1.感知机回归概念
感知机(Perceptron)是二分类的线性分类模型,其输入是实例的特征向量,输出是实例的类别,取+1及-1二值。感知机是在1957年由Rosenblatt提出,今天看来它的分类模型在大多数时候泛化能力不强,但是它的原理却值得好好研究。因为研究透了感知机模型,学习支持向量机的话会降低不少难度。同时如果研究透了感知机模型,再学习神经网络,深度学习,也是一个很好的起点。
假设输入空间是χ⊆Rnχ⊆R^nχ⊆Rn,输出空间是γ=(+1,−1)γ=(+1,−1)γ=(+1,−1)。输入χ∈Xχ∈Xχ∈X表示实例的特征向量,对应于输入空间的点;输出y∈γy∈γy∈γ表示实例的类别。由输入空间到输出空间的如下函数:
f(x)=sign(wx+b)f(x)=sign(wx+b)f(x)=sign(wx+b)
其中,www(权值)和bbb(偏置)为感知机模型的参数,wxwxwx表示www和xxx的内积,sign是符号函数,即:
sign(x)={+1x≥0−1x<0sign\left( x\right) =\begin{cases}+1 &x\geq 0\\-1 &x<0 \end{cases}sign(x)={+1−1x≥0x<0
感知机学习策略
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练集正实例点和负实例点完成正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数www,bbb,需定义损失函数并将损失函数极小化。损失函数使用误分类点到超平面SSS的总距离,因此输入空间RnR^nRn中任何一点x0x_0x0到超平面SSS的距离为:
1∥w∥∣wx+b∣\frac{1}{∥w∥}|wx+b|∥w∥1∣wx+b∣
在这里,∥w∥∥w∥∥w∥是www的L2范数。对于误分类的数据(xi,yi)(x_i,y_i)(xi,yi)来说,−yi(wxi+b)>0−y_i(wx_i+b)>0−yi(wxi+b)>0
成立。因为当wxi+b>0wx_i+b>0wxi+b>0时,yi=−1y_i=−1yi=−1,而当wxi+b<0wx_i+b<0wxi+b<0时,yi=+1y_i=+1yi=+1,因此,误分类点xix_ixi到超平面SSS的距离是:
−1∥w∥yi(wxi+b)−\frac{1}{∥w∥}y_i(wx_i+b)−∥w∥1yi(wxi+b)
这样,假设超平面SSS的误分类点集合为MMM,那么所以误分类点到超平面SSS的总距离为:
−1∥w∥∑xi∈Myi(wxi+b)−\frac{1}{∥w∥}∑_{x_i∈M}y_i(wx_i+b)−∥w∥1∑xi∈Myi(wxi+b)
不考虑1∥w∥\frac{1}{∥w∥}∥w∥1,就得到感知机学习的损失函数:
L(w,b)=−∑xiεnyi(wxi+b)L(w,b)=−∑_{x_iεn}y_i(wx_i+b)L(w,b)=−∑xiεnyi(wxi+b)
其中M为误分类点的集合。
2.感知机学习算法的原始形态
感知机算法是使得损失函数L(w,b)L(w,b)L(w,b)极小化的最优化问题,可以使用随机梯度下降法来进行最优化。假设误分类点集合M是固定的,那么损失函数L(w,b)L(w,b)L(w,b)的梯度由
∇wL(ω,b)=−∑xiεnyixi\nabla _{w}L\left( \omega ,b\right) =-\sum _{x_{i\varepsilon }n}y_{i}x_{i}∇wL(ω,b)=−∑xiεnyixi
∇bL(ω,b)=−∑xiεnyi\nabla _{b}L\left( \omega ,b\right) =-\sum _{x_{i\varepsilon }n}y_{i}∇bL(ω,b)=−∑xiεnyi
给出,随机选取一个误分类点(xi,yi)(x_i,y_i)(xi,yi),对w,bw,bw,b进行更新:
w←w+ηyixiw\leftarrow w+\eta y_ix_iw←w+ηyixi
b←b+ηyib\leftarrow b+\eta y_ib←b+ηyi
其中η(0<η≤1)η(0<η≤1)η(0<η≤1) 称为学习率(learning rate),这样通过迭代可以使得损失函数L(w,b)L(w,b)L(w,b)不断减小,直到为0。
