机器学习&深度学习知识点总结
1.Overfitting是什么?怎么解决?
overfitting就是过拟合, 其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在training data上的error渐渐减小,但是在验证集上的error却反而渐渐增大——因为训练出来的网络过拟合了训练集, 对训练集外的数据却不work, 这称之为泛化(generalization)性能不好。泛化性能是训练的效果评价中的首要目标,没有良好的泛化,就等于南辕北辙, 一切都是无用功。
解决办法主要有以下几种:
正则化(Regularization)
L2正则化:目标函数中增加所有权重w参数的平方之和, 逼迫所有w尽可能趋向零但不为零. 因为过拟合的时候, 拟合函数需要顾忌每一个点, 最终形成的拟合函数波动很大, 在某些很小的区间里, 函数值的变化很剧烈, 也就是某些w非常大. 为此, L2正则化的加入就惩罚了权重变大的趋势.
L1正则化:目标函数中增加所有权重w参数的绝对值之和, 逼迫更多w为零(也就是变稀疏. L2因为其导数也趋0, 奔向零的速度不如L1给力了). 大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些无用的特征,也就是把这些特征对应的权重置为0。
随机失活(dropout)
在训练的运行的时候,让神经元以超参数p的概率被激活(也就是1-p的概率被设置为0), 每个w因此随机参与, 使得任意w都不是不可或缺的, 效果类似于数量巨大的模型集成。
逐层归一化(batch normalization)这个方法给每层的输出都做一次归一化(网络上相当于加了一个线性变换层), 使得下一层的输入接近高斯分布. 这个方法相当于下一层的w训练时避免了其输入以偏概全, 因而泛化效果非常好.
提前终止(early stopping)
理论上可能的局部极小值数量随参数的数量呈指数增长, 到达某个精确的最小值是不良泛化的一个来源. 实践表明, 追求细粒度极小值具有较高的泛化误差。这是直观的,因为我们通常会希望我们的误差函数是平滑的, 精确的最小值处所见相应误差曲面具有高度不规则性, 而我们的泛化要求减少精确度去获得平滑最小值, 所以很多训练方法都提出了提前终止策略. 典型的方法是根据交叉叉验证提前终止: 若每次训练前, 将训练数据划分为若干份, 取一份为测试集, 其他为训练集, 每次训练完立即拿此次选中的测试集自测. 因为每份都有一次机会当测试集, 所以此方法称之为交叉验证. 交叉验证的错误率最小时可以认为泛化性能最好, 这时候训练错误率虽然还在继续下降, 但也得终止继续训练了.
增加样本的全面性和数量、剪枝、集成模型、交叉验证、权值衰减等等

2.LR和SVM的联系与区别。
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
3.生成模型和判别模型
1. 生成模型:由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。(朴素贝叶斯、Kmeans)
生成模型可以还原联合概率分布p(X,Y),并且有较快的学习收敛速度,还可以用于隐变量的学习
2. 判别模型:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。(k近邻、决策树、SVM)直接面对预测,往往准确率较高,直接对数据在各种程度上的抽象,所以可以简化模型
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机。
4.L1和L2正则的区别,如何选择L1和L2正则
他们都是可以防止过拟合,降低模型复杂度
L1是在loss function后面加上 模型参数的1范数(也就是|xi|)
L2是在loss function后面加上 模型参数的2范数(也就是sigma(xi^2)),注意L2范数的定义是sqrt(sigma(xi^2)),在正则项上没有添加sqrt根号是为了更加容易优化
L1 会产生稀疏的特征
L2 会产生更多地特征但是都会接近于0
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。L1在特征选择时候非常有用,而L2就只是一种规则化而已。
5.SVM、LR、决策树的对比?
模型复杂度:SVM支持核函数,可处理线性非线性问题;LR模型简单,训练速度快,适合处理线性问题;决策树容易过拟合,需要进行剪枝
损失函数:SVM hinge loss; LR L2正则化; adaboost 指数损失
数据敏感度:SVM添加容忍度对outlier不敏感,只关心支持向量,且需要先做归一化; LR对远点敏感
数据量:数据量大就用LR,数据量小且特征少就用SVM非线性核
6.GBDT 和随机森林的区别?
随机森林采用的是bagging的思想,bagging又称为bootstrap aggreagation,通过在训练样本集中进行有放回的采样得到多个采样集,基于每个采样集训练出一个基学习器,再将基学习器结合。随机森林在对决策树进行bagging的基础上,在决策树的训练过程中引入了随机属性选择。传统决策树在选择划分属性的时候是在当前节点属性集合中选择最优属性,而随机森林则是对结点先随机选择包含k个属性的子集,再选择最有属性,k作为一个参数控制了随机性的引入程度。
另外,GBDT训练是基于Boosting思想,每一迭代中根据错误更新样本权重,因此是串行生成的序列化方法,而随机森林是bagging的思想,因此是并行化方法。
7.什么是OOB?随机森林中OOB是如何计算的,它有什么优缺点?
bagging方法中Bootstrap每次约有1/e的样本不会出现在Bootstrap所采集的样本集合中,当然也就没有参加决策树的建立,把这1/e的数据称为袋外数据oob(out of bag),它可以用于取代测试集误差估计方法。
袋外数据(oob)误差的计算方法如下:
对于已经生成的随机森林,用袋外数据测试其性能,假设袋外数据总数为O,用这O个袋外数据作为输入,带进之前已经生成的随机森林分类器,分类器会给出O个数据相应的分类,因为这O条数据的类型是已知的,则用正确的分类与随机森林分类器的结果进行比较,统计随机森林分类器分类错误的数目,设为X,则袋外数据误差大小=X/O;这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
8.为什么xgboost要用泰勒展开,优势在哪里
xgboost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了xgboost的适用性, 使得它按需选取损失函数, 可以用于分类, 也可以用于回归。
9.xgboost如何寻找最优特征?是有放回还是无放回的呢?
