第十五天 - Hive自定义函数扩展 - Sqoop安装配置、基本操作 - Sqoop结合Web.md
第十五天 - Hive自定义函数扩展 - Sqoop安装配置、基本操作 - Sqoop结合Web
文章目录
- 第十五天 - Hive自定义函数扩展 - Sqoop安装配置、基本操作 - Sqoop结合Web
- 一、Hive自定义函数扩展
- 二、Sqoop安装
- 功能概述
- 安装配置
- 测试连接
- 三、Sqoop基本操作
- 将MySQL表数据导入到HDFS中
- 四、Sqoop结合JavaWeb
- 运行效果
一、Hive自定义函数扩展
UDF:输入一行数据,输出一行数据
UDAF:输入多行数据,输出一行数据
例:拼接字符串
Concat.java
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory.ObjectInspectorOptions;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
public class Concat extends AbstractGenericUDAFResolver {
public static class Evaluator extends GenericUDAFEvaluator{
PrimitiveObjectInspector input;
ObjectInspector output;
PrimitiveObjectInspector stringOI;
// 确定相关数据类型,map阶段和reduce阶段都会执行
// map阶段的参数与传入的参数有关
// reduce阶段的参数长度为一
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {
input = (PrimitiveObjectInspector)parameters[0];
}else {
stringOI = (PrimitiveObjectInspector)parameters[0];
}
output = ObjectInspectorFactory.getReflectionObjectInspector(String.class, ObjectInspectorOptions.JAVA);
return output;
}
// 自定义实现逻辑所需要的结构,以及迭代执行的方法
static class ConcatAgg implements AggregationBuffer{
String value = "";
void concat(String other) {
if (value.length() == 0) {
value += other;
}else {
value += "," + other;
}
}
}
// 获得一个新的缓冲对象,每个map调用执行一次
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
ConcatAgg concatAgg = new ConcatAgg();
reset(concatAgg);
return concatAgg;
}
// 帮助重置自定义结构的初始值
@Override
public void reset(AggregationBuffer agg) throws HiveException {
ConcatAgg concatAgg = (ConcatAgg)agg;
concatAgg.value = "";
}
// map阶段调用执行
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
// TODO Auto-generated method stub
ConcatAgg concatAgg = (ConcatAgg)agg;
if (parameters[0] != null) {
concatAgg.concat(input.getPrimitiveJavaObject(parameters[0]).toString());
}
}
// map阶段结束时的返回结果,如果无复杂的业务逻辑可以直接调用terminate方法
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
// map的合并阶段
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
if (partial != null) {
ConcatAgg result = (ConcatAgg)agg;
String partialValue = stringOI.getPrimitiveJavaObject(partial).toString();
ConcatAgg concatAgg = new ConcatAgg();
concatAgg.concat(partialValue);
result.concat(concatAgg.value);
}
}
// reduce阶段返回结果
// 如果逻辑中没有reduce阶段则直接在map阶段结束后调用
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
ConcatAgg concatAgg = (ConcatAgg)agg;
return concatAgg.value;
}
}
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) {
return new Evaluator();
}
}
UDTF:一行输入,多行输出
例:分割字符串
Split.java
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class Split extends GenericUDTF {
@Override
public void close() throws HiveException {
