K邻近算法
k邻近算法的工作原理:
训练样本集中每个数据都存在标签,即我们知道样本中每一数据与所属分类的关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
通过算法提取样本中特征值最相似数据分类的标签,一般只选择数据集中前k个最相似的数据
K邻近算法的一般流程:
- 收集数据:anyway
- 准备数据:距离计算所需要的数值
- 分析数据:any mothod
- 训练算法:此步不适用于k邻近
- 测试算法:计算错误率
- 使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理
---KNN.py---
from numpy import *
import operator
def createDataSet():#创建数据集
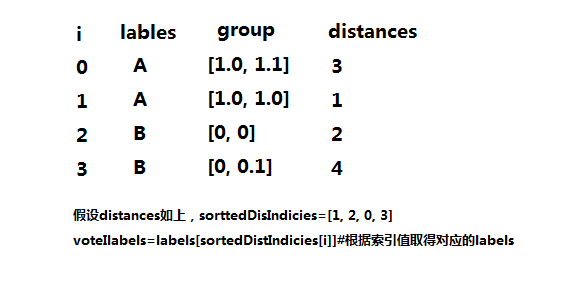
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet#矩阵
sqDiffMat=diffMat**2#矩阵的平方
sqDistances=sqDiffMat.sum(axis=1)#求得矩阵的每一行之和,也就是欧式距离的平方
distances=sqDistances**0.5#欧氏距离
sortedDistIndicies=distances.argsort()#从小到大排序,返回元素的索引值
classCount={}
for i in range(k):
voteIlabels=labels[sortedDistIndicies[i]]
classCount[voteIlabels]=classCount.get(voteIlabels,0)+1#统计voteIlabels出现的次数
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1), reverse=True)#从大到小,返回出现频率最高的
#python2.:dict.iteritems() python3.:dict.items()
return sortedClassCount[0][0]Return the shape of an array.
Parameters
----------
a : array_like
Input array.
Returns
-------
shape : tuple of ints
The elements of the shape tuple give the lengths of the
corresponding array dimensions.
a.shape[0]#返回a的行大小
a.shape[1]#返回a的列大小
shape(a)#返回[col,row]
2.title(A,reps)#Construct an array by repeating A the number of times given by reps.
Parameters
----------
A : array_like
The input array.
reps : array_like
The number of repetitions of `A` along each axis.
Returns
-------
c : ndarray
The tiled output array.
a = np.array([0, 1, 2])
>>> np.tile(a, 2)#将a在x轴方向复制两次
array([0, 1, 2, 0, 1, 2])
inX=[0,0]
diff=tile(inX,(3,2))
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
array([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]])
>>> np.tile(a, (2, 1, 2))
array([[[0, 1, 2, 0, 1, 2]],
[[0, 1, 2, 0, 1, 2]]])
3.argsort(a, axis=-1, kind='quicksort', order=None)#Returns the indices that would sort an array.
Parameters
----------
a : array_like
Array to sort.
axis : int or None, optional
Axis along which to sort. The default is -1 (the last axis). If None,
the flattened array is used.
kind : {'quicksort', 'mergesort', 'heapsort'}, optional
Sorting algorithm.
order : str or list of str, optional
When `a` is an array with fields defined, this argument specifies
which fields to compare first, second, etc. A single field can
be specified as a string, and not all fields need be specified,
but unspecified fields will still be used, in the order in which
they come up in the dtype, to break ties.
Returns
-------
index_array : ndarray, int
Array of indices that sort `a` along the specified axis.
If `a` is one-dimensional, ``a[index_array]`` yields a sorted `a`.
n=array([3,4,1,2,5])
n.argsort()
Out[64]: array([2, 3, 0, 1, 4], dtype=int64)
4.dict.get(key, default=None)
key -- 字典中要查找的键。
default -- 如果指定键的值不存在时,返回该默认值值
准备数据:从文本文件中解析数据
def file2matrix(filename,dim):
fr=open(filename)
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines)
returnMat=zeros((numberOfLines,dim))#
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip()#截取掉所有的回车字符
listFromLine=line.split('\t')
returnMat[index, : ]=listFromLine[0:dim]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector分析数据:Matplotlib创建散点图
import matplotlib
import numpy as np
import KNN
import matplotlib.pyplot as plt
fig=plt.figure()#产生一个空的窗口,可以通过.gcf()获取当前figure的引用。
ax=fig.add_subplot(111)#add_subplot(x,y)可以产生x*y个子窗口 add_subplot(111)将figure()分割成1行1列并且在第一块上
datingDataMat,datingLables=KNN.file2matrix('datingDataMat.txt',3)
#scatter()描绘散点图,默认是形状是圈 scatter(x,y)-2D scatter(x,y,z)-3D
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*np.array(datingLables),15.0*np.array(datingLables))
plt.show()#显示准备数据:归一化数值
---将不同权重的特征值同等化(大家都差不多)
#根据特征权重将特征归一化 newValue=(oldValue-min)/(max-min),将数字特征值化到0-1的区间
def autoNorm(dataSet):
minVals=dataSet.min(0)#返回列最小,将每列的最小值存放之中minVals=[,x,y,z]
maxVals=dataSet.max(0)#返回列最大,将各列的最大值选出并组成maxvals=[x,y,z]
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]#dataSet的总行数
normDataSet=dataSet-tile(minVals,(m,1))#1000*3的矩阵,每行数据都是原始数据-各列最小值组成的minVals
normDataSet=normDataSet/tile(ranges,(m,1))#具体特征值相除
return normDataSet,ranges,minVals测试算法:作为完整程序验证分类器
#利用autoNorm得到的取值范围和最小值归一化测试数据
def datingClassTest():
hoRatio =0.1
datingDataMat,datingLables=file2matrix('datingDataMat.txt',3)
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]#normMat:1000*3
numTestVecs=int(m*hoRatio)#选取10%的测试数据
errorCount=0.0
for i in range(numTestVecs):
#分类器
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],\
datingLables[numTestVecs:m],3)
print("the classifier came back with: %d,the real answer is: %d"\
%(classifierResult,datingLables[i]))#分类后的结果,原结果
if(classifierResult!=datingLables[i]):
errorCount+=1
print("the total error rate is:%f"%(errorCount/float(numTestVecs)))使用算法:构建完整的可用系统
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(input("percentage of time spent palying video games?"))
ffMiles=float(input("frequently flier miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLables=file2matrix('datingDataMat.txt',3)
normMat,ranges,minVals=autoNorm(datingDataMat)
intArr=array([ffMiles,percentTats,iceCream])
classifierResult=classify0((intArr-minVals)/ranges,normMat,datingLables,3)
print("you will like this person",resultList[classifierResult-1])