xgboost在训练的过程中给出各个特征的增益评分,最大增益的特征会被选出来作为分裂依据, 从而记忆了每个特征对在模型训练时的重要性 -- 从根到叶子中间节点涉及某特征的次数作为该特征重要性排序.
xgboost属于boosting集成学习方法, 样本是不放回的, 因而每轮计算样本不重复. 另一方面, xgboost支持子采样, 也就是每轮计算可以不使用全部样本, 以减少过拟合. 进一步地, xgboost 还有列采样, 每轮计算按百分比随机采样一部分特征, 既提高计算速度又减少过拟合
10.说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2...,请写出最终的决策公式。
详情参见机器学习算法总结之Boosting family:AdaBoost
11.请简要说说EM算法
有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个),EM算法一般分为2步:
E步:选取一组参数,求出在该参数下隐含变量的条件概率值;
M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。
重复上面2步直至收敛。
12.机器学习中,为何要经常对数据做归一化。
1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。
13. 哪些机器学习算法不需要做归一化处理?
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
14.什么是最大熵。
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵。
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问"每个面朝上的概率分别是多少",你会说是等概率,即各点出现的概率均为1/6。因为对这个"一无所知"的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
15.说说梯度下降法。梯度下降法找到的一定是下降最快的方向么?
梯度下降法的算法流程如下:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。梯度下降法并不是下降最快的方向,它只是目标函数在当前的点的切平面(当然高维问题不能叫平面)上下降最快的方向。在practical implementation中,牛顿方向(考虑海森矩阵)才一般被认为是下降最快的方向,可以达到superlinear的收敛速度。梯度下降类的算法的收敛速度一般是linear甚至sublinear的(在某些带复杂约束的问题)。
16. 牛顿法和梯度下降法有什么不同
详情参见:机器学习中常用的优化方法
17.怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感呢?
知乎回答:点击打开链接
18.衡量分类器的好坏?
这里首先要知道TP、FN(真的判成假的)、FP(假的判成真)、TN四种(可以画一个表格)。
几种常用的指标:
精度precision = TP/(TP+FP) = TP/~P (~p为预测为真的数量)
召回率 recall = TP/(TP+FN) = TP/ P
F1值: 2/F1 = 1/recall + 1/precision
ROC曲线:ROC空间是一个以伪阳性率(FPR,false positive rate)为X轴,真阳性率(TPR, true positive rate)为Y轴的二维坐标系所代表的平面。其中真阳率TPR = TP / P = recall, 伪阳率FPR = FP / N
19.什麽造成梯度消失问题? 推导一下
神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0,造成学习停止。
简而言之,就是sigmoid函数f(x)的导数为f(x)*(1-f(x)), 因为f(x)的输出在0-1之间,所以随着深度的增加,从顶端传过来的导数每次都乘以两个小于1的数,很快就变得特别特别小。
20. 数据不平衡问题。
这主要是由于数据分布不平衡造成的。解决方法如下:
- 采样,对小样本加噪声采样,对大样本进行下采样
- 数据生成,利用已知样本生成新的样本
- 进行特殊的加权,如在Adaboost中或者SVM中
- 采用对不平衡数据集不敏感的算法
- 改变评价标准:用AUC/ROC来进行评价
- 采用Bagging/Boosting/ensemble等方法
- 在设计模型的时候考虑数据的先验分布
21.带核的SVM为什么能分类非线性问题?
核函数的本质是两个函数的內积,而这个函数在SVM中可以表示成对于输入值的高维映射。注意核并不是直接对应映射,核只不过是一个內积 常用核函数及核函数的条件:
核函数选择的时候应该从线性核开始,而且在特征很多的情况下没有必要选择高斯核,应该从简单到难的选择模型。我们通常说的核函数指的是正定和函数,其充要条件是对于任意的x属于X,要求K对应的Gram矩阵要是半正定矩阵。
RBF核径向基,这类函数取值依赖于特定点间的距离,所以拉普拉斯核其实也是径向基核。
线性核:主要用于线性可分的情况
多项式核
22.特征比数据量还大时,选择什么样的分类器
如果训练集很小,那么高偏差/低方差分类器(如朴素贝叶斯分类器)要优于低偏差/高方差分类器(如k近邻分类器),因为后者容易过拟合。然而,随着训练集的增大,低偏差/高方差分类器将开始胜出(它们具有较低的渐近误差),因为高偏差分类器不足以提供准确的模型。你也可以认为这是生成模型与判别模型的区别。
23.随机森林的学习过程;随机森林中的每一棵树是如何学习的;随机森林学习算法中CART树的基尼指数是什么?
随机森林由LeoBreiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
24.归一化和标准化的区别?
归一化:
1)把数据变成(0,1)之间的小数
2)把有量纲表达式变成无量纲表达常见的有线性转换、对数函数转换、反余切函数转换等
标准化:
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
1 ) 最小-最大规范化(线性变换)
y=((x-MinValue) / (MaxValue-MinValue))(new_MaxValue-new_MinValue)+new_minValue
2)z-score规范化(或零-均值规范化)
y=(x-X的平均值)/X的标准差
3)小数定标规范化:通过移动X的小数位置来进行规范化
y= x/10的j次方 (其中,j使得Max(|y|) <1的最小整数
4).对数Logistic模式:
新数据=1/(1+e^(-原数据))
5)模糊量化模式
新数据=1/2+1/2sin[派3.1415/(极大值-极小值)
25.神经网络有哪些优化算法?