// TODO Auto-generated method stub
}
// 设置返回结果的列的个数以及相应的数据类型
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
List fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList();
// 返回的新列的字段名称
fieldNames.add("tag");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
// process中编写核心处理逻辑
// 通过参数列表获得到用户调用方法时传入的参数
@Override
public void process(Object[] objects) throws HiveException {
// 第一个参数代表待处理的字符串
String str = objects[0].toString();
// 第二个参数代表传入的分隔符
String[] values = str.split(objects[1].toString());
for (String value : values) {
// forward方法返回一行的数据
// 参数为数组,数组中元素的个数决定返回几列
forward(new String[] {value});
}
}
}
二、Sqoop安装
功能概述
主要用于在Hadoop(Hive)与传统的数据库(mysql、oracle…)间进行数据的传递,可以将一 个关系型数据库中的数据导入到HDFS(Hive)中,也可以将HDFS的数据导进到关系型数 据库中。
安装配置
-
解压缩安装文件
tar -zvxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
-
配置文件
-
sqoop-env.sh
文件位置:Sqoop安装目录下的conf文件夹(将sqoop-env-template.sh重命名为sqoop-env.sh)
需要在此文件中配置Hadoop家目录和Hive家目录
#Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/home/hadoopadmin/hadoop-2.7.1 #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/home/hadoopadmin/hadoop-2.7.1 #Set the path to where bin/hive is available export HIVE_HOME=/home/hadoopadmin/apache-hive-1.2.1-bin -
configure-sqoop
文件位置:Sqoop安装目录下的bin文件夹
封装应用需要进行注释configure-sqoop(bin)的135-147行,当装了zoopkeeper后打开144-147
目的:封装应用时调用后不会输出一些无用的信息
-
-
拷贝jar包
将hadoop-common-2.7.2.jar拷贝至sqoop的lib目录
cp $HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.2.jar $SQOOP_HOME/lib
sqoop通过数据连接获得基本信息,需要准备相应数据库的驱动jar包放在lib目录下
-
编辑环境变量
SQOOP_HOME=/home/bigdata/sqoop-1.4.7.bin
PATH=$PATH:$SQOOP_HOME/bin
export SQOOP_HOME
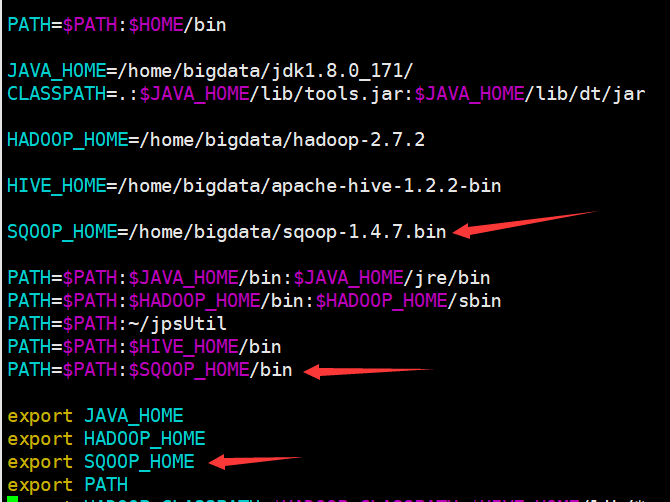
source .bash_profile
测试连接
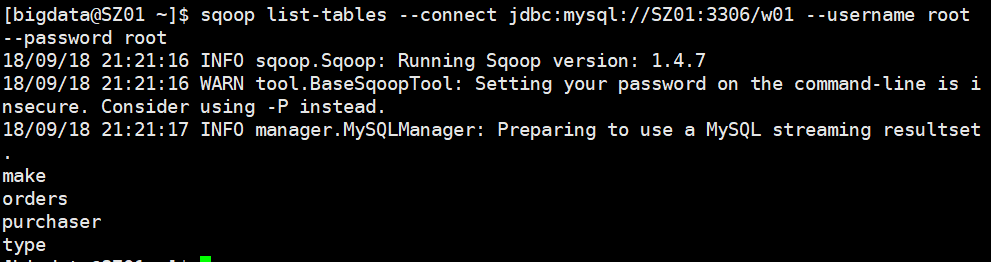
命令格式:sqoop后接连接数据库字符串,username后接连接数据库用户名,password后接连接数据库密码,list-databases展示数据库列表,list-table展示连接数据库下的所有表
sqoop list-databases --connect jdbc:mysql://SZ01:3306 --username root --password root

sqoop list-tables --connect jdbc:mysql://SZ01:3306/w01 --username root --password root
三、Sqoop基本操作
可以使用以下命令查看帮助
sqoop help
sqoop xxx --help
将MySQL表数据导入到HDFS中
单表导入,可以指定某几列,或用where筛选某些数据(需要使用引号),columns指定需要导入的列,table指定需要导入的表,delete-target-dir用于判断目标路径是否存在,存在则先删除,m用于指定最大mapTask个数,范围为1-4
sqoop import
--connect jdbc:mysql://SZ01:3306/test
--username {userName}
--password {password}
--columns {columnName,columnName,...}
--table {tableName}
--where '{condition}'
[--as-textfile]
[--delete-target-dir]
--target-dir {hdfsPath}
-m {maskNum}
导入到HDFS中时,目标文件夹不能已存在
#####将MySQL表数据导入到Hive中
多表导入,使用query参数导入查询生成的结果集(多表,需要使用引号),如果有where条件需要添加and $CONDITIONS
sqoop import
--connect jdbc:mysql://SZ01:3306
--username {userName}
--password {password}
--query '{sql}'
