,还有一处:
server.sendmail(msg['from'], strTo, msg.as_string())
server.sendmail(msg['from'], msg['to'], msg.as_string())就是发送地址所放的地方。
这里我们可以发现群发邮件时的bug,虽然也出现了msg['to'],但是却没有在sendmail函数中出现,出现的却是strTo。
虽如此,删掉msg['to']也是不行的。死记住就好了!
到这里我们的爬虫脚本就算写完了!OVER!