解决优化问题,有很多算法(最常见的就是梯度下降),这些算法也可以用于优化神经网络。每个深度学习库中,都包含了大量的优化算法,用于优化学习速率,让网络用最快的训练次数达到最优,还能防止过拟合。
keras中就提供了这样一些优化器[1]:
SGD:随机梯度下降
SGD+Momentum: 基于动量的SGD(在SGD基础上做过优化)
SGD+Nesterov+Momentum:基于动量,两步更新的SGD(在SGD+Momentum基础上做过优化)
Adagrad:自适应地为各个参数分配不同学习速率
Adadelta: 针对Adagrad问题,优化过的算法(在Adagrad基础上做过优化)
RMSprop:对于循环神经网络(RNNs)是最好的优化器(在Adadelta基础上做过优化)
Adam:对每个权值都计算自适应的学习速率(在RMSprop基础上做过优化)
Adamax:针对Adam做过优化的算法(在Adam基础上做过优化)
26.Dropout 怎么做,有什么用处,解释
可以通过阻止某些特征的协同作用来缓解。在每次训练的时候,每个神经元有百分之50的几率被移除,这样可以让一个神经元的出现不应该依赖于另外一个神经元。另外,我们可以把dropout理解为 模型平均。假设我们要实现一个图片分类任务,我们设计出了100000个网络,这100000个网络,我们可以设计得各不相同,然后我们对这100000个网络进行训练,训练完后我们采用平均的方法,进行预测,这样肯定可以提高网络的泛化能力,或者说可以防止过拟合,因为这100000个网络,它们各不相同,可以提高网络的稳定性。而所谓的dropout我们可以这么理解,这n个网络,它们权值共享,并且具有相同的网络层数(这样可以大大减小计算量)。我们每次dropout后,网络模型都可以看成是整个网络的子网络。(需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响)。
Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作
27.下面哪项操作能实现跟神经网络中Dropout的类似效果?
A.Boosting B.Bagging C.Stacking D.Mapping
解析:正确答案B。Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
28.你有哪些deep learning(rnn、cnn)调参的经验?
解析:
一、参数初始化
下面几种方式,随便选一个,结果基本都差不多。但是一定要做。否则可能会减慢收敛速度,影响收敛结果,甚至造成Nan等一系列问题。
下面的n_in为网络的输入大小,n_out为网络的输出大小,n为n_in或(n_in+n_out)*0.5
Xavier初始法论文:
http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
He初始化论文:
https://arxiv.org/abs/1502.01852
uniform均匀分布初始化:
w = np.random.uniform(low=-scale, high=scale, size=[n_in,n_out])
Xavier初始法,适用于普通激活函数(tanh,sigmoid):scale = np.sqrt(3/n)
He初始化,适用于ReLU:scale = np.sqrt(6/n)
normal高斯分布初始化:w = np.random.randn(n_in,n_out) * stdev # stdev为高斯分布的标准差,均值设为0
Xavier初始法,适用于普通激活函数 (tanh,sigmoid):stdev = np.sqrt(n)
He初始化,适用于ReLU:stdev = np.sqrt(2/n)
svd初始化:对RNN有比较好的效果。
二、数据预处理方式
zero-center ,这个挺常用的.X -= np.mean(X, axis = 0) # zero-centerX /= np.std(X, axis = 0) # normalize
PCA whitening,这个用的比较少.
三、训练技巧
要做梯度归一化,即算出来的梯度除以minibatch size
clip c(梯度裁剪): 限制最大梯度,其实是value = sqrt(w1^2+w2^2….),如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15
dropout对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd在我的大部分实验中,效果提升都非常明显.因此可能的话,建议一定要尝试一下。 dropout的位置比较有讲究, 对于RNN,建议放到输入->RNN与RNN->输出的位置.关于RNN如何用dropout,可以参考这篇论文:http://arxiv.org/abs/1409.2329
adam,adadelta等,在小数据上,我这里实验的效果不如sgd, sgd收敛速度会慢一些,但是最终收敛后的结果,一般都比较好。如果使用sgd的话,可以选择从1.0或者0.1的学习率开始,隔一段时间,在验证集上检查一下,如果cost没有下降,就对学习率减半. 我看过很多论文都这么搞,我自己实验的结果也很好. 当然,也可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好。
除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,可以用tanh或者relu之类的激活函数.1. sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。2. 输入0均值,sigmoid函数的输出不是0均值的。
rnn的dim和embdding size,一般从128上下开始调整. batch size,一般从128左右开始调整.batch size合适最重要,并不是越大越好。
word2vec初始化,在小数据上,不仅可以有效提高收敛速度,也可以可以提高结果。
四、尽量对数据做shuffle
LSTM 的forget gate的bias,用1.0或者更大的值做初始化,可以取得更好的结果,来自这篇论文:http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf, 我这里实验设成1.0,可以提高收敛速度.实际使用中,不同的任务,可能需要尝试不同的值.
Batch Normalization据说可以提升效果,不过我没有尝试过,建议作为最后提升模型的手段,参考论文:Accelerating Deep Network Training by Reducing Internal Covariate Shift
如果你的模型包含全连接层(MLP),并且输入和输出大小一样,可以考虑将MLP替换成Highway Network,我尝试对结果有一点提升,建议作为最后提升模型的手段,原理很简单,就是给输出加了一个gate来控制信息的流动,详细介绍请参考论文: http://arxiv.org/abs/1505.00387
来自@张馨宇的技巧:一轮加正则,一轮不加正则,反复进行。
五、Ensemble
Ensemble是论文刷结果的终极核武器,深度学习中一般有以下几种方式
同样的参数,不同的初始化方式
不同的参数,通过cross-validation,选取最好的几组
同样的参数,模型训练的不同阶段,即不同迭代次数的模型。
不同的模型,进行线性融合. 例如RNN和传统模型。
29.LSTM结构推导,为什么比RNN好?
解析:
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
30.激活函数对比。
31.为什么引入非线性激励函数?
解析:
第一,对于神经网络来说,网络的每一层相当于f(wx+b)=f(w'x),对于线性函数,其实相当于f(x)=x,那么在线性激活函数下,每一层相当于用一个矩阵去乘以x,那么多层就是反复的用矩阵去乘以输入。根据矩阵的乘法法则,多个矩阵相乘得到一个大矩阵。所以线性激励函数下,多层网络与一层网络相当。比如,两层的网络f(W1*f(W2x))=W1W2x=Wx。
第二,非线性变换是深度学习有效的原因之一。原因在于非线性相当于对空间进行变换,变换完成后相当于对问题空间进行简化,原来线性不可解的问题现在变得可以解了。
下图可以很形象的解释这个问题,左图用一根线是无法划分的。经过一系列变换后,就变成线性可解的问题了。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)
32.为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?这样做的目的是什么?
sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。
tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
33.如何解决RNN梯度爆炸和弥散的问题?