感知机算法原始形式的主要训练过程,《统计学习方法》李航,P29页:
Python代码实现主要函数:
# 感知机学习算法的原始形态
def perceptron(dataSet,loop_max=100):
eta=1 # 学习率
features=dataSet.shape[1]-1 # x特征列数量
w=np.array([x*0 for x in range(0,features)])
b=0
for times in range(loop_max):
for d in dataSet:
x=d[:-1]
y=d[-1]
if y*(w@x+b)<=0: # @符号作用同np.dot
w=w+eta*y*x
b=b+eta*y
return w,b
3.感知机学习算法的对偶形式
假设w0w_0w0,b0b_0b0均初始化为0,对误分类点通过
w←w+ηyixiw←w+ηy_ix_iw←w+ηyixi
b←b+ηyib←b+ηy_ib←b+ηyi
逐步修改w,bw,bw,b,设修改n次,则w,bw,bw,b关于(wi,yi)(w_i,y_i)(wi,yi)的增量分为是αiyixiα_iy_ix_iαiyixi和αiyiα_iy_iαiyi,这里的αi=niηα_i=n_iηαi=niη,其中ni表示第i个点误分类的次数,这样最后学习到的w,bw,bw,b可以分别表示为
w=∑i=1Nαiyixiw=∑_{i=1}^{N}α_iy_ix_iw=∑i=1Nαiyixi
b=∑i=1Nαiyib=∑_{i=1}^{N}α_iy_ib=∑i=1Nαiyi
实例点更新的次数越多,意味着它距离分离超平面越近,也就越难正确分类。
训练过程,《统计学习方法》李航,P33-34页:
输出α,bα,bα,b,其中α=(α1,α2,...,αN)Tα=(α_1,α_2,...,α_N)^Tα=(α1,α2,...,αN)T
(1)α←0,b←0α←0,b←0α←0,b←0
(2)在训练集中选取数据(xi,yi)(x_i,y_i)(xi,yi)
(3)如果yi(∑j=1nαjyjxj⋅xi+b)≤0y_i(∑_{j=1}^nα_jy_jx_j⋅x_i+b)≤0yi(∑j=1nαjyjxj⋅xi+b)≤0,则
αi←αi+ηα_i←α_i+ηαi←αi+η
b←b+ηyib←b+ηy_ib←b+ηyi
(4)转到(2),直到没有错误。
最后通过w=∑i=1Nαiyixiw=∑_{i=1}^Nα_iy_ix_iw=∑i=1Nαiyixi计算出www,使用上述过程求出的bbb,即计算出模型参数。
Python代码实现主要函数:
# 感知机算法对偶形式
def perceptron_dual(dataSet,loop_max=100):
m, n = dataSet.shape
a=np.zeros((m, 1))
b=0
x_fea=dataSet[:,:-1]
G=x_fea@x_fea.T # @符号作用同np.dot
#G=np.dot(x_fea,x_fea.T) # 两种写法均可
x=dataSet[:,:-1]
y=dataSet[-1].reshape((-1,1))
for times in range(loop_max):
for i in range(0,m):
yi=y[i]
err=0
err=sum(a*y*G[i].reshape((m,1)))+b
if yi*err<=0:
a[i]=a[i]+1
b=b+yi
break
print('a:',a.T,'b:',b)
w=(a*y).T@x
return w,b
程序输出结果:
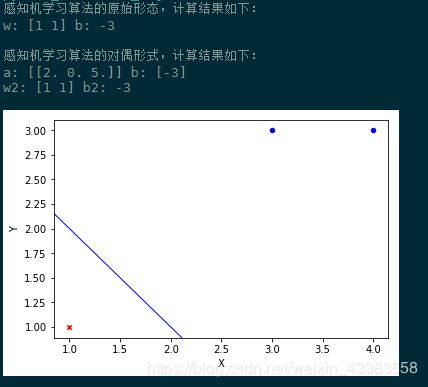
以上算法完整源代码:
# -*- coding: utf-8 -*-
"""
@Time : 2018/11/21 09:22
@Author : hanzi5
@Email : [email protected]
@File : perceptron.py
@Software: PyCharm
"""
import numpy as np
#import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
# 感知机学习算法的原始形态
def perceptron(dataSet,loop_max=100):
