说到JMM大家一定很陌生,被我们所熟知的一定是jvm虚拟机,而我们今天讲的JMM和JVM虚拟机没有半毛钱关系,千万不要把JMM的任何事情联想到JVM,把JMM当做一个完全新的事物去理解和认识。
我们先看一下计算机的理论模型,也是冯诺依曼计算机模型,先来张图。
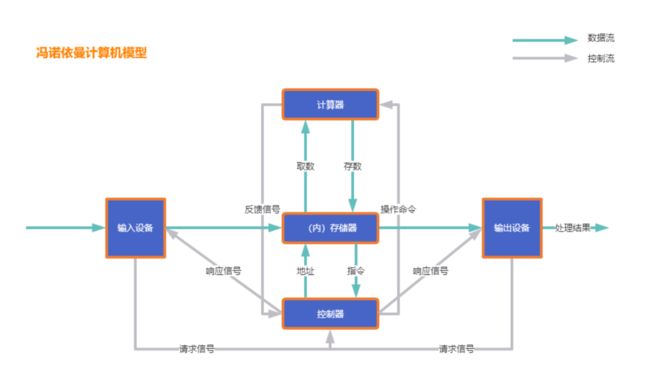
其实我们更关注与计算机的内部CPU的计算和内存之间的关系。我们在来深入的看一下是如何计算的。
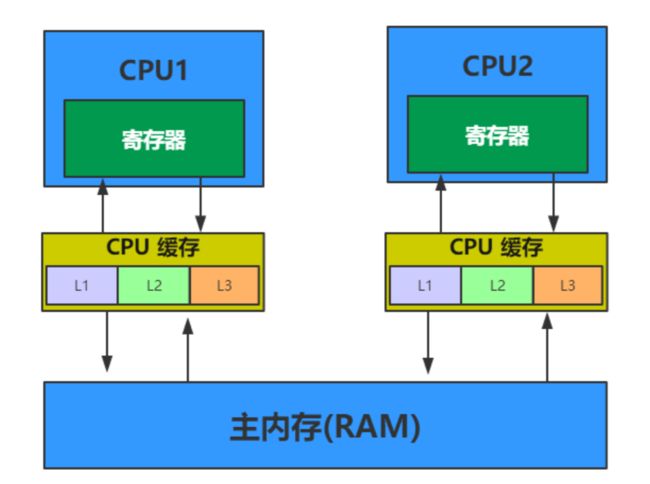
我们来看一下这个玩意的处理流程啊,当我们的数据和方法加载的内存区,需要处理时,内存将数据和方法传递到CPU的L3->L2->L1然后再进入到CPU进行计算,然后再由L1->L2->L3->再返回到主内存中,但是我们的科技反展的很快的,现在貌似没有单核的CPU了吧,什么8核16核的CPU随处可见,我们这里只的CPU只是CPU的一个核来计算这些玩意。假设我们的方法是f(x) = x + 1,我们入参是1,期望得到结果是2,1+1=2,我计算的没错吧。如果我们两个核同时执行该方法呢?我们的CPU2反应稍微慢了一点呢?假如当我们的内存再向CPU2发送参数时,可能CPU1已经计算完成并且已经返回了。这时CPU2取得的参数就是2,这时再进行计算就是2+1了。结果并不是我们期望的结果。这其实就是数据未同步造成的。我们应该想尽我们的办法去同步一下数据。
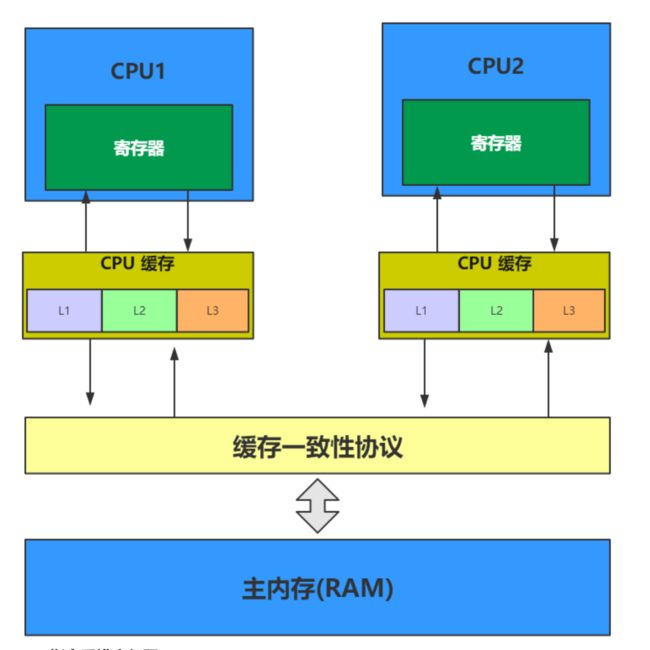
我们中间加了一层缓存一致性协议。也就是我们的MESI,在多处理器系统中,每个处理器都有自己的高速缓存,而它们的又共享同一个主内存
我来简单说一下,我们的MESI是咋回事,是怎么做到缓存一致性的。英语不好,我就不误解大家解释MESI是什么单词的缩写了(是不是缩写我也不知道,但是我知道工作原理)。
我们还是从内存到CPU的这条线路,这时我们多了一个MESI,当变量X被共同读取时,CPU1和CPU2是共享一个X变量,但是分别存在CPU1和2内,也就是我们X(S)的状态。然后CPU1和2一起准备要计算了。
然后1和2一定会有一个厉害的。比如1得到了胜利,这时CPU1里的X(S)变为X(E)由共享状态变为独享状态,并且告诉CPU2把X(S)变为X(I)的状态,由共享状态变为失效状态。然后CPU1就可以计算了。计算完成,
又将X(S)变为X(M)的状态,由独享状态变为了修改的状态。
M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。
当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。
同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
I: 无效的(Invalid)
说到这也就是是我们JMM的内存模型的工作机制了。所以说JMM是一个虚拟的,和JVM一点关系都没有的。切记不要混淆。
这里也有三个重要的知识点。
JVM 内存模型(JMM) 三大特性
原子性:指一个操作是不可中断的,即使是多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰
比如,对于一个静态全局变量int i,两个线程同时对它赋值,线程A 给他赋值 1,线程 B 给它赋值为 -1,。那么不管这两个线程以何种方式,何种步调工作,i的值要么是1,要么是-1,线程A和线程B之间是没有干扰的。这就是原子性的一个特点,不可被中断
可见性:指当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道这个修改。显然,对于串行程序来说,可见性问题 是不存在。因为你在任何一个操作步骤中修改某个变量,那么在后续的步骤中,读取这个变量的值,一定是修改后的新值。但是这个问题在并行程序中就不见得了。如果一个线程修改了某一个全局变量,那么其他线程未必可以马上知道这个改动。