解析:
为了解决梯度爆炸问题,Thomas Mikolov首先提出了一个简单的启发性的解决方案,就是当梯度大于一定阈值的的时候,将它截断为一个较小的数。具体如算法1所述:
算法:当梯度爆炸时截断梯度(伪代码)
下图可视化了梯度截断的效果。它展示了一个小的rnn(其中W为权值矩阵,b为bias项)的决策面。这个模型是一个一小段时间的rnn单元组成;实心箭头表明每步梯度下降的训练过程。当梯度下降过程中,模型的目标函数取得了较高的误差时,梯度将被送到远离决策面的位置。截断模型产生了一个虚线,它将误差梯度拉回到离原始梯度接近的位置。
梯度爆炸,梯度截断可视化
为了解决梯度弥散的问题,我们介绍了两种方法。第一种方法是将随机初始化
改为一个有关联的矩阵初始化。第二种方法是使用ReLU(Rectified Linear Units)代替sigmoid函数。ReLU的导数不是0就是1.因此,神经元的梯度将始终为1,而不会当梯度传播了一定时间之后变小。
34.如何解决梯度消失和梯度膨胀?
解析:
(1)梯度消失:
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0
可以采用ReLU激活函数有效的解决梯度消失的情况,也可以用Batch Normalization解决这个问题。关于深度学习中 Batch Normalization为什么效果好?
(2)梯度膨胀
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都大于1的话,在经过足够多层传播之后,误差对输入层的偏导会趋于无穷大
可以通过激活函数来解决,或用Batch Normalization解决这个问题。
35.深度学习常用方法。
解析:
全连接DNN(相邻层相互连接、层内无连接):
AutoEncoder(尽可能还原输入)、Sparse Coding(在AE上加入L1规范)、RBM(解决概率问题)—–>特征探测器——>栈式叠加 贪心训练
RBM—->DBN
解决全连接DNN的全连接问题—–>CNN
解决全连接DNN的无法对时间序列上变化进行建模的问题—–>RNN—解决时间轴上的梯度消失问题——->LSTM
DNN是传统的全连接网络,可以用于广告点击率预估,推荐等。其使用embedding的方式将很多离散的特征编码到神经网络中,可以很大的提升结果。
CNN主要用于计算机视觉(Computer Vision)领域,CNN的出现主要解决了DNN在图像领域中参数过多的问题。同时,CNN特有的卷积、池化、batch normalization、Inception、ResNet、DeepNet等一系列的发展也使得在分类、物体检测、人脸识别、图像分割等众多领域有了长足的进步。同时,CNN不仅在图像上应用很多,在自然语言处理上也颇有进展,现在已经有基于CNN的语言模型能够达到比LSTM更好的效果。在最新的AlphaZero中,CNN中的ResNet也是两种基本算法之一。
GAN是一种应用在生成模型的训练方法,现在有很多在CV方面的应用,例如图像翻译,图像超清化、图像修复等等。
RNN主要用于自然语言处理(Natural Language Processing)领域,用于处理序列到序列的问题。普通RNN会遇到梯度爆炸和梯度消失的问题。所以现在在NLP领域,一般会使用LSTM模型。在最近的机器翻译领域,Attention作为一种新的手段,也被引入进来。
除了DNN、RNN和CNN外, 自动编码器(AutoEncoder)、稀疏编码(Sparse Coding)、深度信念网络(DBM)、限制玻尔兹曼机(RBM)也都有相应的研究。
36.神经网络中激活函数的真正意义?一个激活函数需要具有哪些必要的属性?还有哪些属性是好的属性但不必要的?
解析:
(1)非线性:即导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
(2)几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响[1]。
(3)计算简单:非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
(4)非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU[3]和PReLU[4]的提出正是为了解决这一问题。
(5)单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
(6)输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响[1])、LSTM里的gate函数。
(7)接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单[5][4]。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet[6]和RNN中的LSTM。
(8)参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout[7],尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
(9)归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU[8],主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization[9]。
36.梯度爆炸会引发什么问题?
解析:
在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
梯度爆炸导致学习过程不稳定。—《深度学习》,2016。
在循环神经网络中,梯度爆炸会导致网络不稳定,无法利用训练数据学习,最好的结果是网络无法学习长的输入序列数据。
37.如何确定是否出现梯度爆炸?
解析:
训练过程中出现梯度爆炸会伴随一些细微的信号,如:
模型无法从训练数据中获得更新(如低损失)。
模型不稳定,导致更新过程中的损失出现显著变化。
训练过程中,模型损失变成 NaN。
如果你发现这些问题,那么你需要仔细查看是否出现梯度爆炸问题。
以下是一些稍微明显一点的信号,有助于确认是否出现梯度爆炸问题。
训练过程中模型梯度快速变大。
训练过程中模型权重变成 NaN 值。
训练过程中,每个节点和层的误差梯度值持续超过 1.0。
38.如何修复梯度爆炸问题?
