innodb存储引擎内幕纪要
说到innodb,大家肯定很熟悉,innodb它是MySQL5.5以后的默认存储引擎,它支持事务,支持行级锁,对比myisam存储引擎,没有事务,只有表锁功能来说,innodb存储引擎受到广大开发者的喜爱;
那么,我们现在来了解一下:
innodb存储引擎内部结构是怎么样的?
innodb支持什么索引?什么是B+Tree?
为什么支持事务?
行级锁的实现原理是什么?
innodb体系结构
想了解innodb存储引擎的实现,那么我们应该从其体系结构开始了解,其实innodb的体系结构很简单,它主要是跟磁盘中存储的二进制文件打交道,获取文件中的数据,并返回结果,如图:
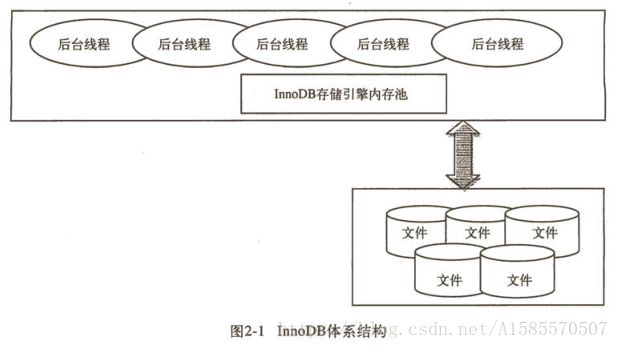
如图所示,就是一堆线程和一堆文件之间的较量,看着就觉得不难是吧[奸笑]!
那么我们来看看后台线程池
后台线程主要是将文件中的数据刷新到内存池的缓存中、将内存中的数据刷新到文件中,并保证数据库发生异常后能恢复;
为了能完成上面的功能,innodb设计了几个线程:
- I/O线程:主要有insert buffer thread(插入缓冲线程),log thread(日志线程),read thread(读线程),write thread(写线程)【MySQL5.1之前默认每个线程一个,5.1版本采用innodb plugin之后,读写线程增加到4个,可以使用innodb_read_io_threads和innodb_write_io_threads参数查看当前数据库读写线程数量】
- master线程:master thread几乎实现了innodb的所有功能
- 锁监控线程:用于实现锁机制
- 错误监控线程:监控其他线程的运行错误
innodb内存结构
所有的后台线程都是运行子innodb分配的内存中的,那么我们来窥探一下innodb的内存结构
主要有几部分:缓冲池(buffer pool)、重做日志缓冲池(redo log buffer)以及额外内存池(additional memory buffer)组成,可通过配置文件中的参数innodb_buffer_pool_size和innodb_log_buffer_size来修改;
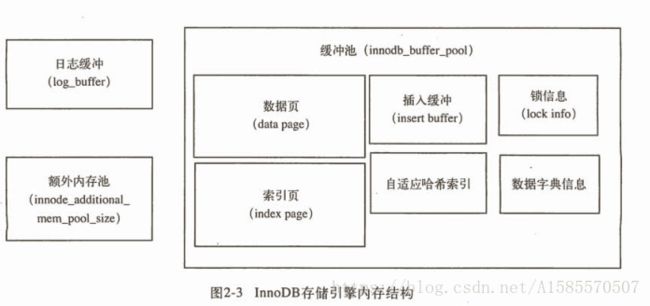
以上便是innodb存储引擎的内存结构,从上图可以看出,缓冲池中缓冲的除了索引和数据,还缓冲了很多其他信息,如插入缓冲、锁信息等等,简单介绍一下几个特性:
- 日志缓冲:主要是用来存放重做日志信息缓冲的,并定时将重做日志刷新到文件中,默认是每秒刷
- 额外内存池:主要是一些数据结构本身在分配内存时,需要申请额外的内存池
- 插入缓冲:是指非聚集索引(辅助索引)在数据插入时,不直接插入到文件,而是缓冲起来,定时刷新到文件
- 自适应哈希索引:innodb的一个自我优化,当innodb发现建立哈希索引可以有性能提升,则建之,索引成为自适应的,对索引的监控信息就放在自适应索引缓冲区里
前面说了,master thread几乎实现了innodb的所有功能,它主要有几个循环,主循环(loop)、后台循环(background loop)、刷新循环(flush loop)和暂停循环(suspend loop),master都会在这几个循环中切换,那么我们来看一下master thread实现了哪些功能:
每秒操作:
- 日志缓冲刷新到磁盘,即时这个事务还没有提交(总是)
- 合并插入缓冲(可能)
