目标检测: R-CNN
文章目录
- 写在前面
- R-CNN 的 pipeline
- R-CNN 的训练过程
- 微调 CNN
- 训练 SVM
- 训练 bounding-box 回归模型
- 其他
论文题目:《Rich feature hierarchies for accurate object detection and semantic segmentation》
论文链接: https://arxiv.org/abs/1311.2524v3
代码实现: https://github.com/rbgirshick/rcnn(基于 Caffe + matlab)
写在前面
现在深度学习的工具和资料越来越多,门槛也越来越低,但是经典仍然是经典,在日常学习或者是面试考察中,尤其图像类的算法岗位,回答相关问题的细节和条理性显得尤为重要,甚至之前自己已经整理过的一些内容,不及时复习回顾也是枉然。这也是笔者被面试官按在地上摩擦以后的惨痛教训,痛定思痛,接下来的一系列文章要再拜读并整理一些经典之作的思想和脉络。也希望读到这篇文章的有缘人可以积极留言交流学习,我也可以查漏补缺。
R-CNN 的 pipeline
.
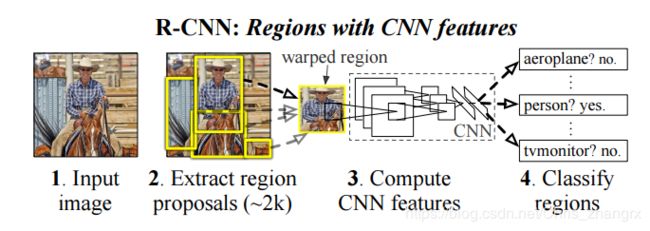
Step1: 输入图片,用 Selective search 的方法在图片中提取 region proposal(这里使用 SS 也是为了跟同时期的其他方法方便对比)
Step2: 提取特征,将这些 region proposal 经过一些预处理,送进 CNN 提取特征
Step3: 使用 SVM 对这些特征进行分类学习,并进行边框回归
R-CNN 的训练过程
Step1: 微调 CNN。将 CNN 在 ImageNet 分类数据集下预训练,再将 CNN 最后一层分类层进行替换,然后使用 warp 过的 region proposal 进行微调。
Step2: 训练 SVM。 对每一类创建一个二分类的线性 SVM,然后结合得到的每一类的特征和标签进行训练。
Step3: 训练边框回归模型。bounding-box regressor 模型的训练
微调 CNN
这里主要是解决训练一个大的 CNN 网络时,目标检测领域的数据集缺乏的问题,传统方法都是先使用非监督学习预训练,再用监督学习微调。本文是先在 ImageNet 上预训练CNN,然后再在获取的目标候选区域。这里主要需要了解的可能就是文中是如何处理输入的 region proposal 来微调 CNN 的。
.

如上图所示,因为使用的 CNN 中有全连接层,所以输入图片的尺寸需要是固定的, 因此 region proposal 需要做一些处理才可以输入 CNN 中。 文中分别是将 region proposal 直接扩展成正方形(B列),就以原 region proposal 为中心旁边填充图像均值(C列),在 region proposal 的周围边都多截取16个像素,然后 resize 成目标形状(D列), 最后实验证明,D列的方法效果最好。
这里选择 finetune 网络的 region proposal 正样本是与物体的真值框 IoU >=0.5 的,小于0.5的则为负样本。
训练 SVM
这里是用 CNN 提取到的不同类别的特征训练多个线性SVM分类器,主要是正负样本的选择问题,这里判断正负样本的阈值为0.3 (不同于 Finetune CNN 时候的 0.5 阈值,文中表示选择 0.5 阈值性能会下降 5 个点),而且使用了 hard negative mining 的。至于为什么不是微调后直接采用 softmax 进行分类而是使用多个 SVM? 文中给出的解释是第一,微调使用的 region proposal 正样本阈值满足大于等于 0.5 就可以了,不强调准确定位,第二,微调时负样本是随机抽样的,SVM 则是经过 hard negative mining 的。
Ps: hard negative mining 是指把分类器错误分类的样本(负样本分类成了正样本),挑选出来,重新加入到训练集继续训练。
训练 bounding-box 回归模型
为了更加准确的定位,文中还使用了一个简单的边框回归网络,对 SVM 已经分类好的 region proposal ,R-CNN 还会使用边框回归模型预测一个新的边框位置。这里主要的灵感来自于 DPM 的工作,边框回归的输入是一对对的预测坐标和真值坐标。主要是对由预测的坐标和真值坐标之间的映射关系进行参数化,使其能够学习。.

如上,对预测的 P 窗口加上一个偏移量 P wd x 即平移,然再乘以一个系数 exp(d x)进行缩放,其实边框回归算法学习的就是上面的 d x,d y,d w,d h 四个变换。
这里输入边框回归模型的并不是直接的预测 P 左边,而是 R-CNN 经过 Pooling5 层以后的特征向量,训练阶段还有 ground truth,也就是下边的 t=(t x,t y,t w,t h) 。
.
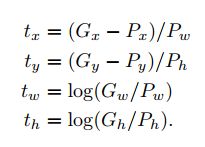
根据上面的公式,就可以将预测框和真值框转换成偏移量 t 了,也就是我们需要学习和预测的值, 所以真正的边框回归的是偏移量。
.
对 d *() 函数的定义如上图,Φ 5(P) 是输入的特征向量,通过学习权值 W,将其转化成偏移量 t,然后依次构建一下新的 Loss,使用梯度下降法或者最小二乘法就可以得到 W。
.

进一步探讨关于映射变换的定义,为什么 tw 和 th 是 log 形式的,在坐标的反变换中,想要缩放的比例因子始终是大于 0 的数,最直观的就是使用 exp 函数,所以转变过来就是 log 形式了。
其他
- 本文是尝试将 CNN 良好的分类特性如何应用到目标检测课题中去, R-CNN 提出之前的二十年间, CNN 主要是用在基于滑动窗口的目标检测方法,且只用在一些特定的领域,例如人脸,行人等,而且这些网络一般都比较浅,都是两层卷积层加一个池化层。
- 本文还使用了非极大值抑制,对一些重叠的建议框进行去重,然后再使用回归模型进行偏移量预测。
- VGG 比 Alex 性能上升了 58.5% -> 66%,但是速度也慢了 7 倍。
参考博客: https://blog.csdn.net/zijin0802034/article/details/77685438/