解析:
有很多方法可以解决梯度爆炸问题,本节列举了一些最佳实验方法。
(1) 重新设计网络模型
在深度神经网络中,梯度爆炸可以通过重新设计层数更少的网络来解决。
使用更小的批尺寸对网络训练也有好处。
在循环神经网络中,训练过程中在更少的先前时间步上进行更新(沿时间的截断反向传播,truncated Backpropagation through time)可以缓解梯度爆炸问题。
(2)使用 ReLU 激活函数
在深度多层感知机神经网络中,梯度爆炸的发生可能是因为激活函数,如之前很流行的 Sigmoid 和 Tanh 函数。
使用 ReLU 激活函数可以减少梯度爆炸。采用 ReLU 激活函数是最适合隐藏层的新实践。
(3)使用长短期记忆网络
在循环神经网络中,梯度爆炸的发生可能是因为某种网络的训练本身就存在不稳定性,如随时间的反向传播本质上将循环网络转换成深度多层感知机神经网络。
使用长短期记忆(LSTM)单元和相关的门类型神经元结构可以减少梯度爆炸问题。
采用 LSTM 单元是适合循环神经网络的序列预测的最新最好实践。
(4)使用梯度截断(Gradient Clipping)
在非常深且批尺寸较大的多层感知机网络和输入序列较长的 LSTM 中,仍然有可能出现梯度爆炸。如果梯度爆炸仍然出现,你可以在训练过程中检查和限制梯度的大小。这就是梯度截断。
处理梯度爆炸有一个简单有效的解决方案:如果梯度超过阈值,就截断它们。
——《Neural Network Methods in Natural Language Processing》,2017.
具体来说,检查误差梯度的值是否超过阈值,如果超过,则截断梯度,将梯度设置为阈值。
梯度截断可以一定程度上缓解梯度爆炸问题(梯度截断,即在执行梯度下降步骤之前将梯度设置为阈值)。
——《深度学习》,2016.
在 Keras 深度学习库中,你可以在训练之前设置优化器上的 clipnorm 或 clipvalue 参数,来使用梯度截断。
默认值为 clipnorm=1.0 、clipvalue=0.5。详见:https://keras.io/optimizers/。
(5)使用权重正则化(Weight Regularization)
如果梯度爆炸仍然存在,可以尝试另一种方法,即检查网络权重的大小,并惩罚产生较大权重值的损失函数。该过程被称为权重正则化,通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。
对循环权重使用 L1 或 L2 惩罚项有助于缓解梯度爆炸。
——On the difficulty of training recurrent neural networks,2013.
在 Keras 深度学习库中,你可以通过在层上设置 kernel_regularizer 参数和使用 L1 或 L2 正则化项进行权重正则化。
39.在神经网络中,有哪些办法防止过拟合?
解析:
缓解过拟合:
① Dropout
② 加L1/L2正则化
③ BatchNormalization
④ 网络bagging
40.CNN是什么,CNN关键的层有哪些?
解析:
CNN是卷积神经网络,具体详见此文:https://blog.csdn.net/v_july_v/article/details/51812459。
其关键层有:
① 输入层,对数据去均值,做data augmentation等工作
② 卷积层,局部关联抽取feature
③ 激活层,非线性变化
④ 池化层,下采样
⑤ 全连接层,增加模型非线性
⑥ 高速通道,快速连接
⑦Batch Normalization(BN)层,缓解梯度弥散
41.GRU是什么?GRU对LSTM做了哪些改动?
解析:
GRU是Gated Recurrent Units,是循环神经网络的一种。
GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将hidden state 传给下一个单元,而LSTM用memory cell 把hidden state 包装起来。
42.请简述应当从哪些方向上思考和解决深度学习中出现的的over fitting问题?
解析:
如果模型的训练效果不好,可先考察以下几个方面是否有可以优化的地方。
(1)选择合适的损失函数(choosing proper loss )
神经网络的损失函数是非凸的,有多个局部最低点,目标是找到一个可用的最低点。非凸函数是凹凸不平的,但是不同的损失函数凹凸起伏的程度不同,例如下述的平方损失和交叉熵损失,后者起伏更大,且后者更容易找到一个可用的最低点,从而达到优化的目的。
- Square Error(平方损失)
- Cross Entropy(交叉熵损失)
(2)选择合适的Mini-batch size
采用合适的Mini-batch进行学习,使用Mini-batch的方法进行学习,一方面可以减少计算量,一方面有助于跳出局部最优点。因此要使用Mini-batch。更进一步,batch的选择非常重要,batch取太大会陷入局部最小值,batch取太小会抖动厉害,因此要选择一个合适的batch size。
(3)选择合适的激活函数(New activation function)
使用激活函数把卷积层输出结果做非线性映射,但是要选择合适的激活函数。
- Sigmoid函数是一个平滑函数,且具有连续性和可微性,它的最大优点就是非线性。但该函数的两端很缓,会带来猪队友的问题,易发生学不动的情况,产生梯度弥散。
- ReLU函数是如今设计神经网络时使用最广泛的激活函数,该函数为非线性映射,且简单,可缓解梯度弥散。
(4)选择合适的自适应学习率(apdative learning rate)
- 学习率过大,会抖动厉害,导致没有优化提升
- 学习率太小,下降太慢,训练会很慢
(5)使用动量(Momentum)
在梯度的基础上使用动量,有助于冲出局部最低点。
如果以上五部分都选对了,效果还不好,那就是产生过拟合了,可使如下方法来防止过拟合,分别是
- 1.早停法(earyly stoping)。早停法将数据分成训练集和验证集,训练集用来计算梯度、更新权重和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
- 2.权重衰减(Weight Decay)。到训练的后期,通过衰减因子使权重的梯度下降地越来越缓。
- 3.Dropout。Dropout是正则化的一种处理,以一定的概率关闭神经元的通路,阻止信息的传递。由于每次关闭的神经元不同,从而得到不同的网路模型,最终对这些模型进行融合。
- 4.调整网络结构(Network Structure)。
43. Recursive vs. Recurrent neural networks
两者都是递归神经网络,只不过前者在空间上递归,后者在时间上递归。中文有时会把后者翻译为“循环神经网络”,但这明显混淆了等级,令人误解。
它们各有各的优缺点,Recursive neural net需要分析器来得到句法树,而Recurrent neural net只能捕捉“前缀”“上文”无法捕捉更小的单位。
但人们还是更倾向于用后者,LSTM之类。因为训练Recursive neural net之前,你需要句法树;句法树是一个离散的决策结果,无法连续地影响损失函数,也就无法简单地利用反向传播训练Recursive neural net。另外,复杂的结构也导致Recursive neural net不易在GPU上优化。
44.Selective search的主要思想
解析:
1 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
2 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
3 输出所有曾经存在过的区域,所谓候选区域
45.CNN的特点及优势
解析:
CNN使用范围是具有局部空间相关性的数据,比如图像,自然语言,语音
局部连接:可以提取局部特征。
权值共享:减少参数数量,因此降低训练难度(空间、时间消耗都少了)。可以完全共享,也可以局部共享(比如对人脸,眼睛鼻子嘴由于位置和样式相对固定,可以用和脸部不一样的卷积核)
降维:通过池化或卷积stride实现。
多层次结构:将低层次的局部特征组合成为较高层次的特征。不同层级的特征可以对应不同任务。
46.深度学习中有什么加快收敛、降低训练难度的方法?
