MongoDB深究之ObjectId
继上一篇《MongoDB初窥》之后,想必大家对自动生成的主键objectId有所好奇,为什么会是一个24位的字符串。今天,就对objectId的生成原理做一次比较深入的挖掘。
一、 ObjectId的组成
首先通过终端命令行,向mongodb的collection中插入一条不带“_id”的记录。然后,通过查询刚插入的数据,发现自动生成了一个objectId,4e7020cb7cac81af7136236b。具体操作如图1所示。
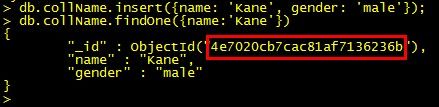
图1 插入/查询数据
“4e7020cb7cac81af7136236b”这个24位的字符串,虽然看起来很长,也很难理解,但实际上它是由一组十六进制的字符构成,每个字节两位的十六进制数字,总共用了12字节的存储空间。相比MYSQL int类型的4个字节,MongoDB确实多出了很多字节。不过按照现在的存储设备,多出来的字节应该不会成为什么瓶颈。不过MongoDB的这种设计,体现着空间换时间的思想。官网中对ObjectId的规范,如图2所示。

图2 官网对ObjectId的规范
1) Time
时间戳。将刚才生成的objectid的前4位进行提取“4e7020cb”,然后按照十六进制转为十进制,变为“1315971275”,这个数字就是一个时间戳。通过时间戳的转换,就成了易看清的时间格式,如图3所示。
![]()
图3 时间戳的转换
2) Machine
机器。接下来的三个字节就是“7cac81”,这三个字节是所在主机的唯一标识符,一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器hash值,确保在分布式中不造成冲突,这也就是在同一台机器生成的objectId中间的字符串都是一模一样的原因。
3) PID
进程ID。上面的Machine是为了确保在不同机器产生的objectId不冲突,而pid就是为了在同一台机器不同的mongodb进程产生了objectId不冲突,接下来的“af71”两位就是产生objectId的进程标识符。
4) INC
自增计数器。前面的九个字节是保证了一秒内不同机器不同进程生成objectId不冲突,这后面的三个字节“36236b”是一个自动增加的计数器,用来确保在同一秒内产生的objectId也不会发现冲突,允许256的3次方等于16777216条记录的唯一性。
总的来看,objectId的前4个字节时间戳,记录了文档创建的时间;接下来3个字节代表了所在主机的唯一标识符,确定了不同主机间产生不同的objectId;后2个字节的进程id,决定了在同一台机器下,不同mongodb进程产生不同的objectId;最后通过3个字节的自增计数器,确保同一秒内产生objectId的唯一性。ObjectId的这个主键生成策略,很好地解决了在分布式环境下高并发情况主键唯一性问题,值得学习借鉴。
二、 源码分析
MongoDB可以通过自身的服务来产生objectId,也可以通过客户端的驱动程序来生成objectId。虽然objectId是轻量级的,但如果全部在服务端生成肯定会花费一点开销。所以,能从服务器端转移到客户端驱动程序完成的,就尽量转移到客户端来完成,减少服务器端的开销。我们来看一下,客户端的驱动程序是如何来生成objectId的。
1、下载mongodb java driver源码。 (https://github.com/mongodb/mongo-java-driver/downloads)
2、分析ObjectId.java
驱动源码的org.bson包下找到ObjectId.java,进行分析。默认构建的objectId代码如下代码所示,objectId主要由_time,_machine和_inc组成
构建objectId
public class ObjectId implements Comparable
final int _time;
final int _machine;
final int _inc;
boolean _new;
public ObjectId(){
_time = (int) (System.currentTimeMillis() / 1000);
_machine = _genmachine;
_inc = _nextInc.getAndIncrement();
_new = true;
}
……
}
1) _time
直接由System.currentTimeMillis()/1000计算得出的时间戳。
2) _machine
由机器码(machinePiece)和进程码(processPiece)组成,如代码所示。它这里组成方式是:首先,通过NetworkInterface这个类,获取机器的所有网络接口信息(如图4所示),并将得到的字符串取散列值,就得到了机器码;然后通过RuntimeMXBean.getName()方法获取pid,再拼装classloaderid,得到进程码;最后将机器码和进程码进行位或运算得到_machine。不过这里生成的_machine是十进制的,需转成十六进制。

图4 本地调试时的网络接口部分信息
机器码和进程码的生成
private static final int _genmachine;
static {
try {
final int machinePiece;
{
StringBuilder sb = new StringBuilder();
Enumeration
while ( e.hasMoreElements() ){
NetworkInterface ni = e.nextElement();
sb.append( ni.toString() );
}
machinePiece = sb.toString().hashCode() << 16;
LOGGER.fine( "machine piece post: " + Integer.toHexString( machinePiece ) );
}
final int processPiece;
{
int processId = new java.util.Random().nextInt();
try {
processId = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().hashCode();
}catch ( Throwable t ){
}
ClassLoader loader = ObjectId.class.getClassLoader();
int loaderId = loader != null ? System.identityHashCode(loader) : 0;
StringBuilder sb = new StringBuilder();
sb.append(Integer.toHexString(processId));
sb.append(Integer.toHexString(loaderId));
processPiece = sb.toString().hashCode() & 0xFFFF;
LOGGER.fine( "process piece: " + Integer.toHexString( processPiece ) );
}
_genmachine = machinePiece | processPiece;
LOGGER.fine( "machine : " + Integer.toHexString( _genmachine ) );
}catch ( java.io.IOException ioe ){
throw new RuntimeException( ioe );
}
}
3) _inc
自增数是通过AtomicInteger的getAndIncrement()方法获取,它能保证每次得到的值是一个递增并不重复的值。
三、 更多参考
1、 http://www.mongodb.org/display/DOCS/Object+IDs
原文地址:http://www.cnblogs.com/xjk15082/archive/2011/09/18/2180792.html