Hadoop生态圈之分布式环境搭建
- 0、服务器配置
- 0.1、服务器磁盘阵列(分区)
- 0.2、centos系统安装
- 0.3、编码
- 1、安装模式
- 1.1、单机模式
- 1.2、伪分布模式
- 1.3、完全分布式模式
- 2、环境搭建
- 3、添加新节点
- 4、初步实战
- 5、数据误删除恢复
- 5.1、回收站恢复
- 5.2、快照恢复
- 5.3、编辑日志恢复
- 6、常见问题
0、服务器配置
0.1、服务器磁盘阵列(分区)
Dell服务器做磁盘阵列
3个及3个以上磁盘适合做raid5
0.2、centos系统安装
centos安装 / Installation of CentOS 7.3 Guide
0.3、编码
Centos7 下中文显示乱码
locale # 查询当前编码安装编码
yum -y groupinstall chinese-support修改配置文件vim /etc/locale.conf
LANG=”XXXX” 改为LANG=”zh_CN.UTF-8”解决 Centos7 下中文显示乱码
Hadoop分布式环境添加一个新的数据节点
1、安装模式
hadoop有三种安装模式:
1.1、单机模式
Hadoop的默认模式,当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
1.2、伪分布模式
配置3个xml文件,配置ssh免密登陆;本次在本机实战使用的就是伪分布模式。
1.3、完全分布式模式
这种模式一般公司用,配置主子节点,包括之间的免密登陆,需要硬件支持
2、环境搭建
学习一门新的技术,最入门基础的以及最重要的就是环境的搭建,下面简单罗列一下:
1、去官方下载 http://hadoop.apache.org/releases.html,我选择了2.7.4 binary版本
2、下载完成后放到本地磁盘下解压即可
3、配置macOS10.12.6环境变量.bash_profile,默认JAVA_HOME原先已经配置好了,比如这样:
HADOOP_HOME=/Users/diyangxia/MyConfigure/hadoop-2.7.4Path中添加
$HADOOP_HOME/bin:$HADOOP_HOME/sbin:以及
export HADOOP_HOME
export PATH输入命令使环境变量生效
source /etc/profile
或者
source ~/.bash_profile4、配置ssh免登录
首先要去开启远程共享,在系统偏好设置,共享,选中远程登陆复选框,允许所有用户。
然后配置生成dsa密钥,就跟生成git的密钥步骤差不多,配置这个完成后,每次登陆hadoop或者ssh localhost的时候就不用输入密码了。
5、配置hadoop的xml文件
core-site.xml,配置核心site文件,在/hadoop2.7.4/etc/hadoop目录下,其中第二个配置的temp文件夹可以原先不存在,会自动创建
<configuration>
<property>
<name>fs.trash.intervalname>
<value>1440value>
<description>Number of minutes between trash checkpoints.
If zero, the trash feature is disabled.
description>
property>
<property>
<name>fs.defaultFS name>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/Users/diyangxia/MyConfigure/hadoop-2.7.4/tempvalue>
property>
configuration>hdfs-site.xml,目录同上,这里面有两个路径也可以原先不存在,会自动创建,配置可能不需要这么项,但多一项毕竟保险。
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname> <value>file:/Users/diyangxia/MyConfigure/hadoop-2.7.4/tmp/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/Users/diyangxia/MyConfigure/hadoop-2.7.4/tmp/hdfs/datavalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>localhost:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>mapred.xml,目录同上
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>yarn-site.xml,目录同上
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>20480value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>1value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>2048value>
property> 还有最后一个hadoop-env.sh,这里面配置好两个环境变量,应该是这么说的
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
export HADOOP_CONF_DIR=/Users/diyangxia/MyConfigure/hadoop-2.7.4/etc/hadoop
正常启动成功后,就会打开以下两个界面
http://localhost:50070/ hdfs管理界面
http://localhost:8088/ yarn管理界面
以上就基本完成了hadoop的开发环境配置,如果有其他小坑小洼,自行百度谷歌都可以解决,不能解决的发出来大家一起交流。
3、添加新节点
1、安装好系统,比如CentOS 7.1.1503
2、安装插件:
yum install -y vim wget net-tools3、更改别名,进入/etc/hostname 添加新的别名;原来的内容是:localhost.localdomain
4、配置ssh免密登录
ssh-keygen -t rsa连续回车,查看本机ip地址
ip addr就是把生成好的公钥先复制到主节点,然后在主节点把子节点的公钥内容追加到authorized_keys文件中,最后把这个文件再复制到子节点替换原有的即可。
5、在主节点的/etc/hosts 文件中,追加新的节点名映射关系,比如192.168.1.10 datanode5
6、添加其他子节点对该子节点的ssh免密登录
7、修改namenode的配置文件 /hadoop/etc/hadoop/slaves ,添加新节点别名
8、复制主节点的hadoop和java目录到子节点同目录下,使用scp -r 文件夹目录 命令,如果子节点已有java,可以暂时忽略,然后配置环境变量
9、启动dfs脚本时报错,找不到jdk以及其他datanode子节点;首先在该子节点的/etc/hosts文件里添加主节点以及其他子节点的映射,其实可以直接把主节点的同路径文件拷过来替换掉即可。
9、重启集群,启动单个节点报错,授权失败,已经添加了ssh互相信任。 单独启动该节点的datanode和tasktracker,动态将新增节点加入
启动datanode:hadoop-daemon.sh start datanode启动
启动nodemanager:yarn-daemon.sh start nodemanager
启动TaskTracker:hadoop-daemon.sh start TaskTracker
10、运行start-balancer.sh进行数据负载均衡,目的是为了将其他节点的数据分担一些到新节点上来,比较开销时间
•还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandWidth 67108864即可
•默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%
•然后启动Balancer,sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可
引用这里:http://www.cnblogs.com/ggzone/p/5094497.html
4、初步实战
任务内容:执行自带案例中的wordcount
先来看一下wordcount的源码,来源于官方文档中,https://wiki.apache.org/hadoop/WordCount
想查看wotdcount源码等可以直接用搜索引擎搜索或者点击上面等链接,我是不敢把它放在博文里,一放就崩溃,写了好久的代码一崩溃又没了,还好今天有另一个好消息在支撑着我:北马中签了。哈哈哈!!!!!!