解析:
瓶颈结构
残差
学习率、步长、动量
优化方法
预训练
47.神经网络中会用到批量梯度下降(BGD)吗?为什么用随机梯度下降(SGD)?
解析:
1)一般不用BGD
2)a. BGD每次需要用到全量数据,计算量太大
b. 引入随机因素,即便陷入局部极小,梯度也可能不为0,这样就有机会跳出局部极小继续搜索(可以作为跳出局部极小的一种方式,但也可能跳出全局最小。还有解决局部极小的方式:多组参数初始化、使用模拟退火技术)
48.下列哪一项属于特征学习算法(representation learning algorithm)?
A、K近邻算法
B、随机森林
C、神经网络
D、都不属于
正确答案是:C
解析:
神经网络会将数据转化为更适合解决目标问题的形式,我们把这种过程叫做特征学习。
49.
混沌度(Perplexity)是一种常见的应用在使用深度学习处理NLP问题过程中的评估技术,关于混沌度,哪种说法是正确的?
A、混沌度没什么影响
B、混沌度越低越好
C、混沌度越高越好
D、混沌度对于结果的影响不一定
正确答案是: B
50.为什么更深的网络更好?
更深的神经网络仅需更少的参数就可以表达许多重要的函数类。
51.深度学习中有什么加快收敛/降低训练难度的方法?
瓶颈结构
残差
学习率、步长、动量
优化方法
预训练
52. Batch Normalization的好处?
Batch Normalization简称BN,其中,Normalization是数据标准化或归一化、规范化,Batch可以理解为批量,加起来就是批量标准化。解决在训练过程中中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快训练速度。
同激活函数层、池化层等一样,BN也属于网络的一层。它是一个可学习、有参数的网络层。
53.神经网络中会用到批量梯度下降(BGD)吗?为什么用随机梯度下降(SGD)?
1)一般不用BGD
2)a. BGD每次需要用到全量数据,计算量太大
b. 引入随机因素,即便陷入局部极小,梯度也可能不为0,这样就有机会跳出局部极小继续搜索(可以作为跳出局部极小的一种方式,但也可能跳出全局最小。还有解决局部极小的方式:多组参数初始化、使用模拟退火技术)
54.在训练神经网络时,损失函数(loss)在最初的几个epochs时没有下降,可能的原因是?
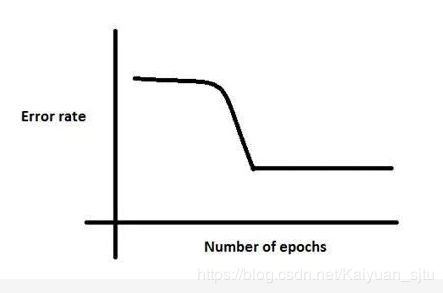
解析:
1.学习率太小;
2、正则参数太大;
3.陷入局部最小值
55.下列的哪种方法可以用来降低深度学习模型的过拟合问题?
1、增加更多数据;
2、使用数据扩增技术(data augmentation);
3、使用归纳性更好的架构;
4、正规化数据;
5、降低架构的复杂度
56.假设我们用Lasso回归拟合一个有100个特征值(X1,X2…X100)的数据集,现在,我们重新调节其中一个值,将它乘10(将它视作X1),并再次拟合同一规则化参数。下列哪一项正确?
A、X1很可能被模型排除
B、X1很可能被包含在模型内
C、很难说
D、都不对
解析: B
大特征值 =>小相关系数=>更少Lasso penalty=>更可能被保留
57.假定你想将高维数据映射到低维数据中,那么最出名的降维算法是 PCA 和 t-SNE。现在你将这两个算法分别应用到数据「X」上,并得到数据集「X_projected_PCA」,「X_projected_tSNE」。下面哪一项对「X_projected_PCA」和「X_projected_tSNE」的描述是正确的?
A、X_projected_PCA 在最近邻空间能得到解释
B、X_projected_tSNE 在最近邻空间能得到解释
C、两个都在最近邻空间能得到解释
D、两个都不能在最近邻空间得到解释
解析:A
t-SNE算法考虑最近邻点而减少数据维度。所以在使用t-SNE之后,所降的维可以在最近邻空间得到解释。但PCA不能
58. 在训练逻辑回归之前是否需要对特征进行标准化?为啥?
解析: 不需要。
进行标准化的原因主要是由于变量的量纲不同,导致最后模型的表现不可信。
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。常用的标准化有:Min-Max scaling, Z score
需要标准化的算法:SVM、PAC、KNN、岭回归和Lasso等;
不需要标准化的算法:线性回归、逻辑回归、决策树和其他一些集成方法
59.关于PCA和LDA,下列哪个选项是真的?
A、LDA明确地尝试对数据类别之间的差异进行建模,而PCA没有。
B、两者都试图模拟数据类之间的差异。
C、PCA明确地试图对数据类别之间的差异进行建模,而LDA没有。
D、两者都不试图模拟数据类之间的差异。
解析:A
1.LDA和PCA都是线性变换技术
2. LDA是有监督的,而PCA是无监督的
3. PCA最大化数据的方差,而LDA最大化不同类之间的分离
60.决策树的父节点和子节点的熵的大小关系是什么?