--hive-import
--hive-database {hiveDatabaseName}
--hive-table {hiveTableName}
[--hive-overwrite]
--target-dir {hdfsPath}
-m {maskNum}
四、Sqoop结合JavaWeb
#####目标需求
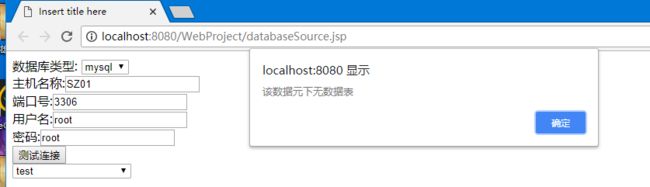
客户通过页面输入访问的端口号、用户名、密码获取数据库中的库信息,以下拉菜单方式展现,当选择了下拉菜单中的库时,又能显示该库中存在的表,如果表不存在则不显示并且弹窗告知用户该库中没有表。
#####编写代码
databaseSource.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
Insert title here
数据库类型:
主机名称:
端口号:
用户名:
密码:
databaseSource.js
$(function() {
$(".getDataBase").click(function() {
var method = "showDatabases";
var databaseType = $("select[name='databaseType']").val();
var hostName = $("input[name='hostName']").val();
var port = $("input[name='port']").val();
var name = $("input[name='name']").val();
var password = $("input[name='password']").val();
$.ajax({
url : "DataBaseServlet",
type : "post",
data : {
method : method,
databaseType : databaseType,
hostName : hostName,
port : port,
name : name,
password : password
},
dataType : "json",
success : function(data) {
var select = $("");
for (index in data) {
select.append("");
}
$(".databaseList").html("");
$(".databaseList").append(select);
}
})
})
$(".databaseList").on("change",".database",function() {
var method = "showTables";
var databaseName = $(this).val();
var databaseType = $("select[name='databaseType']").val();
var hostName = $("input[name='hostName']").val();
var port = $("input[name='port']").val();
var name = $("input[name='name']").val();
var password = $("input[name='password']").val();
$.ajax({
url : "DataBaseServlet",
type : "post",
data : {
method : method,
databaseType : databaseType,
hostName : hostName,
port : port,
name : name,
password : password,
databaseName : databaseName
},
dataType : "json",
success : function(data) {
if(data.length != 0){
var select = $("");
for (index in data) {
select.append("");
}
$(".dataTableList").html("");
$(".dataTableList").append(select);
}else{
$(".dataTableList").html("");
alert("该数据元下无数据表");
}
}
})
})
})
DataBaseServlet.java
import java.io.IOException;
import java.io.PrintWriter;
import java.util.ArrayList;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.sand.util.PropertiesUtil;
import com.sand.util.RemoteUtil;
import net.sf.json.JSONArray;
/**
* Servlet implementation class DataBaseServlet
*/
@WebServlet("/DataBaseServlet")
public class DataBaseServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public DataBaseServlet() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
String method = request.getParameter("method");
PropertiesUtil propertiesUtil = new PropertiesUtil("system.properties");
String sqoopBinHome = propertiesUtil.readPropertyByKey("sqoopBinHome");
