spark2.1.0配置windows本地基于java语言的Eclipse开发环境
前面配置过在windows本地通过Eclipse开发hadoop程序然后打成jar包在Linux集群中运行的经历,因此一方面是基于同样的需求,另一方面是因为我是spark小白,想通过这种方式快速了解和学习spark开发。
(注意:此文配置的是基于java语言开发spark的,如果要用scala开发,则需要在Eclipse中添加scala插件并做进一步配置。如果要用python开发,则最好用pycharm)
软件环境介绍
首先,需要在windows本地安装hadoop、spark、jdk、scala、maven、Eclipse。
| Hadoop | 2.7.5 | http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/ |
| Spark | 2.1.0 | http://spark.apache.org/downloads.html |
| JDK | 1.8.0 | https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html |
| Scala | 2.11.0 | http://distfiles.macports.org/scala2.11/ |
| Maven | 3.5.4 | http://maven.apache.org/docs/history.html |
| Eclipse | Mars.2 (4.5.2) | http://www.eclipse.org/downloads/packages/release/Mars/2 |
| winutils&hadoop.dll | https://github.com/srccodes/hadoop-common-2.2.0-bin |
首先安装jdk,这里不做介绍了。
一、Hadoop安装
下载压缩文件后解压到某个目录下,我的是在F:\MySoftware下,解压后会得到一个hadoop-2.7.5文件夹,结果如下:

然后配置hadoop的环境变量HADOOP_HOME,并在path中加入%HADOOP_HOME%\bin。

然后在cmd中输入hadoop -version查看版本信息,证明是否安装成功

最后还有一步!将下载下来的winutils.exe和hadoop.dll复制到%HADOOP_HOME%\bin目录下即可完成hadoop安装配置。(如果没有这两个文件的话,运行spark程序的时候会报错,但奇怪的是,我的报错了但仍然可以运行得到结果。。。)

二、Scala安装
下载解压scala压缩文件,得到一个scala-2.11.0文件夹,文件目录结果如下:
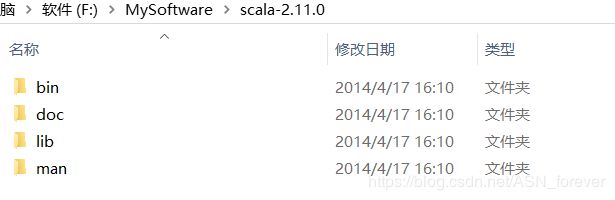
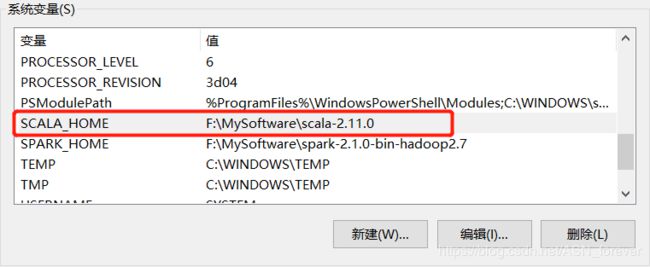
然后配置 SCALA_HOME系统变量,并在path中加入%SCALA_HOME%\bin
然后在cmd中输入scala -version查看是否安装成功。

三、Spark安装
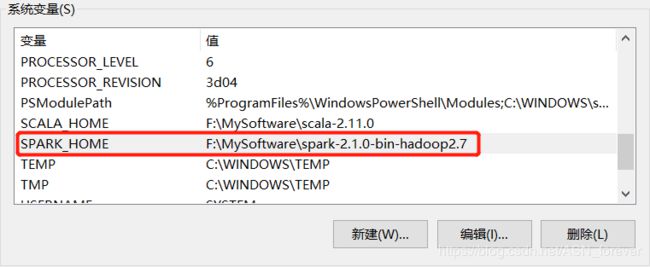
首先将下载的spark压缩包解压到某个目录下,我的是放在F:\MySoftware\下,解压后会生成一个名为spark-2.1.0-bin-hadoop2.7的文件夹,文件结构如下:

然后配置spark的环境变量SPARK_HOME,并在path中加入%SPARK_HOME%\bin。
此后在cmd中输入spark-shell查看是否安装成功(此时可能会显示一些警告信息,一般不会影响,如果看着不舒服也可以配置)