解析:根据具体情况而定。
在ID3中,选择当前最优分类的属性的准则是Information gain最大,即使IG(A, S) = H(S) - sigma[p(t)H(t)]最大
其中,A为属性,H(S)为父节点中样本的entropy,p(t)为属性A取值为t的比例,H(t)为A=t的子节点中样本的entropy。
由于p(t)的存在,H(t)可能大于H(S),也可能小于H(S)
61.线性回归的五个基本假设是什么?
解析:
1、随机误差项是一个期望值为0的随机变量
2、对于解释变量的所有观测值,随机误差项有相同的方差
3、随机误差项彼此独立
4、自变量(X1,X2)之间应相互独立
5、随机误差服从正态分布
62.符号集 a 、 b 、 c 、 d ,它们相互独立,相应概率为 1/2 、 1/4 、 1/8/ 、 1/16 ,其中包含信息量最小的符号是( )
解析: A
熵的表达式:
熵越大,随机变量的不确定性越大,则确定该随机变量后得到的信息量越大。
知乎问题有一个答案:每天读同一本书,获得的知识多,还是每天读不同的书过得的知识多? 信息熵H(X)=I(X;X)又叫自信息。 熵越大,越无序,越趋向于每天读不同的书,信息量也越大。
63.在大规模的语料中,挖掘词的相关性是一个重要的问题。以下哪一个信息不能用于确定两个词的相关性。
A、互信息
B、最大熵
C、卡方检验
D、最大似然比
解析:B
最大熵代表了整体分布的信息,通常具有最大熵的分布作为该随机变量的分布,不能体现两个词的相关性,
卡方是检验两类事务发生的相关性
常采用特征选择方法。常见的六种特征选择方法: 1)DF(Document Frequency) 文档频率 DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性 2)MI(Mutual Information) 互信息法 互信息法用于衡量特征词与文档类别直接的信息量。 如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。 相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。 3)(Information Gain) 信息增益法 通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。 4)CHI(Chi-square) 卡方检验法 利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的 如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。 5)WLLR(Weighted Log Likelihood Ration)加权对数似然 6)WFO(Weighted Frequency and Odds)加权频率和可能性
64.假设你使用 log-loss 函数作为评估标准。下面这些选项,哪些是对作为评估标准的 log-loss 的正确解释。
A、如果一个分类器对不正确的分类很自信,log-loss 会严重的批评它
B、对一个特别的观察而言,分类器为正确的类别分配非常小的概率,然后对 log-loss 的相应分布会非常大
C、log-loss 越低,模型越好
D、以上都是
解析:以上都是
65.两个变量的Person相关性系数为零,但这两个变量的值同样可以相关。
解析:正确。Pearson相关系数只能衡量线性相关性,但无法衡量非线性关系。如y=x^2,x和y有很强的非线性关系。
66.下列时间序列模型中,哪一个模型可以较好地拟合波动性的分析和预测。
A、AR模型
B、MA模型
C、ARMA模型
D、GARCH模型
解析:D
AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值。
MA模型(moving average model)滑动平均模型,其中使用趋势移动平均法建立直线趋势的预测模型。
ARMA模型(auto regressive moving average model)自回归滑动平均模型,模型参量法高分辨率谱分析方法之一。这种方法是研究平稳随机过程有理谱的典型方法。它比AR模型法与MA模型法有较精确的谱估计及较优良的谱分辨率性能,但其参数估算比较繁琐。
GARCH模型称为广义ARCH模型,是ARCH模型的拓展,由Bollerslev(1986)发展起来的。它是ARCH模型的推广。GARCH(p,0)模型,相当于ARCH(p)模型。GARCH模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
67.在Logistic regression中,同时加入L1和L2范数,会有什么效果?
A、以做特征选择,并在一定程度上防止过拟合
B、能解决维度灾难问题
C、能加快计算速度
D、可以获得更准确的结果
解析:A/B/C
L1范数具有稀疏解的特性,但是要注意的是,L1没有选到的特征不代表不重要,原因是两个高相关性的特征可能只保留一个。如果需要确定哪个特征重要,再通过交叉验证。它的优良性质是能产生稀疏性,导致 W 中许多项变成零。 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。所以能加快计算速度和缓解维数灾难.
在代价函数后面加上正则项,L1即是Losso回归,L2是岭回归。L1范数是指向量中各个元素绝对值之和,用于特征选择。L2范数 是指向量各元素的平方和然后求平方根,用于 防止过拟合,提升模型的泛化能力。
68.如何在一个数据集上选择重要的变量?
解析:以下是可以选择变量的方法:
1、选择重要的变量之前除去相关变量;
2、用线性回归然后基于P值选择变量
3、使用前向选择,后向选择,逐步选择
4、使用随机森林和XGBoost,然后画出变量重要性图
5、使用Lasso回归
6、测量可用的特征集的信息增益,并相应地选择前n个特征量
69.KNN和k-means有什么区别?
解析:这两种算法的根本区别是:KNN是有监督学习算法(分类或者回归)而kmeans本质上是非监督学习(聚类)。
KMEAN算法把一个数据集分割成簇,使得形成的簇是同构的,每个簇里的点相互靠近。该算法试图维持这些簇之间有足够的可分离性。由于无监督的性质,这些簇没有任何标签。NN算法尝试基于其k(可以是任何数目)个周围邻居来对未标记的观察进行分类。它也被称为懒惰学习法,因为它涉及最小的模型训练。因此,它不用训练数据对未看见的数据集进行泛化。
70.对于维度极低的特征,选择线性还是非线性分类器?
解析:
非线性分类器。低维空间可能很多特征都跑到一起了,导致线性不可分。
(1)如果feature的数量很大,跟样本差不多大,这时候选用LR或者Linear Kernel的SVM
(2)如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
(3)如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。
71.KNN最近邻分类算法的过程?
