Spark ML Pipelines
提供基于DataFrames的API构建机器学习Pipelines. 主要为了方便将多个算法可以方便地加载到一个工作流或者处理管道中。
有几个基本的概念:
数据帧DataFrame
用做于ML 数据集,可以包含多种数据类型,参见Spark SQL 数据类型,同时可以使用ML向量(vector)类型
ML向量由包含整数类型、0开始的索引以及双精度数据组成,其中又分稠密向量(dense)和稀疏(sparse)向量两种,稠密向量由双精度数组组成,稀疏向量由两个平行数组组成分别定义索引和值,比如向量(1.0,0.0,3.0)以稠密向量表示为:[1.0,0.0,3.0],以稀疏向量表示为:(3,[0,2],[1.0,3.0]),其中3为向量大小有三个元素,[0,2]数据的位置,[1.0,3.0]在前面数据位置上对应的数据,在位置1上的数据为0,则不需要显示。
DataFrame可以从RDD创建,代码参见Spark SQL programming guide
在DataFrame中的列可被命名,比如下面提到的"文本text","特征features","标签label"
转化Transformers
Transformer是一个抽象的概念,包含特征转化(feature transformers)和学习模型(learned models)。技术上来说Transformer实现了transform()方法,将一个DataFrame转化为另一个DataFrame,一般是添加一个或多个列。比如:
特征转化器获取一个DataFrame,读取其中的一列(比如是一段文本),映射到一个新的列(比如叫做特征向量),输出到一个新的DataFrame包含这个新的特征向量列。
学习模型获取这个DataFrame,读取列包含特征向量、为每个特征向量生成预测标签,产出一个新的DataFrame其中包含预测标签列。
评估Estimator:
Estimator也是一个抽象的概念,指学习算法或者其他的算法对数据进行fits或者训练。技术上来说Estimator实现了fit()方法,接收一个DataFrame,生产出一个Model,也就是上面的Transformer。比如:
学习算法LogisticRegression就是一个评估器Estimator,它调用fit()方法训练出LogisticRegressionModel,他是一个模型也就是上面说的转化单元Transformer。
通道Pipeline:
Pipeline连接了多个转化和评估,用于构建机器学习工作流。
以文本处理过程为例,文本处理包括:
- 将文本中的文字分割为单个词
- 将文档中的每个词转化为某一特征向量
- 预测模型使用特征向量和标签进行学习
下面图展示训练过程的Pipeline:
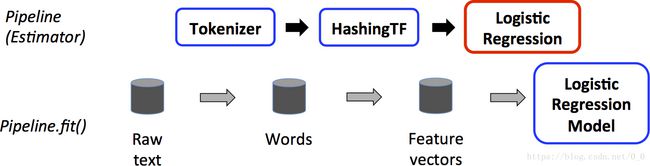
上面第一行列出Pipleline包含三个阶段,前两个(Tokenizer和HashingTF)为转化Transformer,第三个(Logistic Regression)为评估(Estimator)。
第二行列出了在pipeline中的数据流向,其中圆柱表示DataFrames。包含原始文本的DataFrame调用第一个Pipeline.fit() ,Tokenizer.transform()函数将原始文本拆分出独立的文字,在DataFrames中添加新的文字列。HashingTF.transform()函数将文字转化为特征向量列,并新添加入DataFrame中。
LogisticRegression作为评估者Estimator,调用LogisticRegression.fit()函数生成LogisticRegressionModel。
该Model是一个Transformer被用于下面的测试验证阶段。
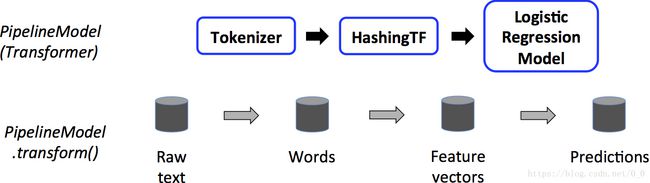
测试验证过程所有阶段皆为Transformers,调用PiplelineModel的transform()方法,数据依次经过pipeline过程,每个阶段的transform()方法更新数据集并递交给下个阶段。
示例代码
举例:Estimator, Transformer, Param
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
// 准备训练数据,数据格式为(标签label, 特征features)
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5))
)).toDF("label", "features")
// 创建逻辑回归实例,这个实例是评价者Estimator.
val lr = new LogisticRegression()
// 输出打印parameters, documentation, 以及其他默认值
println(s"LogisticRegression parameters:\n ${lr.explainParams()}\n")
// 使用Setter方法设置参数parameters
lr.setMaxIter(10)
.setRegParam(0.01)
// 学习LogisticRegression模型.
val model1 = lr.fit(training)
// 输出model 相关参数(name: value)对
println(s"Model 1 was fit using parameters: ${model1.parent.extractParamMap}")
// 也可以使用ParamMap的方法设置参数
// 仅适用于特定的函数的指定的参数
val paramMap = ParamMap(lr.maxIter -> 20)
.put(lr.maxIter, 30) // 设定参数1. 将会覆盖原始的设定值
.put(lr.regParam -> 0.1, lr.threshold -> 0.55) // 设置多参数
// 可以使用复合形式的 ParamMaps.
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // 修改输出列的名字
val paramMapCombined = paramMap ++ paramMap2
// 使用 paramMapCombined 参数生成行的模型model2
// paramMapCombined覆盖所有之前通过lr.set*函数设定的参数
val model2 = lr.fit(training, paramMapCombined)
println(s"Model 2 was fit using parameters: ${model2.parent.extractParamMap}")
// 准备测试数据
val test = spark.createDataFrame(Seq(
(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
(0.0, Vectors.dense(3.0, 2.0, -0.1)),
(1.0, Vectors.dense(0.0, 2.2, -1.5))
)).toDF("label", "features")
//使用Transformer.transform() 函数生成预测
// LogisticRegression.transform 只使用'features' 列.
// 注意model2.transform() 输出列为 'myProbability' 而不是通常的‘probability
// 原因是我们在前面的参数设定中修改了 lr.probabilityCol 参数
model2.transform(test)
.select("features", "label", "myProbability", "prediction")
.collect()
.foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
println(s"($features, $label) -> prob=$prob, prediction=$prediction")
}完整代码参见spark 存储:"examples/src/main/scala/org/apache/spark/examples/ml/EstimatorTransformerParamExample.scala"
举例Pipeline
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// 准备训练文档,使用(id, text, label) 格式.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// 配置机器学习pipeline, 包含三阶段: tokenizer, hashingTF, 以及 lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// 将测试文档加载入pipeline
val model = pipeline.fit(training)
// 将装载后的pipeline保存到磁盘
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// 将未被fit的pipeline保存到磁盘
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// 将保存在磁盘的pipeline重新加载
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// 准备测试文档,该文档是未被标记的
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 基于测试文档生成预测
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}