(注意,因为没有在windows本地搭建hadoop集群和spark集群,只是想在本地能够开发spark程序,真正的运行是在Linux集群上的,因此没有配置spark.env.sh等文件)
四、Eclipse下载和配置maven
Eclipse的安装在这里不做介绍了,相信大家都安装过。没安装的可以看这里。
主要需要说的是maven的配置。
首先下载maven压缩文件后解压得到一个名为apache-maven-3.5.4的文件夹,文件目录结构如下:

与前面安装hadoop之类的类似,也需要添加系统变量及path。。。

在cmd中输入mvn -v查看是否安装成功

接下来要在Eclipse中配置maven。
在Eclipse中点击window-->preference进入如下界面:
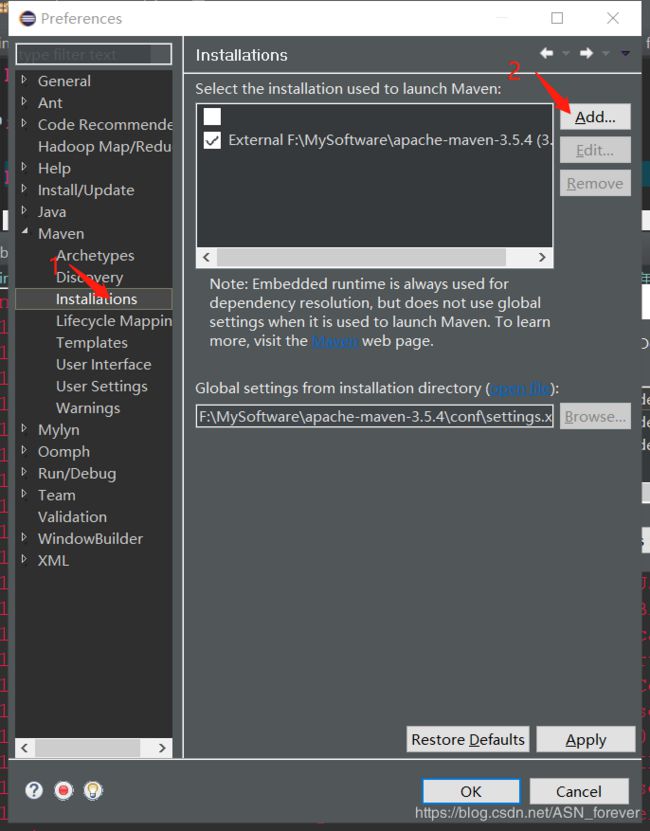

现在就已经将maven安装到Eclipse中了。但是还需要配置本地仓库。因为maven是一个方便我们管理jar包的工具,我们需要的jar包都是从中央仓库下载到本地的,但是如果本地不做保存,以后用到相同的jar包时还需要到中央仓库下载,就会很麻烦。因此需要配置本地仓库,这样下载后的jar包就放到本地仓库,方便以后使用。
配置本地仓库:
找到maven安装目录下的conf文件夹下的settings.xml文件,编辑其localRepository属性。
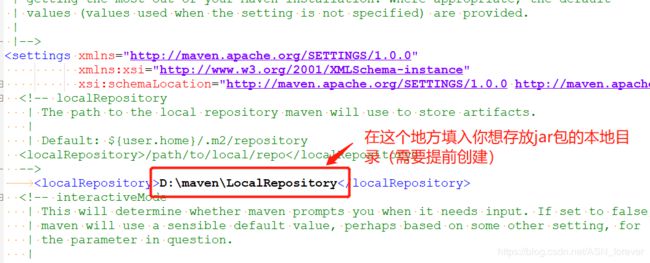
然后再次点击Eclipse中的window-->preferences,进入如下界面,并点击browser选择刚刚配置的那个settings.xml文件,然后下面就会自动显示你配置的本地仓库路径,最后点击应用即可。
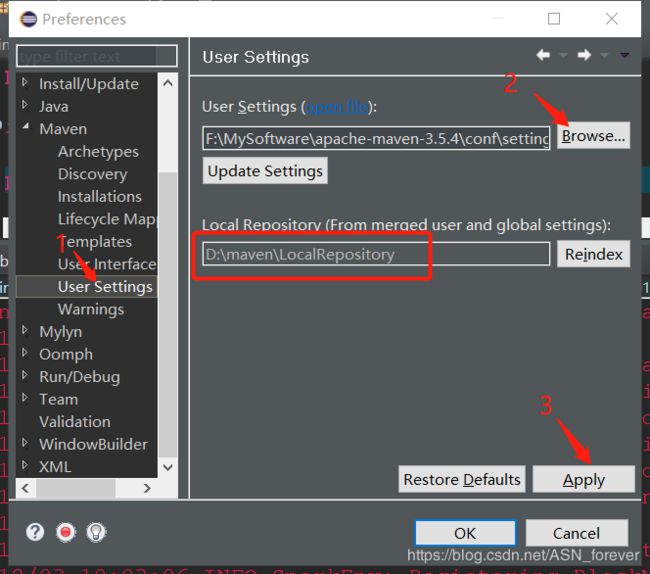
这样就完成了Eclipse中的maven的配置。 接下来就在Eclipse中开始开发第一个spark程序。
五、开发spark
1.创建maven项目