有序性:对于一个线程的执行代码而言,我们总是习惯地认为代码的执行时从先往后,依次执行的。这样的理解也不能说完全错误,因为就一个线程而言,确实会这样。但是在并发时,程序的执行可能就会出现乱序。给人直观的感觉就是:写在前面的代码,会在后面执行。有序性问题的原因是因为程序在执行时,可能会进行指令重排,重排后的指令与原指令的顺序未必一致(指令重排后面会说)。
我们来看一下volatile关键字
先看一段代码吧,不上代码,总觉得是自己没练习到位。
private static int counter = 0; public static void main(String[] args) { for (int i = 0; i < 10; i++) { Thread thread = new Thread(()->{ for (int j = 0; j < 1000; j++) { counter++; //不是一个原子操作,第一轮循环结果是没有刷入主存,这一轮循环已经无效 } }); thread.start(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(counter); }
按照JMM的思想流程来解读一下这段代码,我们先创建10个线程。我们这里叫做T1,T2,T3...T100。然后分别去拿counter这个数字,然后叠加1,循环1000-counter次。当T1拿到counter,开始计算,假如,我们计算到第50次时,这时线程T2,也开始要拿counter这个数字,这时得到的counter数字为50,则T2就要循环950次,最后我们计算得到的counter就是9950。也就是说,内部是没有内存一致性协议的。所以我们的输出一定是<=10000的数字。
我们来尝试改一下代码,使用一下我们的volatile关键字。
private static volatile int counter = 0; public static void main(String[] args) { for (int i = 0; i < 10; i++) { Thread thread = new Thread(()->{ for (int j = 0; j < 1000; j++) { counter++; //不是一个原子操作,第一轮循环结果是没有刷入主存,这一轮循环已经无效 } }); thread.start(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(counter); }
这时我们加入了volatile关键字,我们经过多次运行会发现,每次结果都为10000,也就是说每次都是我们期待的结果,volatile可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在JVM底层volatile是采用“内存屏障”来实现的。
也就是我们加入了volatile关键字时,java代码运行过程中,会强制给予一层内存一致性的屏障,做到了,我们计算直接不会相互影响,得到我们预期的结果。
1、可见性实现:
在前文中已经提及过,线程本身并不直接与主内存进行数据的交互,而是通过线程的工作内存来完成相应的操作。这也是导致线程间数据不可见的本质原因。因此要实现volatile变量的可见性,直接从这方面入手即可。对volatile变量的写操作与普通变量的主要区别有两点:
(1)修改volatile变量时会强制将修改后的值刷新的主内存中。
(2)修改volatile变量后会导致其他线程工作内存中对应的变量值失效。因此,再读取该变量值的时候就需要重新从读取主内存中的值。相当于上文说到的从S->E,另一个线程从S->I的过程。
通过这两个操作,就可以解决volatile变量的可见性问题。
2、内存屏障