第一步:环境搭建,见上面文章
第二步:准备文件,在当前目录下准备一个写有6个单词的txt文件
echo "Hello Hadoop" > xm.txt
echo "Hello World" > xm.txt
echo "Hello Java" > xm.txt第三步:上传文件(先新建目录,再上传文件)
hdfs dfs -mkdir /input
hdfs dfs -ls /
hdfs dfs -put xm.txt /input第四步:执行wordcount(注意输出文件夹不能预先存在)
hadoop jar MyConfigure/hadoop2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-examples2.7.4.jar wordcount /input /output
Fifth:look result
hdfs dfs -cat /output/part-r-00000result below
Hadoop 1
Hello 3
Java 1
World 1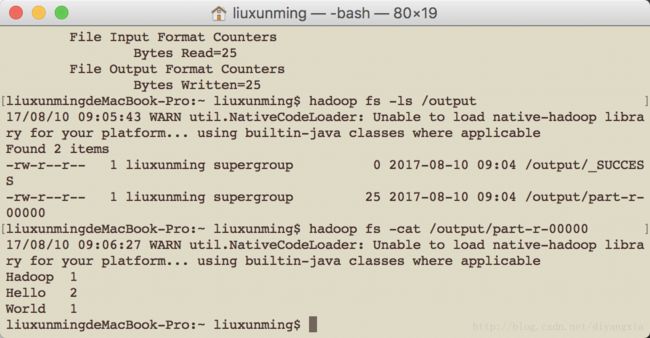
课题:统计数据来源中访问csdn.net的用户及访问次数
5、数据误删除恢复
参考这里
三种恢复 HDFS 上删除文件的方法
5.1、回收站恢复
配置了开启回收站就好
<property>
<name>fs.trash.intervalname>
10080
Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.
property> 5.2、快照恢复
创建快照,删除文件
hadoop dfsadmin -allowSnapshot /user/root/imporData
hadoop fs -createSnapshot /user/root/imporData important-snapshot
hdfs dfs -rm -r /user/root/imporData/test.txt恢复文件
hdfs dfs -cp /user/root/imporData/.snapshot/important-snapshot/test.txt /user/root/imporData5.3、编辑日志恢复
这种方法其实跟 Hadoop错误之namenode宕机的数据恢复 这篇文章的解决方法基本类似,这种解决方法的结果具有不确定性,就是不一定能恢复,恢复的也不一定完全。
首先停掉集群
然后找到名字类似 edits_inprogress_0000000000000000387 这个是编辑日志文件,一般位于tmp/hdfs/name/current 目录下
执行解析这个文件的命令
hdfs oev -i edits_inprogress_0000000000000000387 -o edits_inprogress_0000000000000000387.xml反解析
hdfs oev -i edits_inprogress_0000000000000000387.xml -o edits_inprogress_0000000000000000387 -p binary然后重启看缘分
6、常见问题
1、使用intelj idea打包jar
选择project structure—artifacts然后点击添加按钮选择下拉框jar—》from modules with dependencies,弹框中配置main class,jar files from libraries选择第二项copy to the output directory and link via manifest,关于mainfest.mf文件请自定义路径到项目的resources文件夹下,否则会出错。点击ok完成,选择build目录下build arrifacts,就会在项目目录下生成jar包目录,如果要重新生成其他mainclass的jar包,需要把原来生成的jar以及配置的jar删掉,重新来过
2、打包过程中如果出现manifest.mf already exists in vfs
删除已经存在的MANIFEST.MF文件夹,重新build
3、执行hadoop jar如果一直卡在running job动不了的话
每个docker分配的内存和CPU资源太少,不能满足Hadoop和Hive运行所需的默认资源需求;需要在yarn-site中添加cpu和内存分配,具体配置见上面贴出的代码。
4、hive导出到文件
hive -e "select * from aaa" >> local/aaa.txt