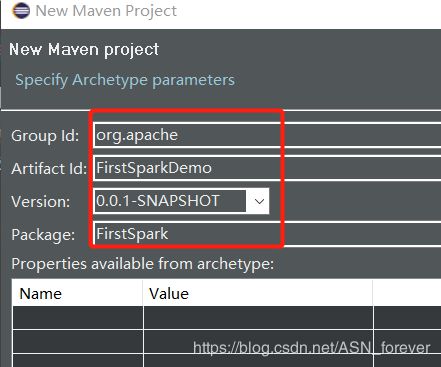
点击finish后就会生成一个FirstSparkDemo的maven项目,结果如下:
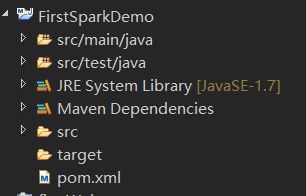
接下来要配置pom.xml文件,让它帮忙下载一些spark开发所需要的jar文件。用以下内容替换掉
central
Central Repository
http://maven.aliyun.com/nexus/content/repositories/central
default
false
UTF-8
1.7
1.7
2.1.0
2.11.0
2.7.5
junit
junit
4.11
test
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-hive_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.hadoop
hadoop-client
2.7.0
junit
junit
4.12
org.slf4j
slf4j-api
1.6.6
org.slf4j
slf4j-log4j12
1.6.6
log4j
log4j
1.2.16
dom4j
dom4j
1.6.1
jaxen
jaxen
1.1.6
args4j
args4j
2.33
jline
jline
2.14.5
maven-clean-plugin
3.0.0
maven-resources-plugin
3.0.2
maven-compiler-plugin
3.7.0
maven-surefire-plugin
2.20.1
maven-jar-plugin
3.0.2
maven-install-plugin
2.5.2
maven-deploy-plugin
2.8.2
maven-assembly-plugin
2.2
code.demo.spark.JavaWordCount
jar-with-dependencies
接下来在src/main/java下创建类,开始编程。
package FirstSpark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import java.util.ArrayList;
import java.util.List;
public final class FirstSparkDemo {
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("JavaSparkPi").setMaster("local");//local是特殊值,可以让spark运行在单机单线程上而无需连接到集群
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
long start = System.currentTimeMillis();
int slices = 10;
int n = 100000 * slices;
List l = new ArrayList(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
/*
* JavaSparkContext的parallelize:将一个集合变成一个RDD - 第一个参数一是一个 Seq集合 -
* 第二个参数是分区数 - 返回的是RDD[T]
*/
JavaRDD dataSet = jsc.parallelize(l, slices);
int count = dataSet.map(new Function() {
private static final long serialVersionUID = 1L;
public Integer call(Integer integer) {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y < 1) ? 1 : 0;
}
}).reduce(new Function2() {
private static final long serialVersionUID = 1L;
public Integer call(Integer integer, Integer integer2) {
return integer + integer2;
}
});
long end = System.currentTimeMillis();
System.out.println("Pi is roughly " + 4.0 * count / n + ",use : " + (end - start) + "ms");
jsc.stop();
jsc.close();
}
}
运行后有如下输出则说明配置成功。

参考博文:
https://blog.csdn.net/qq_32653877/article/details/81979371
https://my.oschina.net/orrin/blog/1812035
https://blog.csdn.net/nxw_tsp/article/details/78281533(这是一个配置windows本地spark集群的博文)