机器学习笔记09:支持向量机(二)-核函数(Kernels)
核函数是 SVM 的最重要的部分,我们可以通过设置不同的核函数来创造出非常复杂的、非线性的支持向量机。
1.核(Kernel)
首先来看看什么是核函数。如图所示,假设有一个样本 x 有两个特征 x1,x2 ,我们可以根据与地标(landmarks) l(1),l(2),l(3) 的接近程度(proximity),或者说相似性(similarity),来产生新的更多的特征 ,假如我们有如下三个地标,注意地标的维数和特征的维数是相同的(后面会解释什么是地标,以及地标是怎么产生的):
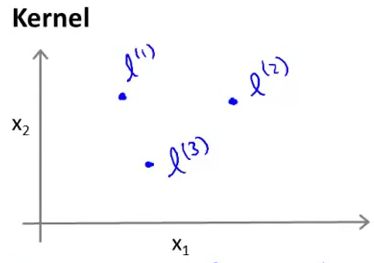
在这里,我们定义新特征 f1,f2,f3 为:
为了看得清楚点,我们用 exp(x) 来表示 e 的 x 次方:
上面的这个 exp(−‖x−l(i)‖22σ2) 即是一个核函数,这个核函数叫做 高斯核(Gaussian Kernel)。高斯核有一个重要的参数 σ ,后面会讲到它的性质和用处。
2.核与相似性(Kernels ans Similarity)
我们已经知道,对于一组地标(landmarks),我们定义输入 x 与 地标 l(i) 的相似性为:
所以有:
| When | exp(−‖x−l(i)‖22σ2) |
|---|---|
| x≈l(i) 时 | 有 exp(−022σ2)≈1 |
| x 和 l(i) 离得很远时 | 有 exp(−largenumber22σ2)≈0 |
下面再来看看核函数的参数 σ 。
2.核函数的参数(Parameter sigma)
上面提到了,核函数的参数是 σ 。我们通过几张图来一览它的性质。假设有一个地标 l1=[35] ,样本 x=[x1x2] 。
1)当 σ2=1 时,有:
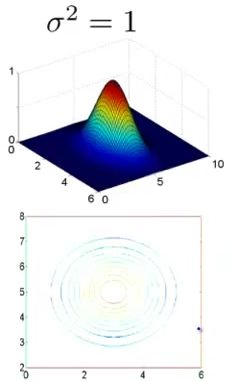
上面有两幅图,上面的是函数 f1=exp(−‖x−l(1)‖22σ2) 的函数图像,下面为对应的等高线密度图像。
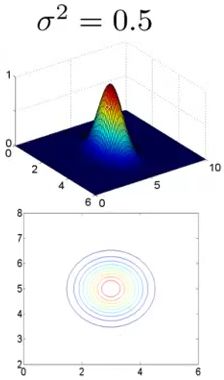
2)当 σ2=0.5 时,有:
3)当 σ2=3 时,有:
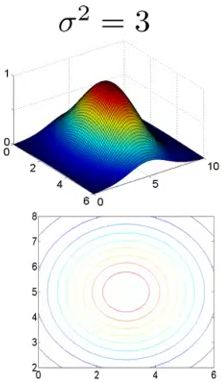
从上面三幅图可以很清楚地知道了,当 σ 比较小的时候,随着 x 的变化,新特征 f 的变化会非常剧烈,当 σ 比较大的时候,随着 x 的变化,新特征 f 的变化会比较平缓。
3.预测演示
说了这么多,下面我们来演示一下采用高斯核的支持向量机是如何对输入进行预测的。假设我们有如下三个地标 l(1),l(2),l(3)
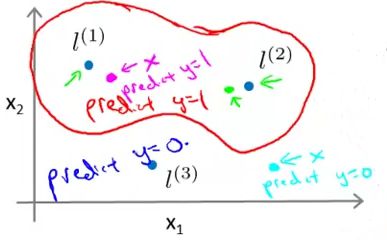
因为是预测,所以假设我们已经得到了参数 θ0=−0.5,θ1=1,θ2=1,θ3=0 。回忆一下,当假设函数 hθ(x)=θ0+θ1f1+θ2f2+θ3f3≥0 时,我们的预测值为 1 。现在我们的假设函数为:
| 举如下两种情况为例: |
|---|
| 如上图,当输入 x (图中紫色的点)非常接近 l(1) 时, x 离 l(2) 和 l(3) 都比较远,我们有 f1≈1,f2≈0,f3≈0 。所以预测值 hθ(x)≈−0.5+1+0+0=0.5≥0 ,所以预测为1。 |
| 当输入 x (图中天蓝色的点)离 l(1),l(2),l(3) 都比较远时,我们有 f1≈f2≈f3≈0 。所以预测值 hθ(x)≈−0.5+0+0+0=−0.5<0 ,所以预测为0。 |
| 注意:输入 x 与地标的距离对输出产生的影响由核函数的参数 σ 决定,例如当 σ 较小时,只有离地标非常近的 x 才会被预测为1。 |
通过上面这个例子我们知道,对于一个支持向量机,当输入 x 比较接近地标时,支持向量机为对该输入预测为1,否则预测为0。同时,我们可以选取较多的地标,将维数较低的特征映射到维数较高的特征上,以此达到对线性不可分的样本进行分类的功能。
4.选择地标(Choosing Landmarks)
上面我们一直将 landmarks 当作已知量,现在我们就来看看如何选择 landmarks。通常,如果训练集为 {(x(1),y(1)),(x(2),y(2)),...,(x(n),y(n))} ,我们选择 l={l(1)=x(1),l(2)=x(2),...,l(n)=x(m)} 作为 landmarks,其中 m 表示样本的数量,这里一共有 m 个 landmarks。所以对于一个给定的样本 (x(i),y(i)) ,我们可以把输入的特征值映射到特征 f 上:
所在使用高斯核的时候,我们首先要做的就是根据输入 x 计算新特征 f∈Rm+1 。
5.SVM的参数
带高斯核的 SVM 有两个参数 C 和 σ2 。
对于 C=1λ ,就像逻辑回归中的 λ 一样能控制过拟合与欠拟合之前的平衡。有如下性质:
| Cases | Effect |
|---|---|
| Large C | Lower bias, higher variance |
| Small C | Higher bias, lower variance |
对于 σ2 ,参考上面的第二节。有如下性质:
| Cases | Effect |
|---|---|
| Large σ2 | Higher bias, lower variance |
| Small σ2 | Lower bias, higher variance |
6.使用SVM
使用 SVM 时我们可以直接调用现成的库,比如一个很不错的 SVM 库: libsvm,其官网地址为:http://www.csie.ntu.edu.tw/~cjlin/libsvm/
因为训练 SVM 涉及到 凸二次优化 以及一些数值计算技巧,所以非常不推荐自己写代码来训练 SVM,因为很多前辈花了数十年才把 SVM 优化到现在这个复杂度任然很高的程度,所以自己花时间写是非常不明智的。但是我们可以在开源库中去阅读 SVM 的训练代码来提高我们对 SVM 的认知程度。
虽然不用自己写代码训练,但是我们也要设定参数 C 和 σ ,同时,我们也要自己写核函数,还有很重要的一点就是需要做 Feature Scaling。
以上就是 SVM 的核函数的大概内容,希望能帮助到大家。如有错误的地方,还请不吝留言指正。