- 至多刷新100个innodb缓冲池中的脏页到磁盘(可能)
- 如果当前没有用户活动,切换到后台循环(background loop)(可能)
每10秒操作:
- 刷新100个脏页到磁盘(可能)
- 合并至多5个插入缓冲(总是)
- 将日志缓冲刷新到磁盘(总是)
- 删除无用的undo页(总是)
- 产生一个检查点(总是)
到这里,我想你应该大致了解了innodb的内部功能是怎么样了,它主要做了哪些事情,可以看出,innodb这些所有的操作,都是基于磁盘中的文件,所有的优化都是因为磁盘I/O太垃圾慢了,够不上我大内存的速度,那接下来我们就去看看磁盘中的文件到底存储了些什么
innodb存储引擎文件
innodb的存储引擎文件包括重做日志文件和表空间文件(默认名为ibdata1),存储的数据按照表空间存放,可以通过innodb_data_file_path参数来设置表空间大小
[mysql]
innodb_data_file_path=/db/ibdata1:2000M;/db/ibdata2:2000M;autoextend;
这样的话,所有的数据都存储在共享表空间内,当然,你也可以将每个表的数据区分开,设置innodb_file_per_table=On,这样每个表就会单独生成一个.ibd的文件,但仅仅是存储数据、索引和插入缓冲,其他信息还在共享表空间ibdata1
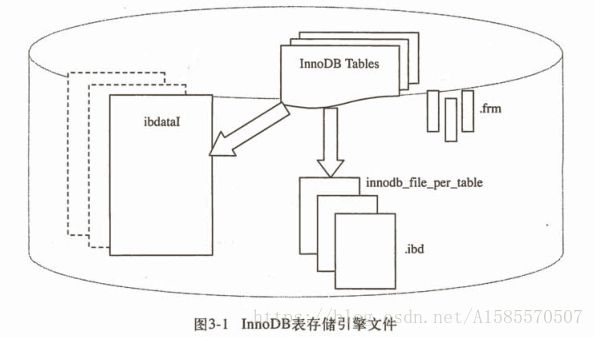
如上图所示。
重做日志文件,用于数据库异常是数据恢复的,保持数据的一致性的,有ib_logfile0和ib_logfile1,1用于备份;
表空间的组成
表空间是innodb的逻辑存储结构,它由段(segment)、区(extent)、页(page)组成,关系如下:
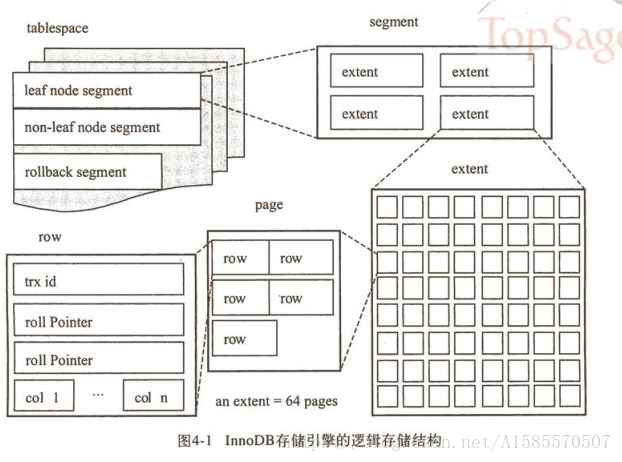
每次申请的时候,申请一个段(segment),1段=4区=64页=64*16K 大小
由此可以看出来,数据库最小的存储单元是页,以页为存储单位
innodb存储引擎索引
innodb存储引擎的索引通常有两种类型,B+树索引和哈希索引,而哈希是自适应的,不能手动创建;
注意:B+树不是一个二叉树,只是由二叉树演化而来,从上面我们讲了innodb存储引擎的逻辑结构,我们知道innodb最小的存储单位是页,所以B+树引擎能索引到的是页,而不是具体的行,索引到页之后将页读入内存,获取到行数据,而内存每次读取磁盘的数据都会发生I/O操作,一次I/O操作大概是10ms,而由于innodb的高扇出性(选择性),B+树的高度一般在3层,所以最多会发生2~3次I/O,即20~30ms
B+树索引又可以分为聚集索引和辅助聚集索引,数据页只能按照一个B+树排序,所以一个表只有一个聚集索引
聚集索引和辅助聚集索引(非聚集索引)之间的区别是,辅助聚集索引的叶子结点存储是聚集索引的值,聚集索引的叶子结点是数据页,获取到聚集索引的值之后再通过聚集索去查询对应的数据页,下面是他们之间的关系:
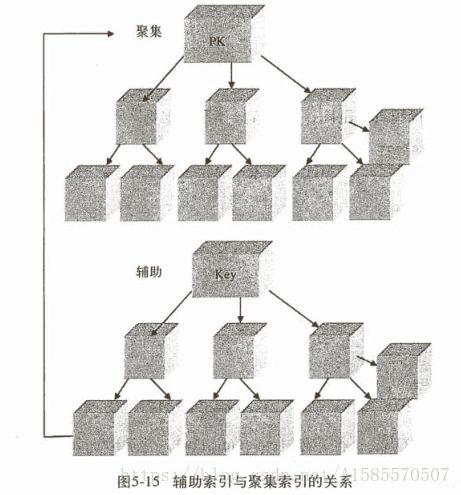
所以通过非聚集索引来查找数据,需要进行双倍的逻辑IO,如上图3层的B+树结构,通过非聚集索引找到聚集索引需要3次逻辑IO,再由聚集索引找到数据页又需要3次逻辑IO,一共6次逻辑IO,但是还有下面一种情况:
现在存在一张student(id,username,class,created)表,id为主键,表里面有四个字段,B+树的索引节点里面存储了被索引列的值,那么辅助索引叶子结点里面就存储了聚集索引和辅助索引列的值,假设username为一个辅助索引,执行下面语句:
select id,username from student;
你会发现,优化器选择的是username这个辅助索引,而不是primary聚集索引,为什么呢?
原因是,只要找到了辅助索引的叶子节点,叶子节点里包含了主键id和辅助索引b的值,而你select的正好是这两个值,innodb就会直接返回查询到的数据,依据上面的说法,这里只发生了3次逻辑IO,而且还避免了磁盘IO(因为不用去磁盘load数据),可想而知,这里的速度是非常快的。
知道这个原理之后,你就可以发挥想象,可以将常用的字段,比如class,和username做一个联合索引,然后你懂的。。。
当然,不能滥用了,数据一旦庞大起来,索引是非常难维护的,不要自己挖坑埋了自己!!!
innodb事务
说到事务,大家肯定想到事务的ACID四个特性:
原子性(Atomicity)、 一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
那么怎么实现这几个特性了呢?
innodb存储引擎采用redo和undo日志来实现原子性、一致性和持久性,隔离性由锁机制来控制
redo:重写日志文件
undo:撤销日志文件
当一个事务开始时,会记录一个LSN(log sequence number,日志序列号),当事务执行时,相关的信息会先写到日志缓冲中,事务提交之后,日志缓冲就会刷新到磁盘,所以,更改数据库数据,是先写日志,后更改数据,这种方式成为预写日志方式(Write-Ahead Logging,WAL),保证了数据的完整性和一致性;
这里会有生成两种日志,就是redo和undo,就像编辑器中的撤销和返回的道理是一样的,区别在于redo是存储在重做日志文件中,而undo是存储在数据库内的特殊段(Segment)中,称为undo段,位于共享表空间内
有了这个撤销和返回日志,在mysql宕机或者数据库执行rollback的时候,都可以从日志中恢复原来的数据,即可实现原子性
这个就是事务的实现方式,其实也并没有那么复杂,是吧
锁机制
锁的产生是因为资源的共享而导致的,并发线程请求同一个资源,为保证每个用户可以一致的读取和修改数据,就需要锁起来,独享[奸笑],这就有了锁机制
锁的类型有两种:
共享锁:(S Lock)允许事务读一行数据
排他锁:(X Lock)允许事务更新或删除一行数据
两个会话去更新同一条记录的时候,会先申请锁,锁住之后,其他事务只能等待:
如session1,更新上面的student表的名字,开启事务,但不提交
mysql>begin;
mysql>update student set username="张三" where id=1;
这时session2,同样更新id=1的名字:
mysql>begin;
mysql>update student set username="李四" where id=1;
这个时候,session2是没有办法更新的,因为session1已经锁住了id=1这行数据,在session1提交之前,session2只能
一直等待,这就保证了事务的隔离性
当然,有了锁,就会有阻塞问题,有死锁问题,这些都是在所难免的
以上我们将了innodb引擎的存储结构、表空间、B+树索引、事务的实现和锁机制等内容,描述的可能不太好,不知道大家有没有理解,有问题欢迎指正
参数书籍:
《MySQL技术内幕:Innodb存储引擎》