【目标识别】深度学习进行目标识别的资源列表
【目标识别】深度学习进行目标识别的资源列表:O网页链接 包括RNN、MultiBox、SPP-Net、DeepID-Net、Fast R-CNN、DeepBox、MR-CNN、Faster R-CNN、YOLO、DenseBox、SSD、Inside-Outside Net、G-CNN等。
Papers
[td]
[td]
[td]
[td]
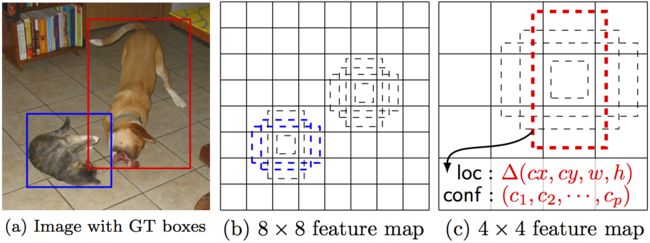
Papers
Deep Neural Networks for Object Detection
- paper: http://papers.nips.cc/paper/5207-deep-neural-networks-for-object-detection.pdf
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
[td]
- intro: A deep version of the sliding window method, predicts bounding box directly from each location of the topmost feature map after knowing the confidences of the underlying object categories.
- arXiv: http://arxiv.org/abs/1312.6229
- code: https://github.com/sermanet/OverFeat
Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)
[td]
- arXiv: http://arxiv.org/abs/1311.2524
- slides: http://www.image-net.org/challenges/LSVRC/2013/slides/r-cnn-ilsvrc2013-workshop.pdf
- slides: http://www.cs.berkeley.edu/~rbg/slides/rcnn-cvpr14-slides.pdf
- code: https://github.com/rbgirshick/rcnn
- notes: http://zhangliliang.com/2014/07/23/paper-note-rcnn/
- caffe-pr(“Make R-CNN the Caffe detection example”):https://github.com/BVLC/caffe/pull/482
Scalable Object Detection using Deep Neural Networks (MultiBox)
- intro: Train a CNN to predict Region of Interest.
- arXiv: http://arxiv.org/abs/1312.2249
- code: https://github.com/google/multibox
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[td]
- arXiv: http://arxiv.org/abs/1406.4729
- code: https://github.com/ShaoqingRen/SPP_net
- notes: http://zhangliliang.com/2014/09/13/paper-note-sppnet/
Learning Rich Features from RGB-D Images for Object Detection and Segmentation
- arxiv: http://arxiv.org/abs/1407.5736
Scalable, High-Quality Object Detection
- arXiv: http://arxiv.org/abs/1412.1441
- code: https://github.com/google/multibox
DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection
[td]
- arXiv: http://arxiv.org/abs/1412.5661
Object Detection Networks on Convolutional Feature Maps
[td]
- arXiv: http://arxiv.org/abs/1504.06066
Improving Object Detection with Deep Convolutional Networks via Bayesian Optimization and Structured Prediction
[td]
- arXiv: http://arxiv.org/abs/1504.03293
- slides: http://www.ytzhang.net/files/publications/2015-cvpr-det-slides.pdf
- code: https://github.com/YutingZhang/fgs-obj
Fast R-CNN
[td]
- arXiv: http://arxiv.org/abs/1504.08083
- slides: http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
- github: https://github.com/rbgirshick/fast-rcnn
- webcam demo: https://github.com/rbgirshick/fast-rcnn/pull/29
- notes: http://zhangliliang.com/2015/05/17/paper-note-fast-rcnn/
- notes: http://blog.csdn.net/linj_m/article/details/48930179
- github(“Train Fast-RCNN on Another Dataset”): https://github.com/zeyuanxy/fast-rcnn/tree/master/help/train
DeepBox: Learning Objectness with Convolutional Networks
- arXiv: http://arxiv.org/abs/1505.02146
- github: https://github.com/weichengkuo/DeepBox
Object detection via a multi-region & semantic segmentation-aware CNN model (MR-CNN)
[td]
- arXiv: http://arxiv.org/abs/1505.01749
- code: “Pdf and code will appear here shortly – stay tuned”
http://imagine.enpc.fr/~komodakn/ - notes: http://zhangliliang.com/2015/05/17/paper-note-ms-cnn/
- notes: http://blog.cvmarcher.com/posts/2015/05/17/multi-region-semantic-segmentation-aware-cnn/
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(NIPS 2015)
[td]
- arXiv: http://arxiv.org/abs/1506.01497
- github: https://github.com/ShaoqingRen/faster_rcnn
- github: https://github.com/rbgirshick/py-faster-rcnn
You Only Look Once: Unified, Real-Time Object Detection(YOLO)
- intro: YOLO uses the whole topmost feature map to predict both confidences for multiple categories and bounding boxes (which are shared for these categories).