String host = propertiesUtil.readPropertyByKey("hostName");
String userName = propertiesUtil.readPropertyByKey("hadoopUser");
String userPwd = propertiesUtil.readPropertyByKey("hadoopPwd");
// 连接数据库的类型
String databaseType = request.getParameter("databaseType");
// 连接数据库的主机名
String hostName = request.getParameter("hostName");
// 端口号
String port = request.getParameter("port");
// 数据库用户名
String name = request.getParameter("name");
// 数据库密码
String password = request.getParameter("password");
String jdbcUrl = "jdbc:" + databaseType + "://" + hostName + ":" + port + "/";
RemoteUtil remoteUtil = new RemoteUtil(host, userName, userPwd);
String cmd = "";
cmd += sqoopBinHome;
if("showDatabases".equals(method)) {
cmd +="/sqoop list-databases --connect " + jdbcUrl + " --username " + name + " --password " + password;
String result = remoteUtil.execute(cmd);
String jsonArray = JSONArray.fromObject(result.split("\n")).toString();
out.print(jsonArray);
out.close();
}else if("showTables".equals(method)) {
String databaseName = request.getParameter("databaseName");
jdbcUrl += databaseName;
cmd += "/sqoop list-tables --connect " + jdbcUrl + " --username " + name + " --password " + password;
String result = remoteUtil.execute(cmd);
if(!result.contains("Running Sqoop version: 1.4.7")) {
String jsonArray = JSONArray.fromObject(result.split("\n")).toString();
out.print(jsonArray);
out.close();
}else {
out.print(JSONArray.fromObject(new ArrayList()));
out.close();
}
}
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
system.properties
# 主机名
hostName=SZ01
# hdfs端口号
hdfsPort=8020
# 操作Hadoop软件用户名
hadoopUser=bigdata
# 操作Hadoop软件用户密码
hadoopPwd=bigdata
# Hadoop命令文件所在路径
hadoopBinHome=/home/bigdata/hadoop-2.7.2/bin
# Sqoop命令文件所在路径
sqoopBinHome=/home/bigdata/sqoop-1.4.7.bin/bin
# 用户文件根目录
userDataDir=/input/user
# 算法包所在路径
jarPath=/home/bigdata/mr/mapreduce.jar
# 单词计数主类
wordCount=com.sand.mr.master.WordCountMaster
# 流量统计主类
flowCount=com.sand.mr.master.FlowCountMaster
# 结果文件根目录
resultPath=/output/
PropertiesUtil.java
import java.io.IOException;
import java.util.Properties;
public class PropertiesUtil {
private String fileName;
private Properties properties = new Properties();
public PropertiesUtil(String fileName) {
this.fileName = fileName;
open();
}
private void open() {
try {
properties.load(Thread.currentThread().getContextClassLoader().getResourceAsStream(fileName));
} catch (IOException e) {
e.printStackTrace();
}
}
public String readPropertyByKey(String key) {
return properties.getProperty(key);
}
}
运行效果
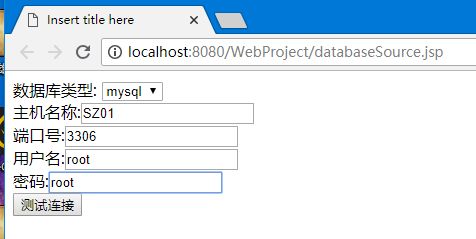
输入所需信息后点击测试连接
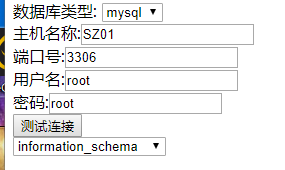
选择要展示的数据库中的表


当库中无表时弹窗告知用户