为了实现volatile可见性和happen-befor的语义。JVM底层是通过一个叫做“内存屏障”的东西来完成。内存屏障,也叫做内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。下面是完成上述规则所要求的内存屏障:
| Required barriers | 2nd operation | |||
| 1st operation | Normal Load | Normal Store | Volatile Load | Volatile Store |
| Normal Load | LoadStore | |||
| Normal Store | StoreStore | |||
| Volatile Load | LoadLoad | LoadStore | LoadLoad | LoadStore |
| Volatile Store | StoreLoad | StoreStore | ||
(1)LoadLoad 屏障
执行顺序:Load1—>Loadload—>Load2
确保Load2及后续Load指令加载数据之前能访问到Load1加载的数据。
(2)StoreStore 屏障
执行顺序:Store1—>StoreStore—>Store2
确保Store2以及后续Store指令执行前,Store1操作的数据对其它处理器可见。
(3)LoadStore 屏障
执行顺序: Load1—>LoadStore—>Store2
确保Store2和后续Store指令执行前,可以访问到Load1加载的数据。
(4)StoreLoad 屏障
执行顺序: Store1—> StoreLoad—>Load2
确保Load2和后续的Load指令读取之前,Store1的数据对其他处理器是可见的。
总体上来说volatile的理解还是比较困难的,如果不是特别理解,也不用急,完全理解需要一个过程,在后续的文章中也还会多次看到volatile的使用场景。这里暂且对volatile的基础知识和原来有一个基本的了解。总体来说,volatile是并发编程中的一种优化,在某些场景下可以代替Synchronized。但是,volatile的不能完全取代Synchronized的位置,只有在一些特殊的场景下,才能适用volatile。总的来说,必须同时满足下面两个条件才能保证在并发环境的线程安全:
(1)对变量的写操作不依赖于当前值。
(2)该变量没有包含在具有其他变量的不变式中。
参考地址:https://www.cnblogs.com/paddix/p/5428507.html
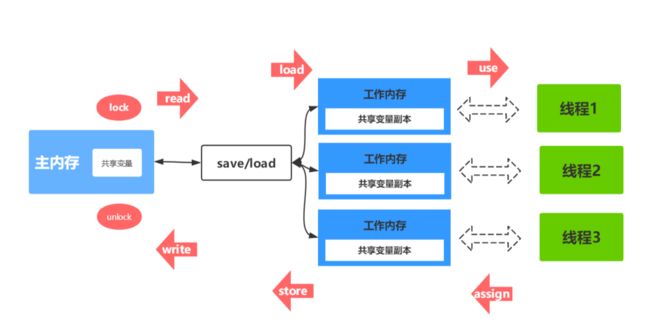
JMM-同步八种操作介绍
(1)lock(锁定):作用于主内存的变量,把一个变量标记为一条线程独占状态
(2)unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的 变量才可以被其他线程锁定
(3)read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中, 以便随后的load动作使用
(4)load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作 内存的变量副本中
(5)use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
(6)assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存 的变量
(7)store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中, 以便随后的write的操作
(8)write(写入):作用于工作内存的变量,它把store操作从工作内存中的一个变量的值传送 到主内存的变量中
流程图大致是这样的:
后面会继续谈谈并发的问题。也会仔细说一下指令重排这里,这篇博客只是暂时的说了一下而已,后续还有很多重要的知识点要说。