- arXiv: http://arxiv.org/abs/1506.02640
- code: http://pjreddie.com/darknet/yolo/
- github: https://github.com/pjreddie/darknet
- reddit:https://www.reddit.com/r/MachineLearning/comments/3a3m0o/realtime_object_detection_with_yolo/
- github(YOLO_tensorflow): https://github.com/gliese581gg/YOLO_tensorflow
R-CNN minus R
- arXiv: http://arxiv.org/abs/1506.06981
DenseBox: Unifying Landmark Localization with End to End Object Detection
- arXiv: http://arxiv.org/abs/1509.04874
- demo: http://pan.baidu.com/s/1mgoWWsS
- KITTI result: http://www.cvlibs.net/datasets/kitti/eval_object.php
SSD: Single Shot MultiBox Detector
- arXiv: http://arxiv.org/abs/1512.02325
- github: https://github.com/weiliu89/caffe/tree/ssd
- video: http://weibo.com/p/2304447a2326da963254c963c97fb05dd3a973
Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks
Detection results on VOC 2007 test:
[td]
Detection results on VOC 2012 test:
[td]
- intro: “0.8s per image on a Titan X GPU (excluding proposal generation) without two-stage bounding-box regression and 1.15s per image with it”.
- arxiv: http://arxiv.org/abs/1512.04143
- slides: http://www.seanbell.ca/tmp/ion-coco-talk-bell2015.pdf
- coco-leaderboard: http://mscoco.org/dataset/#detections-leaderboard
G-CNN: an Iterative Grid Based Object Detector
- arxiv: http://arxiv.org/abs/1512.07729
Learning Deep Features for Discriminative Localization
- homepage: http://cnnlocalization.csail.mit.edu/
- arxiv: http://arxiv.org/abs/1512.04150
- github(Tensorflow): https://github.com/jazzsaxmafia/Weakly_detector
Factors in Finetuning Deep Model for object detection
- arxiv: http://arxiv.org/abs/1601.05150
We don’t need no bounding-boxes: Training object class detectors using only human verification
- arxiv: http://arxiv.org/abs/1602.08405
A MultiPath Network for Object Detection
- arxiv: http://arxiv.org/abs/1604.02135
Beyond Bounding Boxes: Precise Localization of Objects in Images (PhD Thesis)
- homepage: http://www.eecs.berkeley.edu/Pubs/TechRpts/2015/EECS-2015-193.html
- phd-thesis: http://www.eecs.berkeley.edu/Pubs/TechRpts/2015/EECS-2015-193.pdf
- github(“SDS using hypercolumns”): https://github.com/bharath272/sds
T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
- arxiv: http://arxiv.org/abs/1604.02532
- github: https://github.com/myfavouritekk/T-CNN
Training Region-based Object Detectors with Online Hard Example Mining
- arxiv: http://arxiv.org/abs/1604.03540
End-to-end people detection in crowded scenes
- arXiv: http://arxiv.org/abs/1506.04878
- code: https://github.com/Russell91/reinspect
- ipn:http://nbviewer.ipython.org/github/Russell91/ReInspect/blob/master/evaluation_reinspect.ipynb
Convolutional Feature Maps: Elements of efficient (and accurate) CNN-based object detection
- slides: http://research.microsoft.com/en-us/um/people/kahe/iccv15tutorial/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
TensorBox: a simple framework for training neural networks to detect objects in images
- intro: “The basic model implements the simple and robust GoogLeNet-OverFeat algorithm. We additionally provide an implementation of the ReInspect algorithm”
- github: https://github.com/Russell91/TensorBox
Object detection in torch: Implementation of some object detection frameworks in torch
- github: https://github.com/fmassa/object-detection.torch
Convolutional Neural Networks for Object Detection
http://rnd.azoft.com/convolutional-neural-networks-object-detection/
转自:http://www.thinkface.cn/thread-4434-1-1.html