解析:
- 计算测试样本与训练样本中每个样本点的距离(欧氏距离、马氏距离等);
- 对上面的所有距离进行排序;
- 选出前k个最小距离的样本;
- 根据这k个样本的标签进行投票,得到最后的分类类别
72.如何理解对偶问题?
解析:对偶问题起源于这样的思想:原始问题比较难以求解另外一个问题,希望得到原始问题的最优解或者下界(对于最小化问题)。主要的方式为增加变量,将约束写入目标函数来实现。
https://www.zhihu.com/question/27057384
73.随即森林如何评估特征重要性?
解析:衡量变量重要性的方法有两种,Decrease GINI 和 Decrease Accuracy:
1)Decrease GINI: 对于回归问题,直接使用argmax(VarVarLeft,VarRight)作为评判标准,即当前节点训练集的方差Var减去左节点的方差VarLeft和右节点的方差VarRight。
2) Decrease Accuracy:对于一棵树Tb(x),我们用OOB样本可以得到测试误差1;然后随机改变OOB样本的第j列:保持其他列不变,对第j列进行随机的上下置换,得到误差2。至此,我们可以用误差1-误差2来刻画变量j的重要性。基本思想就是,如果一个变量j足够重要,那么改变它会极大的增加测试误差;反之,如果改变它测试误差没有增大,则说明该变量不是那么的重要。74.
74.xgboost如何寻找最优特征?是有放回还是无放回的呢?
解析:
xgboost在训练的过程中给出各个特征的增益评分,最大增益的特征会被选出来作为分裂依据, 从而记忆了每个特征对在模型训练时的重要性 -- 从根到叶子中间节点涉及某特征的次数作为该特征重要性排序.
xgboost属于boosting集成学习方法, 样本是不放回的, 因而每轮计算样本不重复. 另一方面, xgboost支持子采样, 也就是每轮计算可以不使用全部样本, 以减少过拟合. 进一步地, xgboost 还有列采样, 每轮计算按百分比随机采样一部分特征, 既提高计算速度又减少过拟合。
75. L1和L2正则先验分别服从什么分布?
解析:L1是拉普拉斯分布,L2是高斯分布。
先验就是优化的起跑线, 有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
76. 为什么xgboost要用泰勒展开?优势在哪?
解析:
xgboost使用了一阶和二阶偏导,二阶导数有利于梯度下降地更准更快。使用泰勒展开取得函数做自变量的二阶导数形式,可以在不选定损失函数具体形式的情况下,仅仅依靠输入数据的值就可以进行叶子分裂优化计算。本质上也就把损失函数的选取和模型算法优化分开了。这种去耦合增加了xgboost的适用性,使得它按需选取损失函数,可以用于分类,也可以用于回归。
77.什么是共轭梯度法?
解析:
共轭梯度法是介于梯度下降法(最速下降法)与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hessian矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有逐步收敛性,稳定性高,而且不需要任何外来参数。
78.为什么树形结构不需要归一化?
解析:
数值缩放,不影响分裂点位置。因为第一步都是按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。对于线性模型,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,这样运用梯度下降时候,损失等高线是一个椭圆的形状,这样我想迭代到最优点,就需要很多次迭代,但是如果进行了归一化,那么等高线就是圆形的,那么SGD就会往原点迭代,需要的迭代次数较少。
另外,注意树模型是不能进行梯度下降的,因为树模型是阶跃的,阶跃点是不可导的,并且求导没意义,所以树模型(回归树)寻找最优点事通过寻找最优分裂点完成的。
79.对应Gradient Boosting tree算法,以下说法正确的是:
A. 当增加最小样本分裂个数,我们可以抵制过拟合
B. 当增加最小样本分裂个数,会导致过拟合
C. 当我们减少训练单个学习器的样本个数,我们可以降低variance
D. 当我们减少训练单个学习器的样本个数,我们可以降低bias
解析: A和C
最小样本分裂个数:分裂该节点时需要的样本数。如果所需样本越少,说明越精确,越容易导致过拟合;
当训练单个学习器的样本数减少,说明数据不足模型的准确度降低,所以bias偏差增大,方差variance减小。
80.对于信息增益, 决策树分裂节点, 下面说法正确的是:
1. 纯度高的节点需要更多的信息去区分
2. 信息增益可以用”1比特-熵”获得
3. 如果选择一个属性具有许多归类值, 那么这个信息增益是有偏差的
解析: 2和3
81.在一个n维的空间中, 最好的检测outlier(离群点)的方法是:
A. 作正态分布概率图
B. 作盒形图
C. 马氏距离
D. 作散点图
解析: C
82.下列哪个不是dense vector(来自于word2vec Glove)相对于one-hot向量的优势?
A. Models using dense word vectors generalize better to unseen words than those using sparse vectors.
B. Models using dense word vectors generalize better to rare words than those using sparse vectors.
C. Dense word vectors encode similarity between words while sparse vectors do not.
D. Dense word vectors are easier to include as features in machine learning systems than sparse vectors.
解析:A. sparse represetation 和 dense representation对于未见词都没有表达,因此两者对于未登录词的表现是一样的。
83.下列关于语言模型的说法正确的是?
A. 神经网路窗口模型可以共享参数
B.神经网络窗口模型受限于稀疏问题,而n-gram语言模型不会
C.RNN语言模型中的参数数量会随着time step的推进而变多
D.神经网络窗口模型可以并行化训练,而RNN语言模型不可以
解析:Gradients must flow through each time step for RNNs whereas for neural window-based models can perform its forward- and back-propagation in parallel
84.在自然语言处理中,什么是封闭和开放测试?
解析:封闭测试条件,要求不得使用训练集之外的语言资源,否则相应结果则是开放测试类别。区分封闭和开放测试的一个主要目的,是分辨机器学习的性能提升的确 是模型自身的改进,而非其它。