Ubuntu系统的基本使用(一)
学习RL的原因,需要与新的系统进行磨合。总结一下最近看到的学习资料。
1.ubuntu的基本操作指令
Linux系统基础教程 记录一些基本的操作
(1)
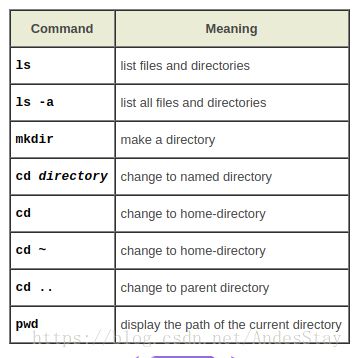
ls(list) 罗列出当前文件夹下的文件,但是不包括(.后缀)的隐藏文件。
ls -a (all) 可罗列出所有文件,包括隐藏文件。隐藏文件一般是重要的系统文件,不建议新手改动
mkdir (make directory) 在当前工作区域内创建文件夹
cd (change directory) 进入某一个文件夹,默认进入/回到home
. 每一个文件夹下都有,表示当前文件夹,如 cd . 会继续在当前文件夹下
.. 每一个文件夹下都有,表示当前文件夹的上一层文件夹,如在Music下键入 cd .. 会进入home
pwd(print work directory) 打印当前工作区文件路径
关于文件路径, 在当前工作区域下,可直接利用cd 或者ls对该文件下的子文件进行操作,但若要对子文件下的文件作进一步操作,需输入完整的文件路径
~(your home directory) 代表home文件夹;Ubuntu的终端,起始的,命令窗口为~$,即表示默认在home下操作
(2)
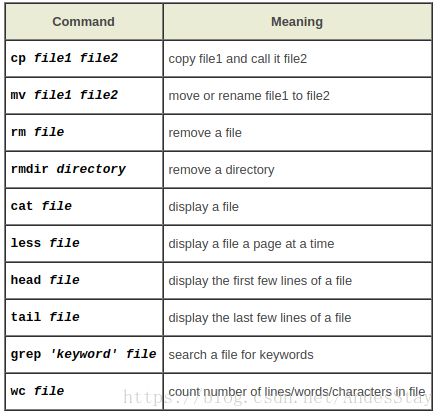
cp file1 file2(copy) 把file1复制到file2,如果不在一个文件夹需要带路径
mv file1 file2(move) 把file1移动并改名为file2,注意带路径,也可在同一文件夹下做重命名用
rm(remove) 删除文件,注意路径
rmdir(remove directory) 删除文件夹,注意路径
clear(clear screen) 清除终端屏幕
cat(concatenate) cat science.txt 在终端显示文件science.txt中的全部内容,存在滚屏
less less science.txt 在终端分屏显示science.txt中的内容,通过上下键、q键翻页或退出
less science.txt /science 可以查找文档中的全部science单词,通过n键移至下一处
head 显示文件的前几行内容,head -5 science.txt显示前5行,默认前10行
tail 显示文件的后几行内容,tail -5 science.txt显示后5行
grep science science.txt 打印输出science.txt中每一行包括science的内容,grep语句区分大小写,-i 可以ignore大小写
grep -i 'spinning top' science.txt 打印输出science.txt中每一行包括'spinning top'的内容,不区分大小写
其他命令选项 -i 不区分大小写
-v 按行打印输出所有不包含搜索项的内容
-n 在输出的行前标出行号(文件中的第几行)
-c 只输出包含搜索项的行的数量总和
wc(word count) 计算文档中的数量 wc -w science.txt 输出单词数量综合;wc -l science 输出行数总和
(3) ?
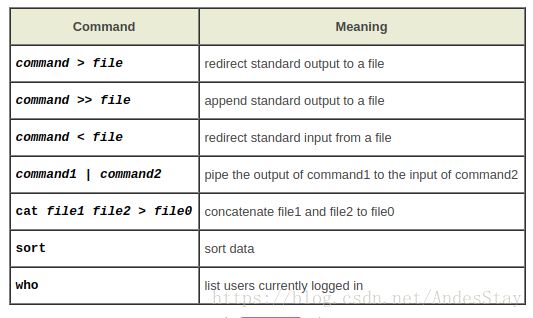
cat > list1 重定向输出为list1,编辑完成后(ctrl+d)退出并保存
cat >> list1 在list1中加入其他内容
cat list1 list2 > biglist 将list1和list2中的内容合并到biglist
sort 重定向输入,编辑完成后(ctrl+d)退出
sort < biglist 把输入与输出对应起来么?
sort < biglist > slist 储存在slist中
who 查看系统的用户
who > names.txt sort < names.txt 得到一个储存所有用户的文件
who | sort 输出所有用户
who | wc -l 输出所有用户数量
练习:输出list1和list2中包括p的所有行,并将结果分类
cat list1 list2 | grep p | sort
2.关于ubuntu系统,注意到的内容,自己不是完全明白,以后慢慢熟悉吧。
linux系统导论-发行版本 ubuntu系统安装
(1)Linux的各种发行版本

(2)Linux的分区布局
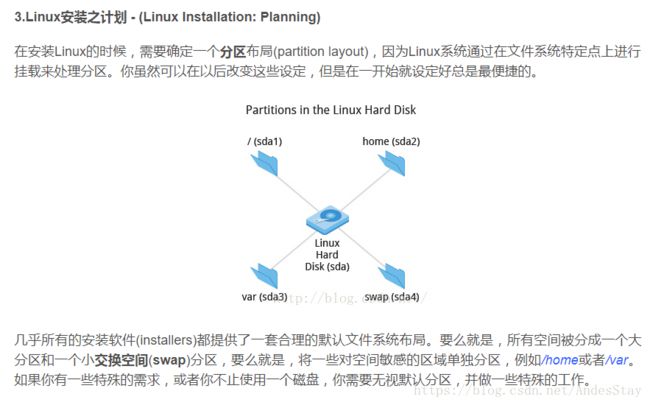
可以对照系统安装过程中的分区来看
(原文)现在我们来对Ubuntu进行分区,在分区之前我先介绍一下Linux的文件系统
swap:用作虚拟内存,这个一般和自己的物理内存一般大
/:主要用来存放Linux系统文件
/boot:存放linux内核,用来引导系统的,如果是Legacy启动就要设置引导,UEFI就不用设置这个(UEFI要设置EFI文件)
/usr:存放用户程序,一般在/usr/bin中存放发行版提供的程序,用户自行安装的程序默认安装到/usr/local/bin中
/home:存放用户文件