eta=1 # 学习率
features=dataSet.shape[1]-1 # x特征列数量
w=np.array([x*0 for x in range(0,features)])
b=0
for times in range(loop_max):
for d in dataSet:
x=d[:-1]
y=d[-1]
if y*(w@x+b)<=0: # @符号作用同np.dot
w=w+eta*y*x
b=b+eta*y
return w,b
# 感知机算法对偶形式
def perceptron_dual(dataSet,loop_max=100):
m, n = dataSet.shape
a=np.zeros((m, 1))
b=0
x_fea=dataSet[:,:-1]
G=x_fea@x_fea.T # @符号作用同np.dot
#G=np.dot(x_fea,x_fea.T) # 两种写法均可
x=dataSet[:,:-1]
y=dataSet[-1].reshape((-1,1))
for times in range(loop_max):
for i in range(0,m):
yi=y[i]
err=0
err=sum(a*y*G[i].reshape((m,1)))+b
if yi*err<=0:
a[i]=a[i]+1
b=b+yi
break
print('a:',a.T,'b:',b)
w=(a*y).T@x
return w,b
# 可视化结果
def plotResult2(dataSet, weight, bias):
fig = plt.figure()
axes = fig.add_subplot(111)
# 取两类x1及x2值画图
type1_x1=dataSet[dataSet[:,-1]==-1][:,:-1][:,0].tolist()
type1_x2=dataSet[dataSet[:,-1]==-1][:,:-1][:,1].tolist()
type2_x1=dataSet[dataSet[:,-1]==1][:,:-1][:,0].tolist()
type2_x2=dataSet[dataSet[:,-1]==1][:,:-1][:,1].tolist()
# 画点,使用红蓝两色
axes.scatter(type1_x1, type1_x2, marker='x', s=20, c='red')
axes.scatter(type2_x1, type2_x2, marker='o', s=20, c='blue')
# 画线
y = (0.1 * -weight[0] / weight[1] + -bias / weight[1], 4.0 * -weight[0] / weight[1] + -bias / weight[1])
axes.add_line(Line2D((0.1, 4.0), y, linewidth=1, color='blue'))
# 画坐标轴标签
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
if __name__ == '__main__':
# 生成数据,《统计学习方法》李航,P29,例2.1
dataSet=np.array([[3,3,1],[4,3,1],[1,1,-1]])
# 感知机学习算法的原始形态
w,b=perceptron(dataSet)
print('感知机学习算法的原始形态,计算结果如下:')
print('w:',w,'b:',b)
print()
# 感知机学习算法的对偶形式
print('感知机学习算法的对偶形式,计算结果如下:')
w2,b2=perceptron_dual(dataSet)
print('w2:',w,'b2:',b)
# 画图
plotResult2(dataSet, w2.reshape((-1,1)), b2)
参考资料:
1、《机器学习实战》Peter Harrington著
2、《机器学习》西瓜书,周志华著
3、 斯坦福大学公开课 :机器学习课程
4、机器学习视频,邹博
5、《统计学习方法》李航
6、感知机原理小结
7、机器学习算法–Perceptron(感知机)算法